海量数据挖掘MMDS week2: 局部敏感哈希Locality-Sensitive Hashing, LSH
http://blog.csdn.net/pipisorry/article/details/48858661
海量数据挖掘Mining Massive Datasets(MMDs) -Jure Leskovec courses学习笔记之 Locality-Sensitive Hashing(LSH) 局部敏感哈希
{This is the first half of discussion of a powerful technique for focusing search on things that are likely to be relevant, while avoiding the examination of things unlikely to be what we are looking for, in much the way ordinary hashing gets us to records we want without looking through an entire database. This subject will continue in week 7.}
局部敏感哈希LSH简介
Hashing, probably seemed like a bit of magic.You have a large set of keys, and when you want to find some key k,you go right to it without having to look very far at all.
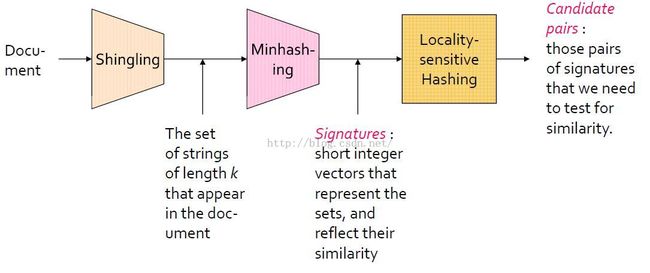
shingling, a way to convert the informal notion of similar documents into a formal test for similarity of sets.
min hashing, allows us to replace a large set by a much smaller list of values.the similarity of the small lists,called signatures,predicts the similarity of the whole sets.
locality sensitive hashing,is another bit of magic.we are pointed right at the similar pairs without having to wade through the morass of all pairs.find similar sets or similar documents without doing anything that involves searching all pairs.
哈希
大家应该都知道,它的查找时间复杂度是O(1),有着极高的查找性能。我们通常的哈希,比如有一个hash function: f(x)=(x*7)%10,有两个数据x1=123,x2=124,现在用f(x)把它们hash一下,f(x1)=1,f(x2)=8,这想说明什么呢?看看原来的数据,是不是很相似?(假设用欧氏距离度量)再看hash后的数据,那就差得远了,说明这个hash它并没有保持相似性,那么这种就不是局部敏感哈希。
局部敏感
那什么叫“局部敏感”的哈希?它的意思就是:如果原来的数据相似,那么hash以后的数据也保持一定的相似性。LSH就是一种在hash之后能保持一定的相似性神奇玩意儿,这里为什么说是“保持一定的相似性”?因为我们知道,hash函数的值域一般都是有限的,但是要哈希的数据却是无法预知的,可能数据大大超过其值域,那么就不可能避免地会出现一个以上的数据点拥有相同的hash值。假设有一个很好的hash function,好到可以在hash之后很好地保持原始数据的相似性,假设它的不同取值数是10个,然后现在我有11个截然不相似的数据点,想用这个hash function来hash一下,必然会出现一个hash桶中有1个以上的数据点,只能在hash之后保持一定的相似性。其根本原因就是在做相似性度量的时候,hash function通常是把高维数据映射到低维空间上,高维空间上计算复杂度太高。
LSH是如何做的
一句话总结思想:它是用hash的方法把数据从原空间哈希到一个新的空间中,使得在原始空间的相似的数据,在新的空间中也相似的概率很大,而在原始空间的不相似的数据,在新的空间中相似的概率很小。
其实在用LSH前通常会进行一些降维操作

先说说整个流程,一般的步骤是先把数据点(可以是原始数据,或者提取到的特征向量)组成矩阵,然后通过第一步的hash functions(有多个哈希函数,是从某个哈希函数族中选出来的)哈希成一个叫“签名矩阵(Signature Matrix)”,这个矩阵可以直接理解为是降维后的数据,然后再通过LSH把Signature Matrix哈希一下,就得到了每个数据点最终被hash到了哪个bucket里,如果新来一个数据点,假如是一个网页的特征向量,我想找和这个网页相似的网页,那么把这个网页对应的特征向量hash一下,看看它到哪个桶里了,于是bucket里的网页就是和它相似的一些候选网页,这样就大大减少了要比对的网页数,极大的提高了效率。
皮皮blog
寻找相似集
规模带来的问题
{为什么要用LSH方法}
A fundamental problem of scale: If we have even a million sets, the number of pairs of sets is half a trillion.We don't have the resources to compare them all, so we need some magic defor,focus us on the pairs that are likely to be highly similar,never looking at the vast majority of pairs.
集合相似性的应用

Note:
1. Dual:We can use the same idea backwards.Where we think of a movie as the set of users who like that movie.Movies with similar sets of users can be expected to belong to the same genre of movie.
2. entity resolution实体分辨: People create records of data about themselves at many different sites,Google, Amazon, Facebook and so on.We may want to figure out when two records refer to the same individual.
相似文档

文档相似性度量的三大基本技术

寻找相似集的Outline
Note:
1. 存在false positives and negatives,但是by carefully choosing the parameters involved, we can make the probability of false positives and negatives be as small as we like.
2. The result of minhashing a set is a short vector of integers.The key property,which we'll prove, is that the number of components in which the, two of these vectors agree is the expected value of the similarity of the underlying sets.
3. the reason we want to replace sets by their signatures is that the signatures take up much less space.we'd like to be able to work in main memory.
Shingles
shingles及其相似性
Shingling is how we convert documents to sets so that documents that have a lot of text in common will be converted to sets that are similar in the sense that they have a lot of members in common.
k-shingle(k-gram): 文档中k个consecutive(连续的) 字符序列。
字符characters: The blanks that separate the words of the document are normally considered characters.If the document involves tags such as an HTML document then the tags may also be considered characters or they can be ignored.
k的取值: A k in the range five to ten is generally used.


Note: replacing a document by its shingles still lets us detect pairs of documents that are intuitively similar.
Shingles的压缩表示-tokens
我们构造shingle集合然后hash得到一个token。

Note:
1. 要压缩的原因:Because documents tend to consist mostly of the 26 letters, and most shingles do not appear in a document,we are often forced to use a large value of k, like k equals ten.But the number of different strings of length ten that will actually appear in any document is much smaller than 256 to the tenth power or even 26 to the tenth power.Thus, it common to compress shingles to save space while still preserving the property that most shingles do not appear in a given document.Shingling方法里的k值比较大时,可以对每个片段进行一次hash。比如k=9,我们可以把每个9字节的片段hash成一个32bit的整数。这样既节省了空间又简化了相等的判断。这样两步的方法和4-shingling占用空间相同,但是会有更好的效果。因为字符的分布不是均匀的,在4-shingling中实际上大量的4字母组合没有出现过,而如果是9-shingling再hash成4个字节就会均匀得多。
2. For example, we can hash strings of length ten to 32 bits or four bytes, thus saving 60% of the space that are needed to shore, to store the shingle sets. The result of hashing shingles is often called a token.
3. Since documents are much shorter than two to the 32nd power byte,we still can be sure that a document is only a small fraction of the possible tokens in it's sets.
4. 哈希冲突:几乎不发生。There's a small chance of a collision where two shingles hashed to the same token, but that could make two documents appear to have shingles in common when in fact they have different shingles.But such an an occurrence will be quite rare.
在有些情况下我们需要用压缩的方式表示集合,但是仍然希望能够(近似)计算出集合之间的相似度,此时可用下面的Minhashing方法。
Minhashing
Jaccard similarity相似性
{用于集合相似性的一般形式定义the formal definition of similarity that is commonly used for sets}


文档shingles的集合表示到布尔矩阵表示


Note:
1. For example, if the sets come from k-shingling documents,then the universal set is the set of all possible sequences of K characters or the set of all tokens if we hash the shingles.
2. 简单来说就是,每行即属性,每列即集合。
3. 这里的数值并不用去count出现了几次,因为是用Jaccard去度量的(只考虑出现与否,使用boolen值0、1)。
两列的Jaccard similarity

文档shingles的压缩表示-签名矩阵signature matrix
哈希函数哈希列C的hash值为对行随机排序后,列C对应有值1的那一行的行号(这个看上去跟hash没关系?对,没关系,但是这个行号可以通过hash模拟实现,在实际编程中就是使用hash函数hash得到的),得到新的一行所有列的hash值表示(也就是signature)。重复上述过程,对所有列使用多个hash函数进行hash,得到一个signature矩阵,这个矩阵就是原有矩阵的压缩表示。

Note:
1. 每一个Minshashing hash函数是和矩阵行的排列permutation关联在一起的,并且hash函数数目一般选择100个左右。And for the entire matrix or collection of sets,we select the Minhash functions once and apply the same Minhash functions to each of the columns.
2. 什么是signature: For each column, the signature is the sequence of row numbers we get when we apply each of these Minhash functions in turn to the column.
Minhashing示例
假设现在有4个网页(看成是document),页面中词项的出现情况用以下矩阵来表示,1表示对应词项出现,0则表示不出现,这里并不用去count出现了几次,因为是用Jaccard去度量的。
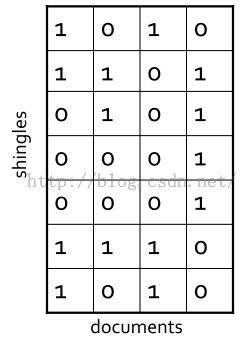
接下来我们就要去找一种hash function,使得在hash后尽量还能保持这些documents之间的Jaccard相似度。目标就是找到这样一种哈希函数h(),如果原来documents的Jaccard相似度高,那么它们的hash值相同的概率高,如果原来documents的Jaccard相似度低,那么它们的hash值不相同的概率高。

Min-hashing的定义和获得

首先生成一堆随机置换,把Signature Matrix的每一行进行置换,然后hash function就定义为把一个列C hash成一个这样的值:就是在置换后的列C上,第一个值为1的行的行号。

图中展示了三个置换(彩色的那三条)。比如现在看蓝色的那个置换,置换后的Signature Matrix(当然实际不用真的置换,使用索引就OK)为:

[ MinHashing基本原理]
Minhashing的性质
对于两个document,在Min-Hashing方法中,它们hash值相等的概率等于它们降维前的Jaccard相似度,也就是说在signature矩阵中计算两列(两文档的shinglings/tokens表示)的相似度约等于在原有shingles矩阵两列的相似度。
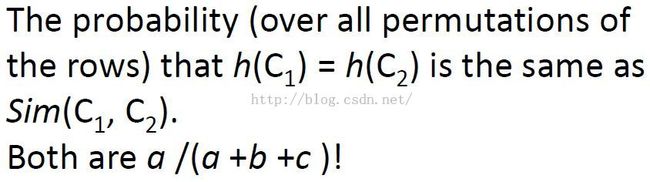

Minhashing性质的证明

Note:
1. 也就是说,如果C1、C2在某个排列(置换)中遇到的第一个非0行是类型a的行(对应都是1),那么C1、C2的minhash值相同。否则C1、C2对应的minhash值不同。
2. minhash值是遇到1才有的。
同一行的两个元素的情况有三种:a.两者都为1;b+c.一个1一个0;d.两者都为0。易知Jaccard相似度为a/(a+b+c)。另一方面,若排列(置换)是等概率的,则第一个出现的a出现在b+c之前的概率也为a/(a+b+c),而只有这种情况下两集合的minhash值才相同。Thus the probability that the two columns will have the same MinHash value is the probability that the first row that isn't of type-d is a type-a row.That probability is the number of type-a rows divided by the number of rows of any of the types a, b or c.That is, a/(a+b+c).证毕。
这标志着我们找到了需要的hash function。于是方法就有了,我们多次抽取随机排列得到n个minhash函数h1,h2,…,hn,依此对每一列都计算n个minhash值。对于两个集合,看看n个值里面对应相等的比例,即可估计出两集合的Jaccard相似度。可以把每个集合的n个minhash值列为一列,得到一个n行C列的签名矩阵。因为n可远小于R,这样我们就把集合压缩表示了,并且仍能近似计算出相似度。
Note: 现在这个hash function只适用于Jaccard相似度,并没有一个万能的hash function。
Minhashing的严格证明
设有一个词项x(就是Signature Matrix中的行上的值),它满足下式:
![]()
就是说,词项x被置换之后的位置,和C1,C2两列并起来(就是把两列对应位置的值求或)的结果的置换中第一个是1的行的位置相同。(π是一个随机排列)
那么有下面的式子成立:

就是说x这个词项要么出现在C1中(就是说C1中对应行的值为1),要么出现在C2中,或者都出现。这个应该很好理解,因为那个1肯定是从C1,C2中来的。
![]()
那么词项x同时出现在C1,C2中(就是C1,C2中词项x对应的行处的值是1)的概率,就等于x属于C1与C2的交集的概率。
那么现在问题是:已知x属于C1与C2的并集,那么x属于C1与C2的交集的概率是多少?其实就是看看它的交集有多大,并集有多大,那么x属于并集的概率就是交集的大小比上并集的大小,而交集的大小比上并集的大小,就是Jaccard相似度,于是有下式:
![]()
我们的hash function是
![]()
代入得到下式:
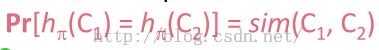
证毕。
签名signatures的相似度

Note: if we use several hundred Minhash functions, that is,signatures of several hundred components.We get a small enough standard deviation that we can estimate the true Jaccard similarity of the represented sets to within a few percent.
这里,我们将sets(shingles)转换成了signatures(矩阵中列代表的含义),而signaturs之间相似度就是行数值相同的比例。
我们来看看降维后的相似度情况
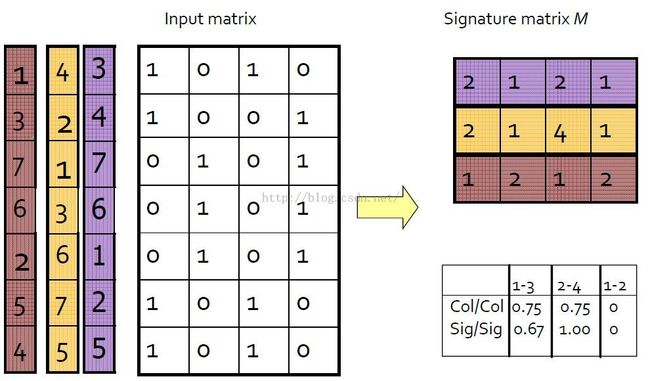
右下角那个表给出了降维后的document两两之间的相似性。
在原来的Input matrix矩阵中,列col1和col3的相似度为0.75,而在minhashing后的signature matrix矩阵中,列sig1和sig3的相似度为0.67。以此类推。
Note:列1、2原本就没有相似性,minhashing后也不会有。It turns out that when the similarity is zero it is impossible for any min hash function to return the same value for these two columns.
可以看出,使用signature矩阵代替input矩阵计算文档间相似度还是挺准确的:希望原来documents的Jaccard相似度高,那么它们的hash值相同的概率高,如果原来documents的Jaccard相似度低,那么它们的hash值不相同的概率。
Minhashing的实现
在具体的计算中,可以不用(也不大可能实用)真正生成随机排列,只要有一个hash函数从[0..R-1]映射到[0..R-1]即可。因为R是很大的,即使偶尔存在多个值映射为同一值也没大的影响。
随机排列的模拟实现
模拟实现排列而不实际对行进行排列。对每个main hash函数,pick a normal sort of hash function that hashes integers to some number of buckets.假设行R在排列中的位置是H(R),其中H是一个hash函数。这样,对每一列,我们寻找行r,其中行r在这列中的值为1,且h(r)的值是最小的。每次hash,h()函数都不同,这样行r的hash得到的值也不同,相当于对行进行了一次随机排列。也就是说对每一次hash,h(c)不是已有排列上第一个碰到的列号(这个其实也不叫hash啊,改了之后就成了名符其实的hash了),而模拟成对列c上值为1的所有行号进行hash,对列c取所有hash值最小的hash值作为h(c)的值。相当于使用hash函数对rows进行了排列。
那么,每个hash函数hi()相当于一次不同的排列,我们要计算所有列c的最小哈希minhash值,得到一个M矩阵,其中M(i,c)表示列c中随机排列后1对应的最小行号。
具体来说见下图:

Note:
1. 如果有100个minhash函数,那么slots的数目就是100*列的数目。
2. 可能的冲突:It's Entirely possible that h sub i, maps two or more rows to the same designation.But if we make the number of buckets into which h of i hash is very large,larger than the number of rows,then the probability of a collision at the smallest value is very small, and we can ignore the probability of a collision.
Min-Hashing简易算法

Note:
1. M初始化为无穷大。
2. 每个h(i,r)只计算一次,不要重复计算了。It is important we compute h(r) only once for each hash function in each row.
Min-Hashing算法实现实例
下面选取的hash函数将整数映射到5个桶buckets中(桶初始为无穷大)。
第一步,  对应的是
对应的是 ,并只更新了sig1,由于对于row 1 第二列值为0,所以值不变,仍为无穷大。
,并只更新了sig1,由于对于row 1 第二列值为0,所以值不变,仍为无穷大。

Note:Incidentally notice that the two signatures disagree for both components,so they estimate the Jaccard similarities of the columns that are zero.That's off by a little since,as you can see the true Jaccard's similarity of the columns is one fifth.
实现过程要注意的地方

Note:The algorithm we describe as soon as we can visit the matrix row by row.But often the data is available by columns and not by rows.For instance,if we have a file of documents,it's natural to process each document once, computing its shingles.That, in effect,gives us one column of the matrix.
Start with a list of row column pairs where the ones are.Initially sort it by column,and sort these pairs by row.
[Locality Sensitive Hashing 详解]
皮皮blog
局部敏感哈希Locality-Sensitive Hashing,LSH
上面通过minhash降低了文档相似性比较复杂度,但是即使文档数目很少,但是需要比较的数目却可能还是相当大。所以要生成候选对,只有形成候选对的两列才进行相似度计算,相似度计算复杂度又降低了。

哈希函数数目和桶数目的协调:We need to tune the number of hash functions and the number of buckets for each hash function so that the buckets have relatively few signatures in them.That way, there are not too many candidate pairs generated.But we can't use too many buckets, or else, pairs that are truly similar will not wind up in the same bucket for even one of the hash functions we use.
Signatures中生成候选集
直觉知识
{我们想要达到的效果}

Note:
1. threshold t是成为候选集的最小阈值,怎么确定这个阈值将在后面讲到。
2. 列c和d要成为候选集,其signatures相似度至少为t,而其相似度就是signatures矩阵中行相同的个数即M(i,c)=M(i,d)的数目。M(i,c)代表第i行(也对应于第i个hash函数)c的hash值bucket。
Signatures的局部敏感哈希
基本思想:由于列c和d要成为候选集,其signatures相似度至少为t。对signature矩阵,我们需要通过创建很大数目的hash函数把列hash到buckets中。我们想要达到的目的是:保证相似的列(signatures)尽可能地hash到同一个bucket中,而不是不相似的两列。

LSH的实现

首先将Signature Matrix分成一些bands,每个bands包含一些rows

Note: b*r就是signatures的总长度,也就是用于创建signatures的main hash函数的数目。b times r is the total length of the signatures.That is, the number of main hash functions we use to create the signatures.
然后把每个band哈希到一些bucket中(不同的band使用不同的hash函数,也就是每个band中,我们都要创建一个hash函数)

hash策略:This hash function hashes the values that a given column has in that band only.Ideally, we would make one bucket for each possible vector of b values that a column could have in that band.That is, we'd like to have so many buckets that the hash function is really the identity function, but that is probably too many buckets.For example, if b equals 5 and the components of a signature are 32-bit integers,then they would be 2 to the 5 times 32,or 2 to the 160th power of buckets.We can't even look at all these buckets to see what is in them at the end.So we'll probably want to pick a number of buckets that is smaller,say, a million or a billion.
这个方法的直觉含义就是,只要两个signatures在某个片断(band)上相似(hash到同一个bucket中),它们在整体上就有一定的概率相似,就要加入候选pairs中进行下一步比较!本来是所有列两两之间都要进行相似性计算的,但是通过hash后,只有在同一个bucket中的两列才要进行相似度计算,同一个bucket中的两列是局部相似的(因为只要某个band(列的一部分)相似就会hash到同一个bucket中,这也应该就是局部敏感哈希名称的来源吧),所以同一个bucket中的两两对都是候选对。the only way we can be sure a pair of signatures will become a candidate pair is if they, if they have exactly the same components in at least one of the bands.Notice that if most of the components of two signatures agree,then there's a good chance that they will have 100% agreement in some band.Otherwise they are unlikely to agree 100% in any band.There's a small chance that these segments of these columns are not identical, but they just happen to hash to the same bucket.We will generally neglect(忽略) that probability as it can be made tiny,like 1 in 4 billion,if we use 2 to the 32nd power buckets.
只要bucket的数量要足够多,使得两个不一样的bands被哈希到不同的bucket中,这样一来就有:如果两个document的bands中,至少有一个share了同一个bucket,那这两个document就是candidate pair,也就是很有可能是相似的。
bands大小和相似度阈值的选取准则:如果b很大,r很小,则会有很多pairs会分到同一个bucket中。Thus making b large is good at the similarity,if the similarity threshold is relatively low.
conversely, if you make b small and r large, then it would be very hard for two signatures to hash to the same bucket.Thus is best if we have a high threshold of similarity.
Note:
1. Perhaps column six and seven will hash in the same bucket for some other hash function and will then therefore become a candidate pair from whoa.But looking only at this one hashing,they do not form a candidate pair.
2. 也可以对所有bands使用一个hash函数,但是要对每个bands使用独立的桶数组,这样就算不同bands有相同的行也不会hash到同一个bucket中。而且这样lz觉得可能比上面的使用不同hash函数同一个buckets数组更好,不容易产生冲突。
LSH示例

Note:
1. 这里设置了20个bands,且每个band中有5行。signature矩阵的行也称作组件components.
2. 可能比较的paris数目的计算:5,000,000,000个=(100,000 2),即100,000中选出两个,100,000*99999/2.
3. because of the randomness involved in minhashing, the columns C1 and C2 may agree in more or fewer than 80 of their rows but approximately.
假设有两个document,它们对应的Signature Matrix矩阵的列分别为C1,C2,Signature Matrix还是分成20个bands,每个bands有5行
假设C1、C2实际上有80%相似,则:

Note: 0.328是8成相似的两列C1、C2在某个band中完全一样的概率0.8^5,虽然很小,但计算得到C1、C2在20个bands中都不相似的概率为0.00035,几乎为0,也就是说20个bands中总有一个band检测到C1、C2是相似的,并且检测到相似的概率(hash到同一个bucket中的概率)相当大为0.99965。同时0.00035=1/3000,是false negative的概率。
假设C1、C2实际上有40%相似,则:

Note: 可以看出这时有20% false positives,but the false positive rate falls rapidly as the similarity of underlying sets decreases.For example, for 20% Jaccard similarity,we get less than 1% false positives.
假设C1、C2实际上有30%相似,则:
C1中的一个band与C2中的一个band完全一样的概率就是0.3^5=0.00243,那么C1与C2在20个bands至少C1的一个band和C2的一个band一样的概率是1-(1-0.00243)^20=0.0474,换句话说就是,如果这两个document是30%相似的话,LSH中判定它们相似的概率是0.0474,也就是几乎不会认为它们相似。
LSH分析
我们想要的LSH理想情况
设s是2个sets(docs、colums、signatures)真实相似度,t是相似度阈值,共享同一个bucket的概率为1时(也就是两列总是hash到同一bucket中,其应该推断出相似度是100%),那么两列的相似性越大,并且大于这个阈值t,说明两列是相似的(与应该推断出相似度是100%相符)。
简单来说,这个理想阶跃函数的作用是:当两个sets相似度很高时(>t),总是分到同一个bucket中,相反相似度低时,总是不会分到同一个bucket中(分到同一bucket中的概率为0)。
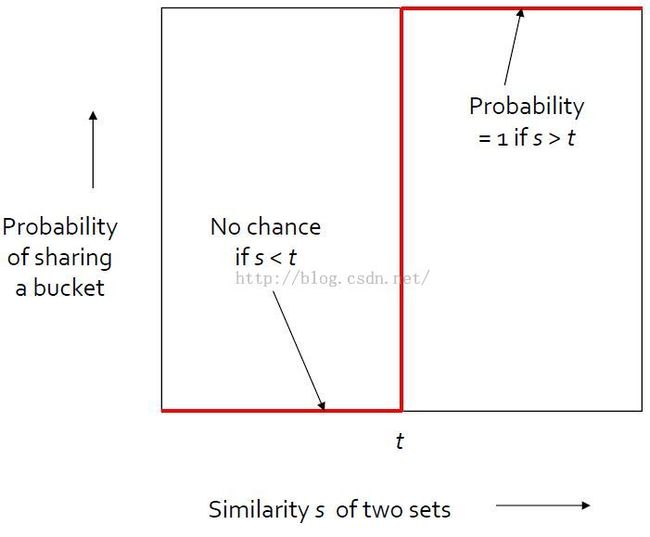
实际情况:分析signature matrix的单行(两列)
阈值为t时的false pos和neg。

Note:
1. 由于the probability of two minhash values equaling the Jaccard similarity of the underlying set,所以单行对应的是图中对角线(红线)。
2. That's not too bad.At least the probability goes in the right direction, but it does leave a lot of false positives and negatives.
False pos和neg的概率大小控制
这些false pos和neg的概率是可以通过选取不同的band数量以及每个band中的row的数量来控制的。b和r越大,也就是signatures的长度(就是原始signature矩阵的行数)越长,S曲线就越接近于阶跃函数,false positives and negatives相应就会减小,但是signatures越长,它们占用的空间的计算量也就变大了。{lz的问题:如果输入的signatures矩阵只有那么大,那么是不是只能通过and/or哈希函数级联来模拟增加b、r大小了?[海量数据挖掘MMDS week7: 局部敏感哈希LSH(进阶)]}The larger we make b and r, that is,the longer the signatures we use,the closer the s curve will be to a step function.And therefore, the fewer false positives and negatives we can have.But the longer we make the signatures,the more space they will take and the more work it will be to perform all the minhashing.
S曲线分析:怎样确定阈值
直接在signature matrix中比较相似度不容易确定threshold,而添加s,r后,可以根据理论很好的设置一个threshold=(1/b)^1/r。
s是2个sets(docs、colums、signatures)真实相似度。则可得出以下概率计算公式:

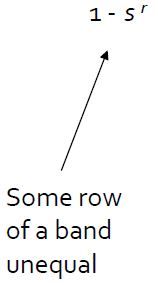


当b和r变大时,函数1-(1-s^r)^b的增长类似一个阶跃函数step function。当阈值在大概(1/b)^1/r这个位置时跳跃。
这个阈值实际上是函数f(S) = (1-S^r)^b的不动点(近似值),也就是输入一个相似度S,得到一个相同的概率p(hash到同一个bucket中的概率)。当相似性相对不动点变大时,其hash到同一个bucket中的概率也变大,反之相似性相对不动点变小时,其hash到同一个bucket中的概率也变小了。Threshold t will be approximately (1/b)^1/r.But there are many suitable values of b and r for a given threshold.

LSH分析实例

Note: The rise from 0.4 to 0.6 is more than 0.6
LSH总结

[Locality Sensitive Hashing 详解]
皮皮blog
LSH的应用(LSH的三个变型)
应用一:entity resolution实体分辨(LSH变型1)
实体分辨会出现很多问题,例如通过人名合并人物可能的问题:people with the same name,so grouping by name will merge records for different people and worse, the same person may have their name written:middle initials,nickname - formal name,misspellings。
匹配消费者记录


Note:
1. We gave 100 points each for identical names, addresses, and phone numbers, so 300 was the top score.only 7,000 pairs of records received this top score, although we identified over 180 thousand pairs that were very likely the same person.Then we penalize differences in these three fields.Completely different names addresses or phones got zero score but small changes gave scores close to 100.
2. small spelling difference in the first names.the score for the name would be 90.If the last names were the same but the first name's completely different the score for the names would be 50.
3. how we set the threshold without knowing ground truth.That is, which pairs of records really were created by the same individuals.this is not a job you can do with machine learning, because there's no training set available.

Note:
1. we used exactly three hash functions.One had a bucket for each possible name.The second had a bucket for each possible address.And the third had a bucket for each possible phone number.Now, the candidate pairs were those placed in the same bucket by at least one of these hash functions.
2. finding those extra missed pairs would probably have cost more than they were worth to either company.
Names, address, phone怎么hash
How do we hash strings such as names so there is one bucket for each string?
第一种hash方法:现实中名字太多,可以不用hash,直接对names进行排序,相同名字的记录就连在一起了,这样之后再去score。How we hash to one bucket for each possible name since there are an infinite number of possible names.But we didn't really hash to buckets,rather we sorted the records by name and then the records with identical names appear consecutively in the list and we can score each pair with identical names.After that we resorted by address and did the same thing with records that had identical addresses.
第二种hash方法:Another option was to use a few million buckets, and deal with buckets that contain several different strings.follow the strategy we used when we did LSH for signatures we could hash say several million buckets and compare all pairs of records within one bucket.如果bucket的数目远远大于数据中实际出现的名字数目,发生冲突的概率是极小的。
结果确认Result validation: score多少分才算sure?


Note:
1. For the identical pairs, we looked at the creation dates at companies A and B.It turns out that there was a 10 day lag on average between the time the record was created by company A and the time that the same person went to company B to begin their service.
2. In order to reduce further the pairs of records we needed to score we only looked at pairs of records where the A record was created between 0 and 90 days before the B record, you'll get an average delay of 45 days.
3. 如果匹配池matches pool中的平均延迟时间lag time是10天(也就是所有都是validated)则有(45-10)/35=100%的是valid,反之,如果平均延迟时间lag time是45天(也就是所有的都超过45天的最长时限,都不是validated)则有(45-45)/35=0%的是valid。
什么数据field可以用于validation?
Any field not used in the LSH could have been used to validate, provided corresponding values were closer for true matches than false.
应用二:Minutiae:A New Way of Bucketing
(并不需要原始的LSH来创建buckets,更不用shingles和minhashing)
Fingerprint Matching指纹匹配
指纹表示

Note: minutiae: particular locations where something interesting happens to the ridges that form a fingerprint.Examples are where two ridges merge into one or where a ridge ends.So, the image of a fingerprint is replaced by a set of coordinates in the two dimensional space where minutiae are located.
指纹匹配中的LSH
通过方格(minutiaes)的集合来表示指纹

Note:
1. The grid must be scaled and orientated properly.
2. Since some minutiae will be right on or near a boundary, it is useful to regard such minutiae as present in the squares on both sides of the boundary.
3. 指纹匹配问题转化:we have reduced the problem of finding matching fingerprints to the problem of finding similar sets of grid squares that have minutiae.
指纹匹配的难点:矩阵是稠密的,Min-Hashing对稀疏矩阵更有效,否则可能分不开不同的指纹。The problem is that the resulting matrix is not sparse.The grid cannot be too fine or it will be unclear where minutiae belong.And as a result,the matrix's rows are the grid squares and its columns or the fingerprints sets will not be sparse.That means min hashing will not work very well.Each min hash will have relatively few different values, so we don't get a good distribution into a large number of buckets when we do the LSH.
Discretizing Minutiaes离散化Minutiaes

Note: 图中交叉点就是一个minutiaes,要加入到指纹表示中,同时其周围很近的方格也要加入到sets中。It appears the point of merger lies within this grid square.So, we add that square to the set representing the fingerprint.we might also want to add the squares that are very close to the exact point of merger, because in another image of the same fingerprint,the grid might be shifted slightly to the left or down.
LSH在指纹中的应用
表示成bit-vector

指纹候选对

Note:
1. 随机选出1024个集合,每个集合中有3个方格。For every LSH, if we pick some member of sets of grid squares or components of the bit-vectors that represent fingerprints.In our example, we'll use 1,024 sets of three grid squares each.For each set of three squares,we look at all the prints that have minutiae in each of these three squares.
2. 如果存在某个集合,两个指纹对应的3个方格都是1,那么这两个指纹就是候选对(要进一步比较是否相同)。
3. 选出的集合就像是LSH中的bucket。但是unlike a hash function, a fingerprint can be placed in many buckets.
LSH/Fingerprint示例

Note:
1. 每个指纹有20%的方格存在minutiaes,两个相同的指纹有80%的方格是agree的。The fact that we place minutiae in nearby squares if they are at the boundary helps make this assumption true.
2. if the fingerprints come from different fingers,then the probability that both prints are placed in this bucket(含3个squares的set) is really tiny.
3. 一个指纹在3个squares中有minutiaes的概率是(0.2)^3,两个指纹就是(0.2)^6.
相同指纹匹配成功概率分析

Note: And by using a larger number of sets of squares and perhaps four or five squares per set,we can reduce the false positive rate substantially while still keeping the false negative rate low.
应用三:A New Way of Shingling: Bucketing by Length
(LSH变型3:变型的shingling技术,实际上并没有使用MinHashing或者LSH)
寻找重复新闻文章
与文档相似度计算的不同点是:there is a special way of shingling that works well when the difference are mostly in the ads associated with the article.We shall also talk about a simple bucketing method that works when the number of sets is not too great.

新闻分辨的难点

minhashing + LSH方法实现
invented a form of shingling that is probably better than the standard approach we covered for those webpages that are of the type we just described.And they invented a simple substitute for LSH that worked adequately well for the scale of problem.They partitioned the pages into groups of similar length and they only compared pages in the same group or nearby groups.
minhashing + LSH运行更快更好:But they found that minhashing + LSH was better as long as the similarity threshold was less than 80%.
Note: 提高效率和减小错误的小tips: do the minhashing row by row,where you compute the hash value for each row number once and for all rather than once for each column.Remember that the rows correspond to the shingles and the columns to the web pages.
特殊的shingling技术

Note:
1. The key observation was to give more weight to the articles themselves than to the ads and other elements surrounding the article.That is, they did not want to identify as similar two articles from the same newspaper with the same ads and other elements, but different underlying stories.
2. buy sudzo是广告,i recommend ...是正文(包含较多stop words)。
3. 根据他们定义的shingle,正文变成shingles是:I recommend that, that you buy...
4. Notice that there are relatively few shingles and it does not guarantee that each word is part of even one shingle.
shingling变型的分析

The reason this notion of shingle makes sense is that it biases the set of shingles for a page in favor of the news article.文章中含有stop words,他们选用的是比较文章而不是广告,So these two pages have almost the same shingles, and therefore have very high Jaccard similarity.
皮皮blog
LSH距离度量方法
Mining Massive Datasets - week2: LSH的距离度量方法
Review复习
Shingles
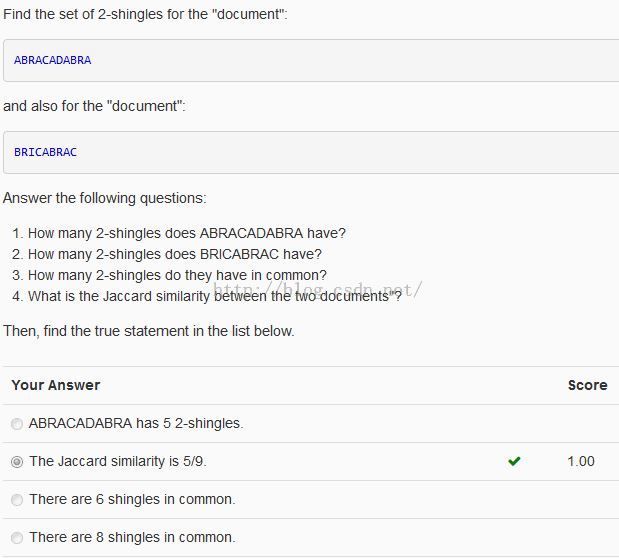
Note:2-shingles for ABRACADABRA : AB BR RA AC CA AD DA 7个
2-shingles for BRICABRAC : BR RI IC CA AB RA AC 7个
2-shingles in common : BR CA AB RA AC 5个
Jaccard similarity: 5/(7+7-5) = 5/9
Min-Hashing

Note: R4得C3-R4;R6得C2-R6;R1过;R3得C4-R3;R5得C1-R5;R2过。
故:C1 C2 C3 C4
R5 R6 R4 R3
LSH

Note: band1中hash到同一bucket中的候选pairs是C1-C4, C2-C5
band2中hash到同一bucket中的候选pairs是C1-C6
band3中hash到同一bucket中的候选pairs是C1-C3, C4-C7
from:http://blog.csdn.net/pipisorry/article/details/48858661
ref:海量数据挖掘MMDS week7: 局部敏感哈希LSH(进阶)