Keyspace中的paxos
1. Keyspace
Keyspace是一款基于Paxos的开源Key-Value的数据库,底层存储基于BerkelyDB,Keyspace的核心功能是在BerkelyDB之上添加了一致层,保证每个节点的数据完全一致。Keyspace基于Master-Slave模式,所有的写均有Master承担,并通过paxos一致传播到slave,读可以根据基本路由到master或slave。因此,当master出现宕机或不可访问时,会存在一套master的选举机制,在keysapce中成为PaxosLease算法。默认,master拥有Lease的时间是7秒,但只要master没有crash可以继续持有。
要指出的是,因为基于master,所有keyspace对paxos实现进行了改造,把2 phase的paxos改造为1 phase。
2. Keyspace配置
Keyspace提供了众多的端口和服务,具体如下:
| Item | Port |
|---|---|
| HTTP服务 | 8080 |
| 非HTTP客户端 | 7080 |
| 内部 数据复制 | 10000 |
| master lease | 10001 |
| catch up | 10002 |
Catch UP是指节点长时间离开后又加入的情况
3. Keyspace架构
Keysapce的基本架构是在BerkelyDB之上加了一层paxos,其图如下:
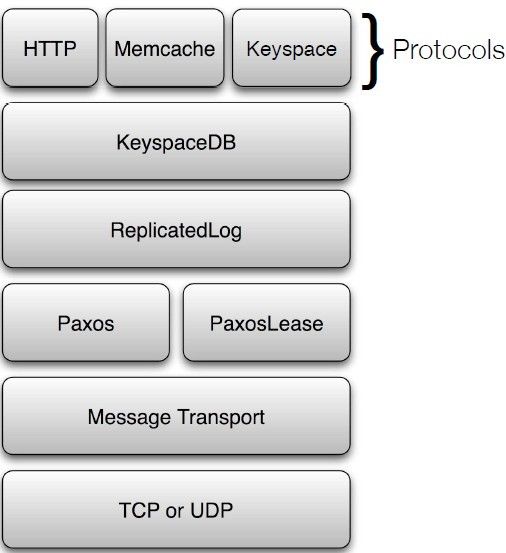
Paxos与PaxosLease同属于Paxos层,PaxosLease倾向于解决Leader选举问题,Paxos主要是解决数据一致性,我们重点放在Paxos上。
在Paxos的实现上,Keysapce还有几个描述更细致的组件:
- KeyspaceDB:对外部协议的一致性操作接口,隐藏了对Paxos和BerkelyDB的调用。
- ReplicatedLog:逻辑上的DB Log,封装了Paxos的一致性
- PaxosProposer:Paxos算法中的提案者
- PaxosAcceptor:Paxos算法中的acceptor
- PaxosLearn:Paxos算法中的Learn
在Keysapce中的每个节点都集Proposer、Acceptor、Learn三种角色于一身,有ReplicatedLog统一协调。
另,Keyspace使用的是TCP协议,其他非核心模块、功能则不再介绍。
4.Paxos实现
Keyspace采用了基于Master的Paxos算法,只要Master没有crash,所有的写请求均有Master上的proposer进行提案,并一致性地写到所有的slave。因为Master的存在,Keyspace把传统paxos算法的prepare、accept两个阶段,简化为仅有prepare的1个阶段,但keyspace对prepare阶段的两个过程进行了概念上的重新定义:
- propose:master提出proposal
- prepare resposne:acceptor对proposer的response
如果因为网路延迟或其它原因导致master提交的proposal被拒,则master需要提高proposal的编号继续提交,此时称为:
- prepare:master提供编号后继续提交proposal
- prepare response:对应的response
以前paxos算法中的proposal是个抽象的概念,但在Keyspace中是非常具体的,就是Key-value对。那paxos是如何保证一致性的呢?每次用户提交Key-value,Keyspace都进行下面流程:
- ReplicatedLog把接收到的Key-Value传递给Master Proposer
- Master给当前的(K,V)分配paxosID即instance id,并作为propose消息发送给其他的Node
- 之前其他Node的多数派都响应了accept消息,Master便把该(K,V)连通paxosID一起发送给所有的Learn(也是其他Node)
- Learn在接收到Master的消息后,会检查消息中的paxosID之前所有的paxosID是否已经学习过了,即保证(K,V)要按顺序执行,不能跳号。如果之前的均已学习过了,则把当前paxosID对应的(K,V)持久化到BerkelyDB;否则Learn要请求Master学习之前的paxosID对应的消息。
按编号顺序学习消息是Keyspace保证一致性复制的核心。我们在详细说明下4的过程,在Learn收到消息(msg)后要检查:
- 如果msg.paxosID==local.paxosID+1,这直接执行消息中的(K,V)
- 如果local.paxosID < msg.paxosID,则需首先学习[local.paxosId+1,msg.paxosId-1]对应的(K,V),然后在执行msg.paxosID对应的(K,V)已保证一致性,这个过程称为跳号
为了节省空间,master会缓存一部分已经发送的paxosID,也即最新数据,比如为[minPaxosId,maxPaxosId]:
- 在Master收到跳号请求时,要查询Master本地缓存中已经发送过的paxosID:
- 如果minPaxosId<=msg.paxosId<=maxPaxosId,则直接从缓存中取出
- 否则Master回应Learn,指示其应该进行catch up,catch up的意思是需要从master上传输大量数据,有可能是全部数据,以保证learn与master一致。
- 在Learn收到catch up消息后,立即启动catch up过程,把Master上的数据全复制过来,从而保证了一致性
持久化
Keyspace无论是对paxosID的缓存还是最终数据,都是持久化到了BerkelyDB,这就保证了Node重启后算法的正确性。
容错
Keysapce做了很好的持久化,并充分相信BerkelyDB,可以解决网络、宕机等众多失败,但对BerkelyDB失败的情况是无法处理的,在实际中可以参考其catch up实现
问题
Keyspace的特点是所有的写都经过Master,所有的Node数据都与Master保持一致,但在实际中,需要的是动态分片、复制,而不是所有的节点数据都完全一致,因此跟Keyspace宣称的一样,它的目标只是做一个分布式底层,而不是终端产品。
5. Master选举
很显然,还有一个要解决的问题是Master宕机后如何选择新的Master,请参考:http://blog.csdn.net/chen77716/archive/2011/03/21/6265394.aspx
6. 疑问
在Keyspace对Paxos算法进行大刀阔斧地改造后,我们不仅要问这还是paxos算法吗?不考虑Master选举,这明明就是一个有Master来保证的一致性问题。
的确是的,但因为有网络延迟、节点重启、磁盘失败等诸多情况,如果没有多数派的投票机制,仅靠Master还是很难保证一致性,尤其是错误情况下的正确性,因此,改造后的还是paxos算法,Google Chubby的人曾说,任何分布式一致性算法都是paxos的特例,这也算是特例之一。
其实原生的Paxos算法很难不加任何改造就在工程中实现,因为其有性能问题,这一点微软的人也说过。所以,不必在乎是否是血统纯正的paxos算法,只要把握住要领灵活应用即可,paxos不是有形的剑,而是无形的气,看你如何驾驭它,而不是被它驾驭。