从http协议看百度360大战
前段时间甚嚣尘上的3B大战,慢慢退出人们的视线,但是两家公司的战争才刚刚开始,一家是资金技术实力雄厚的搜索引擎巨头,一家是携客户端之威,行事诡谲的数字公司。谁会取得最后的胜利?我们在看热闹之外,也来学习一下云端和客户端是如何通过HTTP协议过招的。
360以客户端见长,360安全卫士,以安全为名,占据着用户电脑的最高权限,用户通过360浏览器上网,用户的所有上网行为,360完全知晓。而百度作为一家网站,在用户电脑上只是一些文本文件,所能做的实在不多,360占据天时地利。百度所选择的策略是,拒绝360spider的抓取,提醒通过360浏览器,和360搜索过来的用户,将百度设置为主页等很被动的措施。
这里百度首先需要解决下面几个问题:
1.如何判断360spider对百度网站的抓取
2.怎么判断用户是通过360浏览器访问过来的
3.怎么判断用户是通过360搜索过来的
先来看看http协议
http协议是万维网(worldwide web)交换信息的基础,工作在TCP/IP协议体系中的TCP协议上。
HTTP协议的主要特点可概括如下:
1、支持客户/服务器模式。
2、 简单快速: HTTP协议简单,使得HTTP服务器的程序规模小,通信速度很快。
3、灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
4、无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。
5、无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。
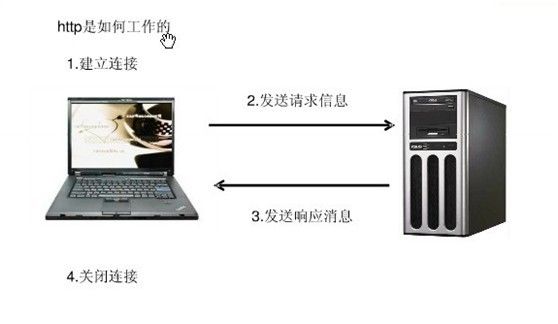
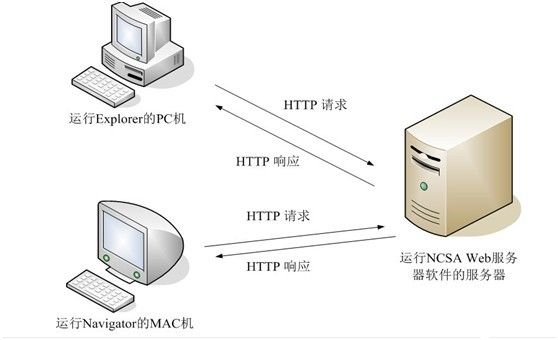
HTTP请求浅析
http请求由三部分组成,分别是:请求行、请求报头,消息正文(可选)组成,由浏览器进行拼装,不同浏览器行为略有差异。
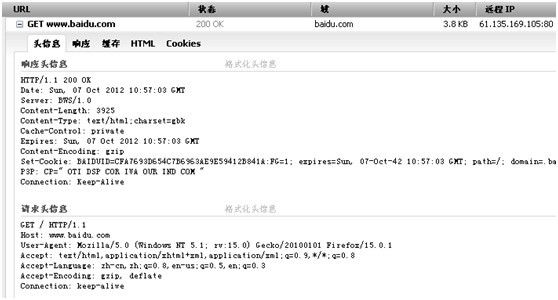
我们使用firebug来看看,当我们在浏览器中输入www.baidu.com时,浏览器到底干了什么?
首次访问(访问之前清除了cookie):
第二次访问:
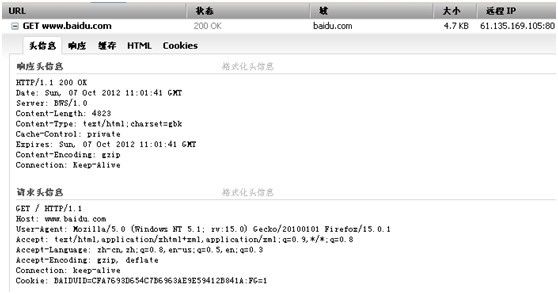
第二次访问与第一次访问的区别是多了Cookie:一行。我们看看第二次访问的请求头:
GET / HTTP/1.1
Host: www.baidu.com
User-Agent: Mozilla/5.0 (Windows NT 5.1; rv:15.0) Gecko/20100101 Firefox/15.0.1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
Connection: keep-alive
Cookie: BAIDUID=CFA7693D654C7B6963AE9E59412B841A:FG=1
第一行为请求行:
请求行以一个方法符号开头,以空格分开,后面跟着请求的URI和协议的版本,格式如下:Method Request-URI HTTP-Version CRLF
正对上面例子中的 GET / HTTP/1.1
第二行开始为请求报头:
一个空行表示请求报头结束
Host: www.baidu.com 该报头域是必须的,指明域名地址
User-Agent: Mozilla/5.0 (Windows NT 5.1; rv:15.0)Gecko/20100101 Firefox/15.0.1 该报头域将浏览器、操作系统信息告诉服务器
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8该报头域用于指定客户端接受哪些类型的信息
Accept-Language: zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3 报头域用于指定客户端接受哪些语言的信息,服务器根据
Accept-Encoding: gzip, deflate 用于指定可接受的内容编码。deflate编码是由RFC 1950 [31]定义的"zlib"编码格式与RFC 1951 [29]里描述的"deflate"压缩
机制的组合的产物。
Connection: keep-alive Keep-Alive模式(又称持久连接、连接重用)时,Keep-Alive功能使客户端到服 务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive功能避免了建立或者重新建立连接。
Cookie: BAIDUID=CFA7693D654C7B6963AE9E59412B841A:FG=1 cookie是网页在本地留下的小片段信息,记录登陆用户ID等信息。
我们看user-Agent报头域,指明了浏览器和操作系统等信息,user-agent,用户代理,顾名思义,浏览器和spider作为用户的代理向网站服务器请求页面,所以在这个报头域中指明了自己的身份,不同的浏览器或者搜索引擎的spider都会有自己的标志,百度可以根据这个值,拒绝360蜘蛛的抓取和区别对待来自360浏览器的访问。当然360spider会千方百计的隐藏自己的身份,那么百度就需要靠另外的办法来进行甄别了,spider访问会有一些与正常访问不一样的行为,这里不细表。
从360搜索里面进入百度主页,与直接进入百度主页展示是不一样的,百度是怎么知道用户是从360进入的呢?
我们从360搜索里面进入百度主页,看请求信息,发现了端倪:
GET / HTTP/1.1
Host: www.baidu.com
User-Agent: Mozilla/5.0 (Windows NT 5.1; rv:15.0) Gecko/20100101 Firefox/15.0.1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
Connection: keep-alive
Referer: http://www.so.com/s?q=%E7%99%BE%E5%BA%A6&pq=%E8%B4%B4%E5%90%A7&_xv=331&_re=0&src=srp
Cookie: BAIDUID=CFA7693D654C7B6963AE9E59412B841A:FG=1
区别就在这个Referer报头域上,referer报头域,记载用户是从哪个URL出发访问当前请求的页面,这个是由浏览器自动填写的。百度可以在web服务器层面针对referer报头域不同的值进行判断处理,给来自360搜索的页面请求,加上一些提醒。
HTTP响应
响应也分为三个部分状态行、响应报头、响应正文
HTTP/1.1 200 OK
Date: Sun, 07 Oct 2012 17:47:42 GMT
Server: BWS/1.0
Content-Length: 5027
Content-Type: text/html;charset=gbk
Cache-Control: private
Expires: Sun, 07 Oct 2012 17:47:42 GMT
Content-Encoding: gzip
Connection: Keep-Alive
第一行为状态行:
状态行格式如下:HTTP-VersionStatus-Code Reason-Phrase CRLF
HTTP/1.1 200 OK http协议版本 状态码200 状态码含义OK
第二行开始为响应报头:
Date: Sun, 07 Oct 2012 17:47:42 GMT 响应时间
Server: BWS/1.0 服务器信息 BWS为百度自己开发或定制的,安全性很高
Content-Length: 5027 响应正文长度
Content-Type: text/html;charset=gbk 正文类型
Cache-Control: private用于指定缓存指令,缓存指令是单向的(响应中出现的缓存指令在请求中未必会出现),且是独立的(一个消息的缓存指令不会影响另一个消息处理的缓存机制)
Expires: Sun, 07 Oct 2012 17:47:42 GMT 实体报头域给出响应过期的日期和时间。与date时间一致,说明是不需要缓存的。
Content-Encoding: gzip 编码类型,gzip压缩类型,可提高响应速度
Connection: Keep-Alive 保持连接模式
以空行隔开的第三部分为响应正文:
也就是网页信息
参考:
http://my.oschina.net/u/260739/blog/66464
http://www.phpben.com/?post=77
http://zh.wikipedia.org/wiki/%E8%B6%85%E6%96%87%E6%9C%AC%E4%BC%A0%E8%BE%93%E5%8D%8F%E8%AE%AE