背景:hadoop应该是一个mapreduce框架,它封装了程序分布的细节,使开发者只关注最重要的应用,即
Map 和reduce.本文以单机为基础,略去了一些细节, 剖析了其主要流程。
废话少说,开始实战:
首先写个测试类:

 public
class
WordCount
...
{
public
class
WordCount
...
{
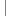

 public static class RegexMapper extends MapReduceBase implements Mapper ...{
public static class RegexMapper extends MapReduceBase implements Mapper ...{
private Pattern pattern;
private int group;
public void configure(JobConf job) ...{
pattern = Pattern.compile(job.get("mapred.mapper.regex"));
group = job.getInt("mapred.mapper.regex.group", 0);
 }
}
public void map(WritableComparable key, Writable value,
OutputCollector output, Reporter reporter) throws IOException ...{
String text = ((UTF8) value).toString();
Matcher matcher = pattern.matcher(text);
while (matcher.find()) ...{
output.collect(new UTF8(matcher.group(group)), new LongWritable(1));
}
}
}
public static class LongSumReducer extends MapReduceBase implements Reducer ...{
public void configure(JobConf job) ...{
}
public void reduce(WritableComparable key, Iterator values,
OutputCollector output, Reporter reporter) throws IOException ...{
long sum = 0;
while (values.hasNext()) ...{
sum += ((LongWritable) values.next()).get();
}
output.collect(key, new LongWritable(sum));
}
public void close() throws IOException ...{
// TODO Auto-generated method stub
}
}
public static void main(String[] args) throws IOException ...{
//NutchConf defaults = NutchConf.get();
JobConf job = new JobConf(WordCount.class);
job.setInputPath(new Path("E:/hadoop_input"));
job.setMapperClass(RegexMapper.class);
job.set("mapred.mapper.regex", "a");
//job.set("mapred.mapper.regex.group", args[3]);
job.setReducerClass(LongSumReducer.class);
job.setOutputPath( new Path("E:/hadoop_output"));
job.setOutputKeyClass(UTF8.class);
job.setOutputValueClass(LongWritable.class);
JobClient.runJob(job);
}
 }
}

我们在这个测试类中定义了自己的map类和reduce类,并实例化一个job,交给JobClent.到此开发者的任务就完成了,下面看看其主要流程:
1)整体概览
1.1)JobClient的静态方法runJob创建一个JobClient实例,实例化的过程中会主
创建一个本地或分布式的runner,在本案中是本地,即一个LocalJobRunner实例
1.2) JobClient的静态方法runJob接着调用JobClient实例的submitJob方法
1.3)JobClient实例的submitJob会调用LocalJobRunner实例的submitJob
1.4) LocalJobRunner实例的submitJob方法会实例化其内部类Job
1.5)上面的Job实例实际上是个线程,在其构造函数中会启动本身这个线程,来完成map和reduce 工作
1.6) JobClient的静态方法runJob会不断地轮循这个线程是否完工,并且打出工作进程报告。
由此可见核心的工作在上面的1.5,其实分为两步,map--->reduce
2)map过程
根据map目录中的文件数逐个实例化MapTask对象,下面的代码一目了然
for
(
int
i
=
0
; i
<
splits.length; i
++
)
...
{
mapIds.add("map_" + newId());
MapTask map = new MapTask(file, (String)mapIds.get(i), splits[i]);
map.setConf(job);
map_tasks += 1;
map.run(job, this);
map_tasks -= 1;
}
核心的两步实例化MapTask和调用其run方法
2.1)在调用run的过程中,首先实例化Sequence类的静态内部类Writer.
在此过程中会产生临时目录/tmp/hadoop/mapred/local/map-xxxxx,xxxxxx是6位小写字母和数字的随机数
目录下是两个文件part-0.out.crc和part-0.out
2.2)实例化一个匿名内部类,该类实现了OutPutCollector接口,用于你写的Map类回调并将结果写入到上面的文件当中
2.3)接着实例化你定义Map类
2.4)实例化MapRunnable的实现类(可配置,默认MapRunner类)Map Runner对你写的Map进行了简单的封 装
2.5)调用MapRunnable实例的run,
2.6)MapRunnable实例的run方法调用你定义的Map类的map方法,传给map方法的是一个个的文档内容
2.7 )自定义的map方法会将文档内容转化成n 个(key value),并调用上面所说的OutPutCollector写入临时文件
map实际上做了一个转换即你输入的一个个文档,转化成一个个(key ,value) ,key是文本中匹配的词,value为1
3)reduce过程
3.1)将上面map输出的临时文件重命名为reduce输入文件
3.2)实例化ReduceTask
3.3)调用ReduceTask实例的run
3.4)实例化自定义的reduce类
3.5)实例化SequenceFile类的内部静态类Sorter开始对输入排序,并启动一个线程监视其排序进程,排序过程将输入文件转化排序文件
3.6)排完序,实例化一个匿名内部类,该类也实现了OutPutCollector接口,
3.7)实例化SequenceFile类的内部静态类Reader来读取排序文件
3.8)实例化ValuesIterator用于遍历排序文件
3.9)调用自定义的reduce类的实例reduce方法,并将结果写到最终的输出文件
reduce过程首先对map 输出的结果进行排序,然后通过ValuesIterator作了个变化使得自定义的reduce的输入是(key ,values),这样有利于reduce.
综合起来看mapreduce是这样一个过程
原始输入的文档,你可以认为是(文档id,文档)-------〉(匹配的词,值(本案为1))这个集合会有重复-------〉排序-------〉转换为(匹配的词,值集合),这个集合没有重复------〉输出