专家:多核时代对软件设计的挑战(转载)
转自http://www.src119.com/server/show.php?itemid=390
在处理器主频进一步提升越来越难的时候,多核处理器的引入让摩尔定律再放异彩。然而,当我们在为多核化时代大声欢呼的同时,也不得不面对随之而来的问题。今天,甚至普通用户也不得不面临并行计算的问题,而多核处理器更是对系统和程序设计等都提出了诸多挑战。
在本文中,笔者首先介绍了并行计算的基本概念,在简单分析多核处理器发展趋势的基础上,介绍了在高性能计算领域常用的两个并行程序开发环境MPI和OpenMP。结合多核处理器的特点,探讨了将来的软件设计面临的挑战?此外,介绍了目前在国际上正在研发的针对千万亿次并行机和多核处理器的新一代并行程序设计语言,最后进行了趋势分析和展望。
历史悠久的并行计算
实际上,对于信息技术来说,并行机的发展历史已经算比较长的了。20世纪60年代初期美国就出现了全世界最早的并行计算机。70年代之后还出现过向量机、并行向量机(以Cray公司为代表,中国的则是银河系列),以及20世纪90年代初的SIMD并行机,其代表作就是Think Machine公司的CM系列并行机。Think Machine公司通过将大量体系结构简单、功能较弱的处理器用网络连接实现大规模的并行计算系统,但由于应用领域有限等原因,这类系统很快就消亡了。曾经一度流行且目前还占有一席之地的并行计算机是分布式存储的M 机和基于SMP的共享存储小型机。但目前市场上占据主流位置的应该是Cluster集群系统。
在高端计算里我们需要通过并行去更快更好的解决挑战性的问题。另外一个必须并行的原因是电路设计的物理极限。单个处理器的线宽总有一天要达到物理极限,所以不得不转向多核,把痛苦的事情转嫁到大众身上。这就像我们人体的生长,人青年时期会不断地长高(与处理器主频的增长类似),但长到一定程度时就要向宽的方向发展(多处理器,多核)。
并行处理的精确定义是用多个计算部件共同快速完成挑战性的任务。这里有几个关键词,要多个计算部件(或计算机)、要共同(互相配合)、要快速、还要完成挑战性的任务。其好处就是提高性能,缩短解题时间,求解规模更大的问题。如果造一个主频极高成本也极高的单处理器,还不如把几个低主频的处理器一起使用,而且还可以容错。
比较常见的并行机就是SMP(对称多处理),但现在新的选项是多核处理器(在一个处理器内实现,不可分割,打包销售,买一送多),且普通大众将来都会逐渐接触和使用到。此外,并行计算还可以分为处理器内(最新的还包括多个处理器核)和处理器之间的两种并行层次。而根据不同的处理器间互联网络,也可以分成不同类型,而且研究如何进行互联也曾经是一个极其热门的研究课题。实际上,现在多处理器核之间也是需要互联网络的。我们甚至可以把多处理器核之间的互连模式看成原来的SMP多处理甚至多个并行计算节点之间互联在单个处理器内的缩小版。从存储模型上,并行处理还也可以分为分布式存储和共享存储两大类。
并行算法基本上就是一个浅而宽的算法结构,实际上就是把长而高的串行算法的时间复杂度通过增加空间复杂度的方式进行压缩,把以前一个周期一个操作去执行的算法结构改造成一个周期可以进行多个操作的并行算法,这就是并行化要做的主要工作。说白了,并行就是在一个时刻或者时间段里有一个以上的事件发生。
在并行计算领域里,最有名的两个定律是Amdahl定律[1]和Gustafson定律[2]。Amdahl定律指出,如果一个算法里不能并行的部分所占的比重是10%的话,那么并行化算法所能达到的最大加速比超不过10。这个定理出来以后,对并行计算打击很大。后来Gustafson发现,实际上Amdahl定理存在的问题是只假定并行系统处理一个固定规模的问题,在这种情况下,再增加处理器当然没有意义。但如果把问题规模随着机器规模一起变大,加速比仍然可以变大。Gustafson定理出现以后,并行机的发展前途豁然开阔。
在并行计算领域里,人们常常提到并行加速比(求解问题的串行执行时间与并行执行时间的比)。并行计算追求的最理想情况是用P个处理器,就能得到P倍的速度提升。但这通常很难达到,因为并行会引入通讯和调度等额外开销。当然在极个别情况下,也会出现超线性加速比的情况。
多核处理器:计算方式的革命
多核处理器的出现实际上是一次计算方式的革命。国外有些专家说,大家的免费午餐没有了(Free Lunch is Over!),我们不得不面对并发和并行操作这些通常是并行计算的专业人员和高端用户才需要面对的问题。对于从事IT的人来说,摩尔定律一直是一个圣经,当然对存储和价格来说目前它仍然成立,但对处理器性能来说,目前我们只能用多核的方式让它继续沿着摩尔定律上升。散热和漏电是两个迫使我们不得不转向多核处理的深层次的工业原因,工业界在2006年突然要面临一个拐点,从单核向多核处理器急速拐弯,这是大部分人甚至处理器制造商都没有预料到的,至少没想到出现的这么快。
传统提高处理器性能的方法,一个是通过缩小线宽,不断提高主频,12年里从60MHz提高到了3.8GHZ。第二条途径是运行时优化,通过采用功能更强大的指令,流水处理、分枝预测、多指令并行和指令重排序等来实现。第三条途径是通过不断增大Cache的容量来实现。
实际上这也是一个不断寻求更高性能手段的发展历程,多核的出现也是其中的一个阶段。就如同流水线、多级Cache等刚被引入处理器设计中,受到很大的抵制一样,多核的引入初期,肯定也不会很快被接受。但相信通过一段时间的适应,以及工业界和科研界的努力,多核也会最终成为未来处理器的标准配制,大家逐渐习以为常。多核的引入实际上增加了一个新的处理器设计自由度,在给体系结构设计带来更多灵活性的同时,当然也给用户带来了很多的复杂性。
当前各个主流处理器厂商都推出了自己的多核产品,八核的,甚至更多核的产品也已或即将出现。 英特尔公司2006年底抢先推出了自己的四核产品,AMD公司也会在2007年推出自己的四核产品。实际上,不同的多核处理器可以有不同的生产工艺,有的是在一片硅片上同时造出两个紧邻的紧耦合的核来,有的是把两个分离的核封装在一个芯片里。这里面涉及生产工艺复杂性和提高成品率,降低成本,缩短生产周期等方面的问题,所以会有不同的制造选项。
多核处理器的高速Cache层次比较复杂,其中有每个核私有的L1 Cache,有多个核共享或私有的L2 Cache,甚至更多的核共享的L3 Cache。这就导致不同的核访问不同位置Cache的速度和延迟不同,出现NUCA的现象(非一致Cache访问)。NUCA也是目前学术界研究的课题之一。
现在才不过几个核,大家还不必太害怕,将来我们可能会面临几百个核,简直是核的海洋,这种情况甚至连搞并行计算的专家都感到害怕和麻烦。一个机器里那么多核,怎么去很好的利用?这肯定是大家首先冒出来的一个问题。本来并行计算就很难了,再放那么多核就更困难了。
其实90年代末就已经有人在做多核处理器的研究,其思路是把功能简单的处理器用网络连接起来,互相协作来解决延迟的问题。比较早的是RAW处理器,由美国MIT大学开发,是我们目前称为Tile结构处理器的先驱(http://cag-www.lcs.mit.edu/raw)。

图 RAW处理器的原型芯片外观

图RAW处理器的互联网络重构
现在比较热的一个Tile结构处理器研究项目叫TRI ,其目标是实现单处理器一个周期达到万亿次操作且可靠、智能自适应的目标,是由美国DARPA的多态计算体系结构项目从2000年开始资助Texas大学的Austin分校2000万美元开展的一个研究项目,整个项目由30名研究人员(含研究生)组成。但Tri 所采用的体系结构与传统的冯-诺依曼体系有所不同,不是目前流行的指令流驱动,而是数据流驱动(显示数据图执行EDGE),以数据的到达作为指令执行的触发标志,而不是根据用户或编译器预先规定好的指令顺序来执行。该处理器每周期可以调度一个包含128条指令的指令块映射到执行单元的网格上执行,且可以通过多态重组合的功能挖掘包括指令级并行、线程并行和数据并行等多层次的并行,从而适应不同的应用需求。该处理器2006年已经推出原型系统,是目前比较被看好的未来处理器的一个发展方向。

TRI 处理器原型系统

TRI 处理器芯片布局
我们面临怎样的并行程序设计环境?
一般来说,并行程序设计模型主要分两大类,一类是共享存储模型,一类是消息传递模型。共享存储模型大家比较熟悉,主要是采用多线程,其主要程序开发环境是已经成为事实工业标准的OpenMP和早期的Posix Threads,目前主要是商业编译器如Intel等的C++和Fortran编译器提供对该语言的支持,而gcc等开源编译器尚不能支持OpenMP。
对于多核来说,马上可以用的标准程序设计环境恐怕就是OpenMP了。而虽然可用但对一般用户来说比较困难的是消息传递开发环境包括MPI和PVM(目前以很少使用)等,此类开发环境是开源的,可以免费下载。其中最常用的两个MPI标准实现是MPICH[17](目前是MPICH2,是MPI 2.0标准的实现,用以取代MPI 1.0版本)和LAM/MPI[18]。其中的LAM/MPI也在从MPI1.0版本向MPI 2.0版本,其下一代软件的名称为Open MPI[19],已经发布了正式版本。此外,由于现有机器体系结构层次非常复杂,还可以把上面几种并行设计环境和向量并行等混合使用,充分挖掘机器的性能潜力,我们通常称之为混合并行。
实际上,并行算法的设计目标是挖掘问题求解过程中的并行性,寻求并行算法与并行机器体系结构的最佳匹配和映射,合理组织并行任务,减少额外消息传递和数据移动开销。总体来说,开发一个并行程序可以有三种途径,一个途径是串行程序自动并行化。这条路目前还没走通,大家认为更为实际的目标应该是人机交互的自动并行化。
第二条途径是设计全新的并行程序设计语言。但它有一个致命的缺点就是需要全部改写原来的程序,对用户来说就很痛苦了,成本和风险也很高,且效率没有保证。但是,随着多核的出现,如果面向大众推广并行计算环境的话,就必须有一种新的大众容易接受的程序设计语言,否则很难推广普及。目前国际上正在研究几种新的并行程序设计语言,下面会简单介绍。
第三条途径就是串行语言加并行库或伪注释制导语句的扩展,实际上就是增加一个库或一些新的制导语句来帮助进行消息传递和并行。这正是MPI和OpenMP所采取的途径。目前也是比较容易被接受且性能高的途径。但其程序开发效率很低,难度也比较大。
多核处理器对软件设计的挑战
随着处理器体系结构变得越来越复杂,从语言到机器硬件的鸿沟越来越大了,需要程序设计语言对底层体系结构进行高度抽象,使用户的程序设计变得简单高效,同时又不损失过多性能。编译器就需要做很多工作来弥补这个鸿沟。
很多人也注意到了,现在很多厂家提供的多核处理器,主频是比较低的,主要目的是为了降低散热和功耗。如果买了多核处理器的用户不去用好这几个核,让它们同时合作去完成一个任务,而只用一个核工作的话,摩尔定律就不起作用了。
对很多多媒体应用,或大量相互之间不相关的Web访问的应用来说,它们之间是没有依赖关系的,用户不必改写程序,就可以自然的通过操作系统的多核调度获得性能提升。但对于计算强度很大的程序来说,里面有大量数据要串行处理,且存在复杂的数据相关性,如果不进行数据分割的话,只能由一个低频的单核来串行处理,执行时间会很长。既使很多应用可以同时运行,多核还会带来一个运行资源冲突的问题,多核同时运行期间很多资源其实是共享的,比如高速缓存、存储体、BUS等,这就需要改进操作系统和用户调度,来加以缓解。
但多核的一个缺点是存在严重的存储墙(Memory Wall)问题。实际上处理器的管脚是有限,数量增加速度落后于处理器速度的增长,且不可能无限制增加,由此意味着存储访问的带宽增长也有限制。将来数量众多的处理器核,都挤在处理器里面,没办法拿到自己所需要的数据,严重影响性能。
此外,多层次的缓存,以及核之间共享缓存的方式,再加上访问本地缓存和远程缓存的时间不一致,都给程序设计和性能优化带来困难。当然,多核并非一无是处,它也有优点,这就是核之间的通讯延迟会有量级的减少,核之间的带宽也有量级的增加。怎样利用这些优势来优化并行程序设计,是需要研究的问题。
多核作为一种新的并行层次原来是没有的,现在出来了,应该怎么应对呢?最简单的就是从硬件底层对多核加以隐藏,让用户感觉不到,这当然是最理想的。用户的指令运行时,硬件底层进行相关性分析,并在多核间进行调度。但这种方法的可扩展性很成问题,适用性是不是很广也成问题,且增加了处理器设计的复杂性,很容易成为性能瓶颈和提高生产成本。对小规模问题和少量的核来说也许可以用,但问题规模更大或核数量更多之后,就不可行了。另外一个很自然想到的办法,就是把高端计算里面并行程序设计的语言和环境如MPI[4]和OpenMP[5]等一起来用。再根据多核的特点,充分利用新的体系结构优势,加以性能优化。这是最自然而然且可行的应对措施。
实际上并行不是目标,我们并不愿意去并行,而是一种无奈的妥协,是为了继续使性能增长的摩尔定律有效。有些国外专家说过,为一个1 PHz(千万亿赫兹)的处理器编写程序会比为一百万个1GHz的处理器更容易。并行程序设计不但困难而且容易出错。
我们什么时候能不需要并行呢?当然最好是继续增加处理器的主频,我们看到IBM公司的Power6处理器就突破了4GHz的主频限制,在2007年发布时,其主频最高将达到5GHz,并支持十进制运算(实际上,当计算机将十进制转换成二进制进行计算,然后再将计算结果转换成十进制时,就会出现计算精度问题;但目前十进制计算的速度仍然不及二进制[16]),为继续通过提高主频提升性能打开了突破口[15];还有一个途径就是出现革命性的新的计算技术如量子计算等。
实际上,当前并行计算的现状是部分程序员可以进行并行编程,且大部分程序是MPI程序,OpenMP有一定比例。服务器程序大部分采用多线程。但大部分普通应用都还是串行的。
新一代并行程序设计语言日渐升温
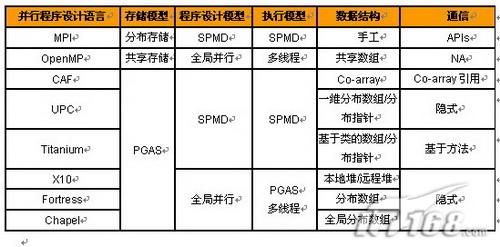
当前国际上对新一代并行程序设计语言的研究正日渐升温。其中美国HPCS项目(高生产率计算系统,http://www.highproductivity.org/ )资助开发的新的高生产率并行编程语言有三种,分别属于三个公司,包括IBM的X10、SUN公司的Fortre 和Cray公司的Chapel。这三个语言目前还处在原型开发阶段,大规模推广还需要时间。
此外,还有一类称为分割全局地址空间系统(PGAS)的并行程序设计语言,包括UPC(Unified Parallel C,C语言的扩展)、CAF(Co-Array Fortran,Fortran的扩展)和Titanmin(Java的扩展),目前已经开始在部分实际项目中得到应用,且效果不错。对于新并行程序设计语言的研发,国内目前还没有国家项目进行资助,这一点需要引起关注。
HPCS语言是美国为了支持从千万亿次机器到单个多核芯片的应用范围所研发的高效能计算系统的配套语言,属于研究型语言,有很多新的设计思想。其主要设计思路是降低并行程序设计的难度,提高软件生产效率,同时提供高性能、可移植和健壮性的支持。由于存储层次很复杂,还需要在语言里支持进行数据局部性的描述,要明确指出数据所在位置。
举例来说,IBM的X10的意思就是10倍,提高高性能程序设计的生产效率10倍,是2003年启动的,目前已经完成了原型系统的开发,估计还需要较长的时间投入商业使用,现在只是小范围内试用。该语言对多核系统与集群系统提供了统一的支持。为了保持可移植性和安全性,该语言继承了JAVA的虚拟机,是其子集的扩展。它基于JAVA 1.4进行扩展。把JAVA里的并发库用它自己的并行库替换,数组用X10数组替代。X10把存储分成三类,一类是不可变数据、一类是共享堆、一类是活动堆栈。为描述局部性,引入了Place的概念。一般共享多线程的计算将局限于一个Place里,且线程被更轻量级的Activity取代。如果支持分布存储全局并行,就需要多个Place,它们之间全局共享一定的数据,同时也允许每个Place有自己的私有数据。这一点与PGAS语言类似。多个 Place之间的并行通过异步操作来进行支持。
PGAS语言是比HPCS语言早一些的语言,但比MPI和OpenMP要晚。PGAS语言的细节虽然不同但内涵相似,特别是在支持 MD(单程序多数据)计算方面。该类语言仍然需要用户提供数据和任务映射的细节,虽然还是有难度,但对专家来说已经降低了不少。
下表是当前几个比较流行和正在研究的并行程序设计语言的比较。它们都可以部分解决多核带来的软件设计问题,各有不同的特点。当前正在研究的新并行程序设计语言追求的总目标是在保障性能的同时,降低编程的复杂性。
表1:当前并行程序设计语言的比较
对于处理器主频来说,摩尔定律已经接近极限了。普通用户也不得不面临并行的问题。多核处理器对操作系统和程序设计等都提出了很多挑战,需要思考怎么解决这些问题。应对多核处理器的软件开发,可以有几种解决思路,包括硬件隐藏、自动并行、OpenMP多线程、MPI优化、新并行语言等。一些新的高生产率和支持全局地址空间的并行程序语言已经出现了,而且正在快速发展,对我们应对多核处理器的挑战提供了可能的最终解决途径。
(本文作者介绍:张云泉,博士,副研究员,国家863“高性能计算机评测中心” 技术委员会委员,中国科学院软件研究所并行计算实验室副主任、中国计算机学会高性能计算专委会委员、中国软件行业协会数学软件分会常务理事、中科院软件所学位委员会委员)
致谢:本报告的部分内容引用了清华大学陈文光副教授的报告。
参考文献
[1]Amdahl, G.M.. Validity of single-proce or a roach to achieving large-scale computing capability, Proceedings of AFI Conference, Reston, VA. 1967. . 483-485.
[2] Gustafson, J.L., Reevaluating Amdahl's Law, CACM, 31(5), 1988. . 532-533.
[3]Bailey, D., Twelve Ways to Fool the Ma es When Giving Performance Results on Parallel Computers, RNR Technical Report, RNR-90-020, NASA Ames Research Center, 1991.
[4] OpenMP, http://www.openmp.org
[5] MPI, http://www.mpi.org
[6] DARPA HPCS Project, http://www.highproductivity.org/
[7] PGAS, http://www.ahpcrc.org/conferences/PGAS2006/
[8] GA et Project, http://ga et.cs.berkeley.edu/
[9] Co-Array Fortran Compiler Project, http://www.hipersoft.rice.edu/caf/index.html
[10] Titanium Compiler Project, http://titanium.cs.berkeley.edu/
[11] Berkeley UPC - Unified Parallel C, http://upc.lbl.gov/publicatio /
[12] IBM X10,http://domino.research.ibm.com/comm/research_projects. f/pages/x10.index.html
[13] The Cascade High-Productivity Language, http://chapel.cs.washington.edu/
[14] Fortre Project, http://research.sun.com/projects/plrg/
[15] IBM Power6,http://www.mozine.cn/archives/2006/10/12/1053
[16] IBM的十进制计算,http://www2.hursley.ibm.com/decimal/
[17] MPICH2实现,http://www-unix.mcs.anl.gov/mpi/mpich2/
[18] LAM/MPI 实现,http://www.lam-mpi.org/
[19] Open MPI,http://www.open-mpi.org/