postgresql集群方案hot standby初级测试(三)——蛋疼测试——手动同步数据
最近也做了很多关于集群方面的测试,但是公司又有这样一个需求:
当集群搭建好后,如果主节点意外死亡,我们希望从节点能够当做主节点重新启动,这样不影响客户端的操作,或者只受短时间影响。
此时的我,有种蛋蛋的忧伤,“对于程序员,需求神马的最讨厌了”。无奈之下看了原理,并做了基础测试。
本文来自:http://blog.csdn.net/lengzijian/article/details/7736961
在之前我们模拟过集群遇到的几种状况,其中有一种,当客户端发送数据时,强行kill掉主库所有进程,导致主库和从库的数据不同步,但是当重启主库后,从库会拉数据回来,之后同步数据。(http://blog.csdn.net/lengzijian/article/details/7729380)
问题就在于如果主库不启动,我们如何同步数据?
在分析了原理后,发现主库进程中有这样一个进程
wal sender process postgres192.168.30.199(33121) streaming 0/424993E0
听名字就像是专门服务发送wal日志的进程,并且后面写出了从库的ip,这使得我非常确认它是负责主库和从库的数据同步的。
之后我冒出了一个想法:自己传输wal日志。查看是否能够达到预期的效果。
1. 先搭建hotstandy集群,这次只用一主一从;
2. 运行插入数据库脚本:1个线程100000数据;
脚本和用法在http://blog.csdn.net/lengzijian/article/details/7729465中提供
3. kill-9掉主库所有postgress进程;
查看插入脚本报错信息:

文中16586为插入失败的位置;
查看从库数据量:

关键时刻开始
4. 查看从库xlog文件夹

5. 查看主库xlog文件夹
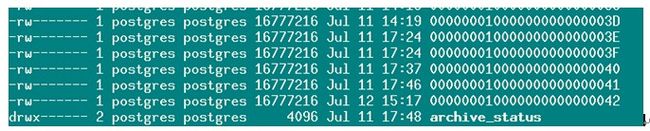
6. 查看主库xlog/archive_status文件夹
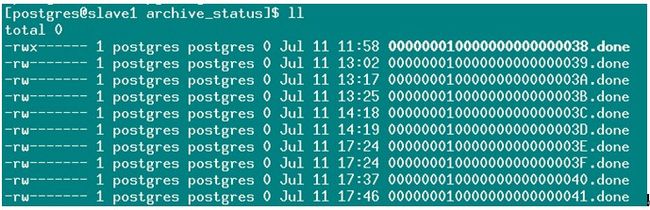
7. 发现xxx41号文件已经处理完成,xxx42号文件还未处理完成,那么我们对比从库xlog文件可以认为42号尚在传输过程中被终端,再看从库的43和44的时间不符和逻辑可以直接删除。我们可以直接把主库的42号文件复制到从库里。
删除从库无用数据

复制主库42号文件到从库
![]()
8. 查看从库数据量:
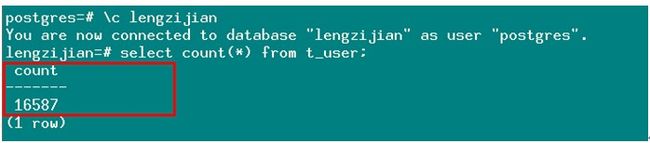
9. 可以看到与之前的错误日志数字相符(可能有同学会注意到,相差1个数,主要原因可能是插入成功后,断开连接报错,这里本人做了不下3次的试验,结果均正常)
10. 启动主库查看数据是否同步:主库的数据量如下
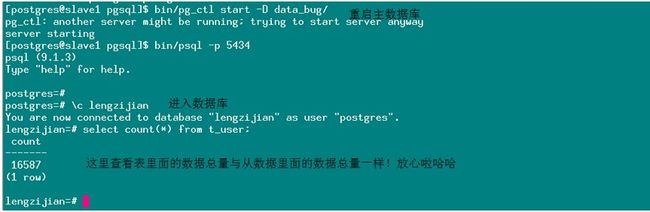
11. 可以看到与之前回复的数据总量一样,oh~~~~~开心,有些人可能要喷本人了,因为懂原理之后,这些都是正常情况!!本人的态度正如本片文章标题一样,宁可去做十几遍的尝试,要不想要小概率的时间发生在我的服务器上(简称:“蛋疼”)。
这里需要注意的是:
如何判断那些xlog文档是已经同步过的,那些事没有同步的?
这里写下我多次测试后的经验,在主库的xlog/archive_status中,带.done后缀的文件仅表示主库中已经归档完成的,不代表已经发送给从库的;在从库中存在一些混淆的日志文件,例如之前我们删掉的43和44,判断无效的依据是根据时间和文件名,有些文件明显不是刚刚操作过的。删掉了混淆的文件后便可以恢复编号最大的文件了(如果怕错误,也可以多恢复一些文件)。如果实在不懂,可以联系本人
有了如上经验,我们可以自己写脚本拉数据,并且启动从节点为主节点方式(目前是本人推测,还未真实实验),如果有任何疑问或者本文中存在错误,可以随时联系本人O(∩_∩)O哈哈~。