神经网络学习算法matlab应用分析
摘要:为了提高BP神经网络模型运用效果,基于不同方法提出了很多的优化算法算法例如从经典梯度下降法,到复杂的BFGS,LM算法等,然而不同的算法在不同的应用场景有不同的效果,本文以matlab神经网络工具箱为基础,比较各种优化算法在预测分类问题中的应用效果,并分析各种算法优缺点,为神经网络优化算法的选择提供建议。
一、 神经网络基本原理简介
近年来全球性的神经网络研究热潮的再度兴起,不仅仅是因为神经科学本身取得了巨大的进展.更主要的原因在于发展新型计算机和人工智能新途径的迫切需要.迄今为止在需要人工智能解决的许多问题中,人脑远比计算机聪明的多,要开创具有智能的新一代计算机,就必须了解人脑,研究人脑神经网络系统信息处理的机制.另一方面,基于神经科学研究成果基础上发展出来的人工神经网络模型,反映了人脑功能的若干基本特性,开拓了神经网络用于计算机的新途径。它对传统的计算机结构和人工智能是一个有力的挑战,引起了各方面专家的极大关注。
目前,已发展了几十种神经网络[1,2],例如Hopficld模型,Feldmann等的连接型网络模型,Hinton等的玻尔茨曼机模型,以及Rumelhart等的多层感知机模型和Kohonen的自组织网络模型等等。在这众多神经网络模型中,应用最广泛的是多层感知机神经网络。
二、神经网络原理
2.1最速下降学习算法公式推导
基本BP算法包括两个方面:信号的前向传播和误差的反向传播。即计算实际输出时按从输入到输出的方向进行,而权值和阈值的修正从输出到输入的方向进行。

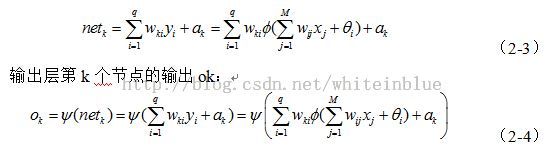
(2)误差的反向传播过程
误差的反向传播,即首先由输出层开始逐层计算各层神经元的输出误差,然后根据误差梯度下降法来调节各层的权值和阈值,使修改后的网络的最终输出能接近期望值。
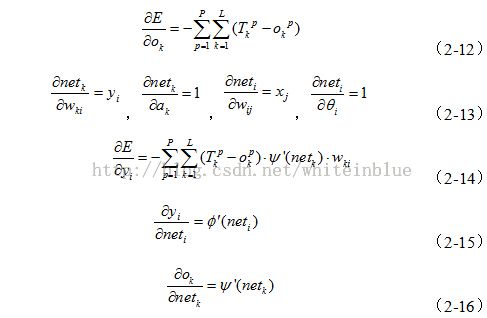

三、 改进神经网络学习算法
3.1附加动量法
附加动量法[3]使网络在修正其权值时,不仅考虑误差在梯度上的作用,而且考虑在误差曲面上变化趋势的影响,类似运动中惯性的作用。在没有附加动量的作用下,网络可能陷入浅的局部极小值,利用附加动量的作用有可能滑过这些极小值。
该方法是在反向传播法的基础上在每一个权值(或阈值)的变化上加上一项正比于前次权值(或阈值)变化量的值,并根据反向传播法来产生新的权值(或阈值)变化。
带有附加动量因子的权值和阈值调节公式为:
附加动量法的实质是将最后一次权值(或阈值)变化的影响,通过一个动量因子来传递。当动量因子取值为零时,权值(或阈值)的变化仅是根据梯度下降法产生;当动量因子取值为1时,新的权值(或阈值)变化则是设置为最后一次权值(或阈值)的变化,而依梯度法产生的变化部分则被忽略掉了。以此方式,当增加了动量项后,促使权值的调节向着误差曲面底部的平均方向变化,当网络权值进入误差曲面底部的平坦区时, di将变得很小,于是![]() ,从而防止了
,从而防止了![]() 的出现,有助于使网络从误差曲面的局部极小值中跳出。
的出现,有助于使网络从误差曲面的局部极小值中跳出。
此外,该算法是以前一次的修正结果来影响本次修正量,当前一次的修正量过大时,式(3-2)第一项的符号将与前一次修正量的符号相反,从而使本次的修正量减小,起到减小振荡的作用; 当前一次的修正最过小时,式(3-2) 第一项的符号将与前一次修正最的符号相同,从而使本次的修正量增大,起到加速修正的作用。可以看出,动量BP算法,总是力图使在同一梯度方向上的修正量增加。因子mc越大,同一梯度方向上的"动量"也越大。
在动量BP 算法中,可以采用较大的学习率,而不会造成学习过程的发散,因为当修正过量时,该算法总是可以使修正量减小,以保持修正方向向着收敛的方向进行; 另一方面,动量BP 算法总是加速同一梯度方向的修正量。上述两个方面表明, 在保证算法稳定的同时,动量BP算法的收敛速率较快,学习时间较短。
根据附加动量法的设计原则,当修正的权值在误差中导致太大的增长结果时,新的权值应被取消而不被采用,并使动量作用停止下来,以使网络不进入较大误差曲面;当新的误差变化率对其旧值超过一个事先设定的最大误差变化率时,也得取消所计算的权值变化。其最大误差变化率可以是任何大于或等于1的值。典型的取值取1.04。所以,在进行附加动量法的训练程序设计时,必须加进条件判断以正确使用其权值修正公式。

3.2自适应学习速率
在最速下降BP算法[4]和动量BP算法中,其学习率是一个常数, 在整个训练的过程中保持不变,学习算法的性能对于学习率的选择非常敏感,学习率过大,算法可能振荡而不稳定;学习率过小,则收敛的速度慢,训练的时间长。而在训练之前,要选择最佳的学习率是不现实的。
事实上,可以在训练的过程中,使学习率随之变化,而使算法沿着误差性能曲面进行修正。自适应调整学习率的梯度下降算法,在训练的过程中,力图使算法稳定, 而同时又使学习的步长尽量地大, 学习率则是根据局部误差曲面作出相应的调整。当误差以减小的方式趋于目标时,说明修正方向正确,可使步长增加,因此学习率乘以增量因子,使学习率增加;而当误差增加超过事先设定值时,说明修正过头,应减小步长,因此学习率乘以缩减因子,使学习率减小,同时舍去使误差增加的前一步修正过程;下式给出一个自适应学习速率的调整公式:
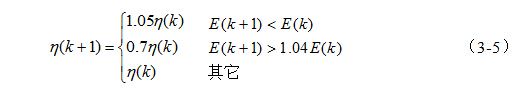
初始学习速率的选取范围可以有很大的随意性。
3.3弹性BP算法。
多层BP网络的隐层一般采用传输函数sigmoid,它把一个取值范围为无穷大的输入变量,压缩到一个取值范围有限的输出变量中。函数sigmoid具有这样的特性当输入变量的取值很大时,其斜率趋向于0,这样在采用最速下降BP法训练传输函数为sigmoid的多层网络时就带来一个问题,尽管权值和阔值离其最佳值相差甚远,但此时梯度的幅度非常小,导致权值和阈值的修正量也很小,这样就使训练的时间变得很长。弹性BP算法的目的是消除梯度幅度的不利影响,所以在进行权值的修正时,仅仅用到偏导的符号,其幅值却不影响权值的修正,权值大小的改变取决于与幅值无关的修正值。连续两次迭代的梯度方向相同时,可将权值和阈值的修正值乘以一个增因子,matlab默认为1.2,使其修正值增加;当连续两次迭代的梯度方向相反时,可将权值和阈值的修正值乘以一个减量因子,matlab默认为0.5,使其修正值减小;当梯度为零时,权值和阀值的修正值保持不变; 当权值的修正发生振荡时,其修正值将会减小。如果权值在相同的梯度上连续被修正,幅度必将增加,从而克服了梯度幅度偏导的不利影响,更新公式如下: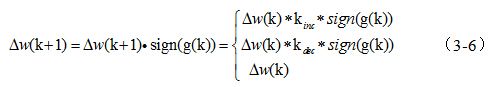
3.4 变梯度算法
最速下降BP算法是沿着梯度最陡下降方向修正权值的,虽然误差函数沿着梯度的最陡下降方向进行修正,误差减小的速度是最快的,但收敛的速度不一定是最快的。在变梯度算法中,沿着变化的方向进行搜索,使其收敛速度比最陡下降梯度方向的收敛速度更快。

3.5 牛顿法
使用导数的最优化算法中,拟牛顿法是目前为止最为行之有效的一种算法,具有收敛速度快、算法稳定性强、编写程序容易等优点。在现今的大型计算程序中有着广泛的应用。本文试图介绍拟牛顿法的基础理论和若干进展。
牛顿法的基本思想是在极小点附近通过对目标函数做二阶Taylor展开,进而找到的极小点的估计值。一维情况下,也即令函数为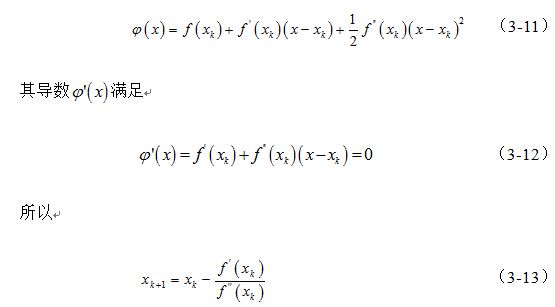

3.6拟牛顿法 (Quasi-Newton Method)
如同上一节指出,牛顿法虽然收敛速度快,但是计算过程中需要计算目标函数的二阶偏导数,难度较大。更为复杂的是目标函数的Hesse矩阵无法保持正定,从而令牛顿法失效。为了解决这两个问题,人们提出了拟牛顿法。这个方法的基本思想是不用二阶偏导数而构造出可以近似Hesse矩阵的逆的正定对称阵, 从而在"拟牛顿"的条件下优化目标函数。构造方法的不同决定了不同的拟牛顿法。
首先分析如何构造矩阵可以近似Hesse矩阵的逆:


3.6.1 DFP算法

3.6.2 BFGS算法

3.6.3 L-BFGS算法

3.7 LM算法
LM算法与拟牛顿法一样,是为了在以近似二阶训练速率进行修正时避免计算Hessian矩阵而设计的。当误差性能函数具有平方和误差(训练前馈网络的典型误差函数)的形式时, Hessian 矩阵可以近似表示为

当系数μ为0时,上式即为牛顿法; 当系数μ的值很大时, 上式变为步长较小的梯度下降法。牛顿法逼近最小误差的速度更快,更精确, 因此应尽可能使算法接近于牛顿法,在每一步成功的迭代后(误差性能减小) ,使μ减小; 仅在进行尝试性迭代后的误差性能增加的情况下,才使μ增加。这样,该算法每一步迭代的误差性能总是减小的。
LM 算法是为了训练中等规模的前馈神经网络(多达数百个连接权)而提出的最快速算法,它对M ATLAB 实现也是相当有效的, 因为其矩阵的计算在MATLAB 中是以函数实现的,其属性在设置时变得非常明确。
四、实验验证
对于一个给定的问题,到底采用哪种训练方法,其训练速度是最快,这是很难预知的,因为这取决于许多因素,包括给定问题的复杂性、训练样本集的数量、网络权值和阈值的数量、误差目标、网络的用途(如用于模式识别还是函数逼近)等
4.1实验原理简介
实验选用神经网络进行语音特征信号识别,根据语音特征信号的特点,构建神经网络的结构。由于语音输入信号有24维,待分类的语音信号共有4类,分别为民歌,古筝,摇滚和流行四类不同的音乐;所以网络结构为24—25—4,即输入有24个节点,隐层有25个节点,输出层有4个节点[5]。
原始的语音数据,共有2000组语音特征信号,从中随机选择1500组数据作为训练数据,用于训练网络;500组数据作为测试数据测试网络的分类能力。算法代码详见附录。
实验电脑配置为服务器主机,性能和运算速度较好;计算速度比一般电脑要快。
实验过程中分为两组,第一组实验,为了体现算法的寻优能力,设置收敛精度为,迭代次数设置为5000;第二组实验,为了体现算法收敛速度快慢,设置收敛精度为,迭代次数为5000。
弹性梯度法和BFGS算法均方差收敛图:

从均方误差值的角度,我们可以看出在误差精度要求很高的条件下,所有算法都没有达到所要求的精度,其中表现比较好的是自适应lr动量法,弹性梯度法,FR共轭梯度法,BFGS算法,LM算法,表现最好的是LM算法;但是从其分类的准确率来看,FR共轭梯度算法和BFGS算法的分类准确率没有弹性梯度法和自适应lr算法高,说明FR共轭梯度算法,BFGS算法和LM算法出现了过拟合现象[6],过小的均方误差反而使网络丧失了灵活性,使其在测试数据集上分类准确率不高。
从算法的训练时间上,在未达到训练要求精度的前提下,全部迭代5000次时;动量项算法所用时间最少;标准bp算法,自适应算法,自适应lr动量法,弹性梯度法,说用时间稍多于动量项算法,说明上述算法相对简单,复杂度低,每次迭代计算量小;此外由时间的均方差可以看出,上述算法计算稳定,对于初始值要求不大。而相比较FR共轭梯度法,SCG算法,BFGS算法,LM算法算法,由于FR共轭算法要对梯度进行搜索,BFGS算法,LM算法要对Hesse阵进行近似计算,所以算法的复杂度较高,迭代时间比较长;此外,从其比较大的标准差可以看出,FR共轭梯度法,SCG算法,BFGS算法,LM算法在时间上不稳定,算法对初值比较敏感,好的初始值能够是算法的迭代时间明显的降低。
在分类准确率上,我们依据分类结果,其中标准bp算法,动量项算法的准确率在65%左右,属于分类结果最差;说明标准bp算法,动量项算法在有限的迭代次数下是欠拟合的,增加迭代次数到1000次,准确率达到了0.7407,均方误差达到了0.104。其他算法都达到了很好的准确率,其中弹性度法,更是达到了93%的最高水平,说明仅仅依据梯度值,进行寻优迭代是不够理想的;而忽略梯度的幅度值,依靠梯度方向的弹性梯度法得到了很好的结果,说明梯度迭代方法迭代步长和迭代幅度值上面,需进行好的组合再能达到好的结果。FR共轭梯度法,SCG算法,BFGS算法,LM算法由于其复杂的迭代过程,保证了每一步迭代都选取很好的步长和梯度幅值,使得此类算法收敛快,结果较好。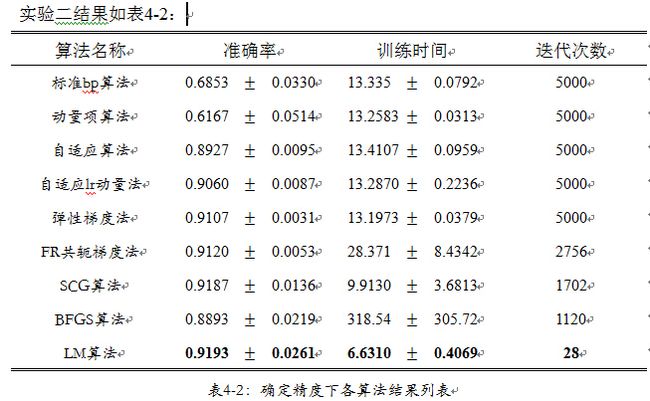
有上表的结果,可以看出,在准确率、训练时间、迭代次数3个指标上面,LM算法都达到了最好的水平,其中计算时间和迭代次数更是称倍地减小;说明LM算法是所有算法中均方误差收敛最快的算法。标准bp算法,动量项算法,自适应算法,弹性梯度法等算法在有限次迭代内,没有达到均方误差收敛条件,说明其迭代收敛速度较慢。
在迭代运算过程中,共轭梯度法,SCG算法,BFGS算法均方误差在减小到一定程度后,算法初选震荡现象;已知算法的均方误差不在下降,梯度值反复交换,知识迭代陷入循环;说明共轭梯度法,SCG算法,BFGS算法这些快速收敛算法,容易陷入死循环,而导致算法停止继续寻优。此外,实验二共轭梯度法,SCG算法,BFGS算法结果,同实验一种结果对比发现,实验二提前停止迭代后,网络的识别准确率有了提高,说明提前结束迭代,可以起到防止过拟合的作用。
五、BP 网络的局限性
在人工神经网络的应用中,绝大部分的神经网络模型采用了BP 网络及其变化形式,但这并不说明BP 网络是尽善尽美的,其各种算法依然存在一定的局限性。BP 网络的局限性主要有以下几个方面[7]:
(1 )学习率与稳定性的矛盾
梯度算法进行稳定学习要求的学习率较小,所以通常学习过程的收敛速度很慢。附加动量法通常比简单的梯度算法快,因为在保证稳定学习的同时,它司以采用很高的学习率,但对于许多实际应用,仍然太慢。以上两种方法往往只适用于希望增加l训练次数的情况。
如果有足够的存储空间,则对于中、小规模的神经网络通常可采用LM算法;如果存储空间有问题,则可采用其他多种快速算法,例如对于大规模神经网络采用SCG或弹性算法更合适。
(2 ) 学习率的选择缺乏有效的方法
对于非线性网络,选择学习率也是一个比较困难的事情。对于线性网络,我们知道,学习率选择得太大,容易导致学习不稳定; 反之,学习率选择得太小, 则可能导致无法忍受的过长的学习时间。不同于线性网络,我们还没有找到一种简单易行的方法,以解决非线性网络选择学习率的问题。对于快速训练算法,其默认参数通常留有余量。
(3 ) 训练过程可能陷于局部最小
从理论上说,多层BP 网络可以实现任意可实现的线性和非线性函数的映射,克服了感知器和线性神经网络的局限性。但在实际应用中, BP 网络往往在训练过程中,也可能找不到某个具体问题的解,比如在训练过程中陷入局部最小的情况。当BP 网络在训练过程中陷入误差性能函数的局部最小时,可以通过改变其初始值,并经多次训练,以获得全局最小。
(4 )没有确定隐层神经元数的有效方法
如何确定多层神经网络隐层的神经元数也是一个很重要的问题,太少的隐层神经元会导致网络"欠适配",太多的隐层神经元又会导致"过适配" 。