hadoop环境搭建总结
最近一段时间在看Hadoop The Definitive Guide, 3rd Edition.pdf,学习hadoop,个人想不能总看书,不实践呀,于是准备搭建一套开发环境,果然遇到很多问题,最终调试出了运行结果,在此记录。
我实践的过程比较坎坷,分别尝试了centos,Ubuntu,windows下的Eclipse的hadoop插件,都加载成功,但是windows下的示例没有运行成功。下面详细说明
参考Hadoop The Definitive Guide, 3rd Edition.pdf附录A,先下载hadoop:http://hadoop.apache.org/common/releases.html,我下载的版本是2.6.4。解压后放到/usr/local/下,我个人安装的程序都在这个目录下。但是java和Eclipse都是系统自带的或者yum安装,都不在这个目录下。
设置JAVA_HOME,java是系统自带的,java的安装你可以去网上搜一下,或者按照下面的方法,也可以找到
zhang@oradt:/etc/alternatives$ java -version java version "1.7.0_95" OpenJDK Runtime Environment (IcedTea 2.6.4) (7u95-2.6.4-0ubuntu0.14.04.1) OpenJDK 64-Bit Server VM (build 24.95-b01, mixed mode) zhang@oradt:/etc/alternatives$ which java /usr/bin/java zhang@oradt:/etc/alternatives$ ll /usr/bin/java lrwxrwxrwx 1 root root 22 二月 16 16:42 /usr/bin/java -> /etc/alternatives/java* zhang@oradt:/etc/alternatives$ ll /etc/alternatives/java lrwxrwxrwx 1 root root 46 二月 16 16:42 /etc/alternatives/java -> /usr/lib/jvm/java-7-openjdk-amd64/jre/bin/java* zhang@oradt:/etc/alternatives$
修改~/.bashrc,设置环境变量,添加到最后即可,添加完成后,source一下生效
export JAVA_HOME="/usr/lib/jvm/java-7-openjdk-amd64" export HADOOP_INSTALL="/usr/local/hadoop-2.6.4" export PATH=$PATH:$HADOOP_INSTALL/bin:$HADOOP_INSTALL/sbin
接下来你应该可以运行hadoop了,先查一下版本,接下来按照附录上的配置文件修改配置,调试过程中,我作了一些修改,配置如下:
core-site.xml,下面的9000端口在配置Eclipse的时候有用到。
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost/</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.80.202:9000/</value> </property> </configuration>
hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
mapred-site.xml
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:8021</value> </property> </configuration>
yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.address</name> <value>localhost:8032</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce.shuffle</value> </property> </configuration>
按照资料上讲的,ssh localhost的时候不能输入密码,所以要使用密钥登录,使用下面两条命令;
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
下面是一系列的hadoop命令,格式化节点,启动,关闭守护进程等等,我直接使用的yarn,未找到mapred.sh,据说这个脚本用到客户端了,我认识还比较浅,不清楚如何启动这个本地的。
hadoop namenode -format start-dfs.sh start-yarn.sh stop-dfs.sh stop-yarn.sh
到此,你可以查看一下监听的各个端口,也可以访问网址localhost:50070和localhost:8088,查看运行状态。
上面这个步骤在centos和Ubuntu下一次性配置都是成功的,比较简单,但是还没有用到任何map,reduce实际运行的内容,下一步配置Eclipse开发环境才是重点。
我的Eclipse也是系统自带的,先找一下Eclipse的安装目录,如果通过yum和apt-get安装的,一般在/usr/lib(64)下,实在找不到可以使用find / -name plugins|grep eclipse查找。接下来就是把hadoop的Eclipse插件放到plugins目录下。
网上应该能下到不少hadoop的eclipse插件版本,我认为最权威的应该还是git托管的那个,地址是:https://github.com/winghc/hadoop2x-eclipse-plugin,这里边不仅有源码,还有几个编译好的jar包可以使用,但是最高版本是2.6.0,开始的时候我使用这个2.6.0版本的jar包,放入plugins文件夹,Eclipse不识别,我以为是jar包不能兼容,或者编译的版本不对,我尝试了各种方法重新编译这个jar包,但是都以失败告终,无论实在centos,Ubuntu,还是windows,原因貌似是Eclipse少什么包,出大量的编译错误,因此,我尝试重新安装Eclipse。到最后,我也没编译通过这个插件。
安装Eclipse的方法我也尝试了几种,最后成功的是apt-get,将hadoop-eclipse-plugin-2.6.0.jar放到plugins目录,在命令行下使用eclipse命令启动后,竟然出现了DFS Locations,说明插件加载成功呀。
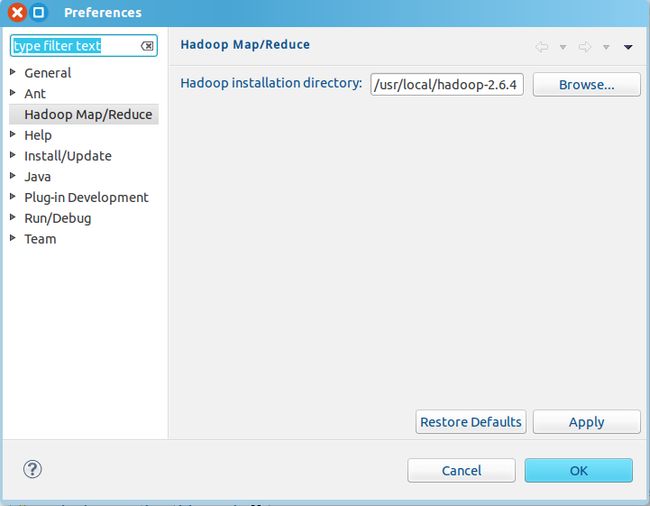
接下来按照网上的步骤, 配置hadoop,Window->Preference
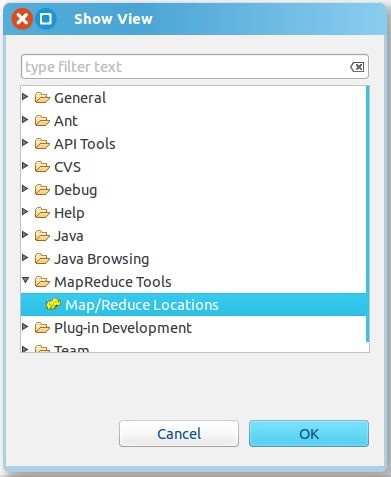
Window->Show View -> Others -> MapReduce Tools ->Map/Reduce Locations
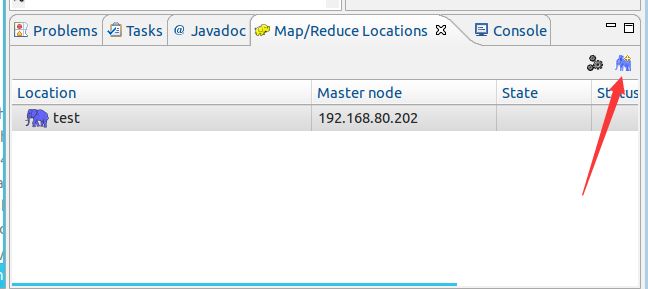
添加Locations
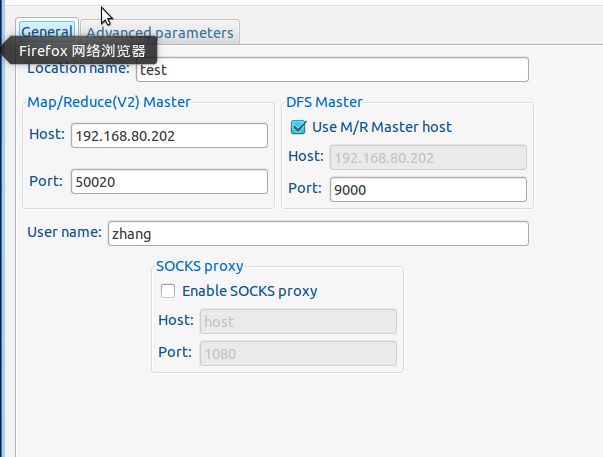
第一个端口使用的默认的50020,第二个是前面配置的9000,这个地方我使用的IP地址,见前面的配置,前面的fs.defaultFS配置为localhost的话,在windows系统下连接192.168.80.202是不成功的。
如果正常的话,这个地方展开是没有错误的。文件目录结构是使用命令新建的,hdfs dfs -mkdir -p input,这个命令会在/user/你的用户名/ 目录下新建一个input目录,hadoop fs -put intput1.txt input,这个命令是上传文件到input目录下。
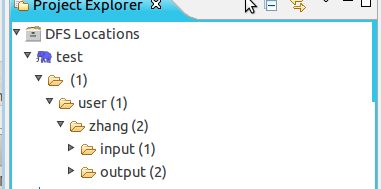
到此环境算是搭建好了。
下面是新建项目了:
File->New->Others...->

添加map和reduce类
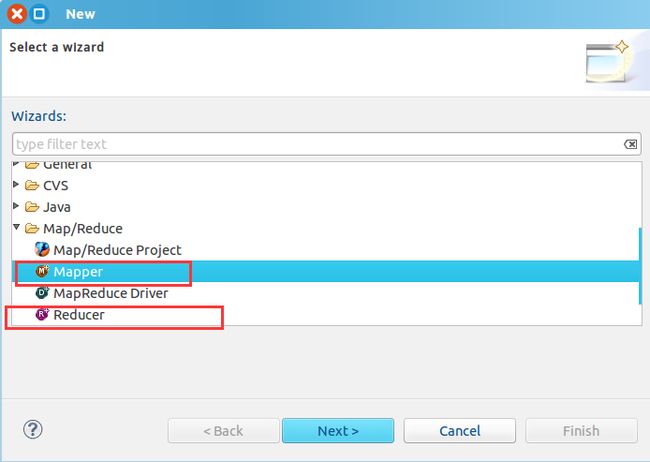
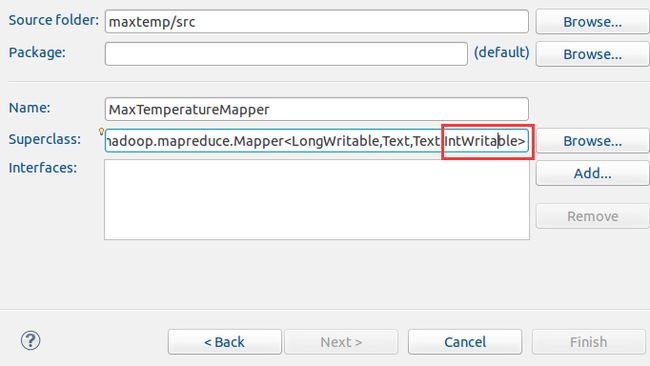
Mapper类注意父类的最后一个参数是IntWriteable类型
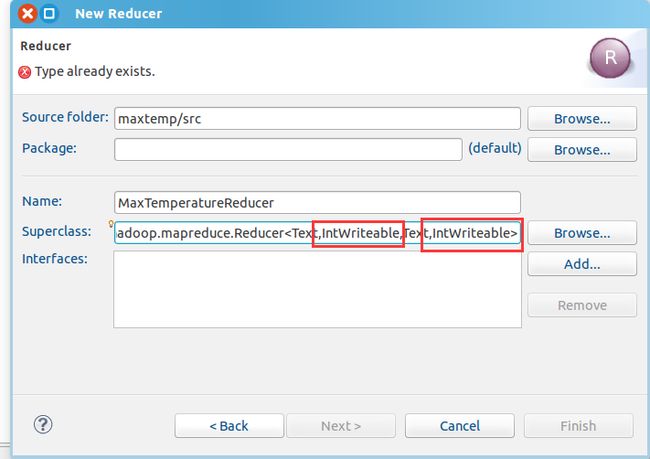
Reducer类注意第二个输入参数和第四个输出参数为IntWriteable类型
最后再添加一个MaxTemperature类,这3个类的详细内容,建议还是读读书吧。
MaxTemperatureMapper.java
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MaxTemperatureMapper extends
Mapper<LongWritable, Text, Text, IntWritable> {
private static final int MISSING = 9999;
//private static Logger logger = Logger.getLogger(MaxTemperatureMapper.class);
public void map(LongWritable ikey, Text ivalue, Context context)
throws IOException, InterruptedException {
String line = ivalue.toString();
System.err.println(line);
String year = line.substring(15, 19);
int airTemperature;
if (line.charAt(87) == '+') { // parseInt doesn't like leading plus signs
airTemperature = Integer.parseInt(line.substring(88, 92));
} else {
airTemperature = Integer.parseInt(line.substring(87, 92));
}
String quality = line.substring(92, 93);
if (airTemperature != MISSING && quality.matches("[01459]")) {
context.write(new Text(year), new IntWritable(airTemperature));
}else{
context.write(new Text(year), new IntWritable(0));
}
}
}
MaxTemperatureReducer.java
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MaxTemperatureReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text _key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
// process values
int maxValue = Integer.MIN_VALUE;
for (IntWritable val : values) {
System.err.println(val.get());
maxValue = Math.max(maxValue, val.get());
}
context.write(_key, new IntWritable(maxValue));
}
}
MaxTemperature.java
//import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MaxTemperature {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: MaxTemperature <input path> <output path>");
System.exit(-1);
}
//Configuration conf = new Configuration();
Job job = Job.getInstance();
job.setJarByClass(MaxTemperature.class);
job.setJobName("Max temperature");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MaxTemperatureMapper.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
代码完成后,先准备一个测试文件吧,文件内容我给你弄个现成的,千万注意,最后别有空行。
0067011990999991950051507004+51317+028783FM-12+017199999V0203201N00721004501CN0100001N9+00001+01391102681 0067011990999991950051507004+51317+028783FM-12+017199999V0203201N00721004501CN0100001N9+00021+01391102681 0067011990999991952051507004+51317+028783FM-12+017199999V0203201N00721004501CN0100001N9+00011+01391102681 0067011990999991953051507004+51317+028783FM-12+017199999V0203201N00721004501CN0100001N9+00031+01391102681
运行的时候需要设置下参数Run->Run Configuration:
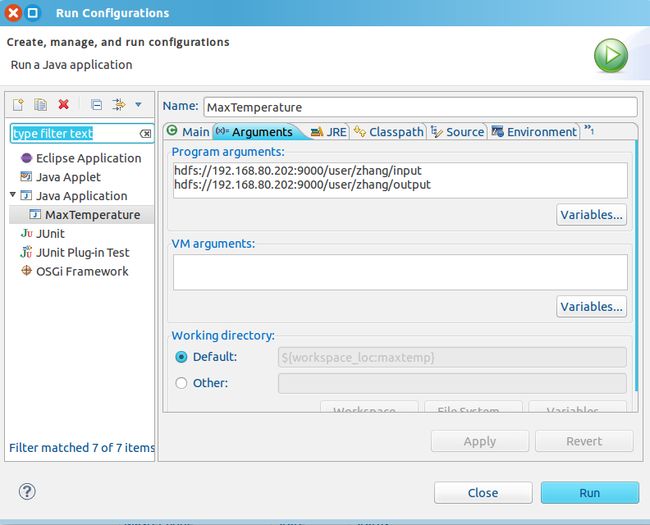
我开始运行的时候,一个问题是出现了关于log4j相关的警告,第二个问题是程序运行结束后,只出现了output文件夹,但是没有出现输出文件。整了半天,果然是不能忽略警告呀,警告解决后,会出现日志,错误自然就知道了呀。
解决日志的问题方法网上有很多,就是在src目录添加一个文件log4j.properties,内容如下(不限于这一种)
# Configure logging for testing: optionally with log file log4j.rootLogger=WARN, stdout # log4j.rootLogger=WARN, stdout, logfile log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
关键是你要在eclipse目录下刷新一下,出现这个文件,否则不管用。于是我看到了日志,原因是text文件多了一个空行,导致String的截取方法出错崩溃。
修正后,出现了正确的结果。