HTK搭建大词汇量连续语音识别系统(四)
语言学模型训练
(1)数据准备
使用python把timit中train目录下的txt文本搜集在一个文本里,格式如下:
<s> SHE HAD YOUR DARK SUIT IN GREASY WASH WATER ALL YEAR </s>
<s> DON'T ASK ME TO CARRY AN OILY RAG LIKE THAT </s>
<s> EVEN THEN IF SHE TOOK ONE STEP FORWARD HE COULD CATCH HER </s>
<s> OR BORROW SOME MONEY FROM SOMEONE AND GO HOME BY BUS </s>
<s> A SAILBOAT MAY HAVE A BONE IN HER TEETH ONE MINUTE AND LIE BECALMED THE NEXT </s>
<s> THE EMPEROR HAD A MEAN TEMPER </s>
<s> HOW PERMANENT ARE THEIR RECORDS </s>
<s> THE MEETING IS NOW ADJOURNED </s>
<s> CRITICAL EQUIPMENT NEEDS PROPER MAINTENANCE </s>
<s> TIM TAKES SHEILA TO SEE MOVIES TWICE A WEEK </s>
<s> SHE HAD YOUR DARK SUIT IN GREASY WASH WATER ALL YEAR </s>
测试用的文本一样。
(2)模型训练
a. 建立空表:LNewMap 0f WFC Holmes empt.wmap
b. 统计文本语料词频信息:
LGPrep -T 1 -a 100000 -b 200000 -d holmes.0 -n 4 “timit” empty.wmap -S train/train.txt
如果train.txt这种文件比较多,用-S train.scp,train.scp存放txt的路径
可以使用命令查看统计信息:
LGList holmes.0/wmap holmes.0/gram.0
c. 对统计文件排序并去除重复字串:
LGCopy -T 1 -b 200000 -d holmes.1 holmes.0/wmap holmes.0/gram0
结果如图:

d. 过滤屌字典中不存在的词:
LGCopy -T 1 -o -m lm_timit/ timit.wmap -b 200000 -d lm_ timit -w timit.wlist holmes.0/wmap holmes.1/data.0

e. 生成语言学模型ugw文件
生成一元语言学模型,命令:
LBuild -T 1 -n 1 lm_timit/timit.wmap lm_timit/ug holmes.1/data.0 lm_timit/data.0
生成结果与界面:
\data\ ngram 1=4898 \1-grams: -3.8220 !!UNK -4.6002 </s> -99.9900 <s> -1.6652 A -3.7551 ABBREVIATE -4.6002 ABIDES -4.2992 ABILITY -4.1231 ABLE -3.7551 ABLY -3.7551 ABOLISH -4.6002 ABORIGINE -4.6002 ABORIGINES

生成二元语言学模型,命令:
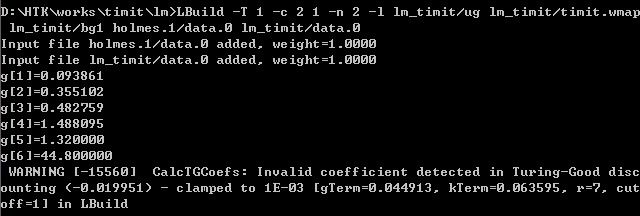
LBuild -T 1 -c 2 1 -n 2 -l lm_timit/ug lm_timit/timit.wmap lm_timit/bg1 holmes.1/data.0 lm_timit/data.0
生成结果与界面如下,有个警告:
BIGRAM: method Katz, cutoff 1
coef[7]: 0.000000 0.311304 0.447630 0.990000 0.990000 0.990000 0.001000
\data\
ngram 1=4898
ngram 2~3129
\1-grams:
-3.8220 !!UNK
-4.6002 </s>
-99.9900 <s>
-1.6652 A -0.1047
-3.7551 ABBREVIATE +0.0100
-4.6002 ABIDES
-4.2992 ABILITY -0.1507
-4.1231 ABLE -0.2465
-3.7551 ABLY -0.0004
同样的,生成三元语言学模型:
LBuild -T 1 -c 2 1 -n 3 -l lm_timit/bg1 lm_timit/timit.wmap lm_timit/tg1 holmes.1/data.0 lm_timit/data.0
生成结果与界面如下,有两个警告:
TRIGRAM: method Katz, cutoff 1 coef[7]: 0.000000 0.277236 0.990000 0.990000 0.990000 0.990000 0.001000 \data\ ngram 1=4898 ngram 2~3129 ngram 3~2677 \1-grams: -3.8220 !!UNK -4.6002 </s> -99.9900 <s> -1.6652 A -0.1047 -3.7551 ABBREVIATE +0.0100 -4.6002 ABIDES -4.2992 ABILITY -0.1507 -4.1231 ABLE -0.2465

f. 语言学模型转换为图结构,可以被HVite所使用
将二元语言学模型转换为图结构,在timit.wlist开头加入!!UNK,然后使用其命令:
HBuild -n lm_timit/bg1 -s "<s>" "</s>" timit.wlist bigram.net
生成的bigram.net形式如下:
VERSION=1.0 N=4899 L=12923 I=0 W=!NULL I=1 W=!!UNK I=2 W=</s> I=3 W=<s> I=4 W=A I=5 W=ABBREVIATE I=6 W=ABIDES I=7 W=ABILITY I=8 W=ABLE
复制dict3为dict6,在dict6中开头加入:
!!UNK sil !NULL sil </s> sil <s> sil
和之前测试一样,使用HVite命令生成识别结果:
HVite -T 1 -H hmms/hmm15/macros -H hmms/hmm15/hmmdefs -s 10.0 -S test/test.scp -I results/recout_lm.mlf -w dict/bigram.net -C config/config2 -t 250.0 -n 4 20 -q Atal -z lat dict/dict6 lists/tiedlist
完成后使用HResults进行评测:
HResults -I test/testwords.mlf lists/tiedlist results/recout_lm.mlf
还是注意:testwords.mlf的路径应该和recout_lm.mlf的路径一致,不一致就用python修改一下。结果如下:
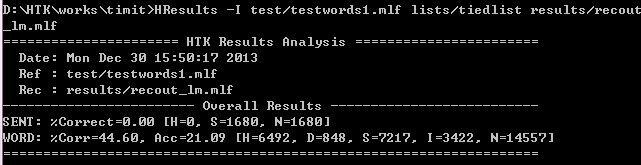
比之前的要好点了。。。