oracle 物理结构之redo log
一、重做日志文件的作用:
1、 记录所有数据的改变
2、 提供恢复机制
3、 组方式管理(最少两组,默认为3组,每组一个重做日志文件, oracle官方建议,所有的每组重做日志文件大小最好相同;当然如果是为重做日志文件组添加成员的时候不能指定大小,因为每个重做日志文件相互冗余,所以必须一致)
二、重做日志文件状态
通过lgwr写到日志文件里面


日志组1写满了,就会切换到日志组2,然后到3;3再到1,循环使用。反正日志组是不停的工作。
重做日志文件一般具有4种状态(也可以分为6种)
1、 unused:说明此重做日志文件组没被用过
2、 current:说明是当前重做日志组,lgwr正在写
3、 active:说明此重做日志文件组刚写完,记录在重做日志文件组中的事务所造成的数据块的改变,没有完全从缓冲区写入到数据文件,重做日志文件组属于这种状态,是不允许被覆盖的,一旦写完成,就变问inactive状态。
4、 inactive:说明记录在重做日志文件组中的事务所造成的数据块的改变,已经从缓冲区写入到数据文件,这种状态允许被覆盖。
上面4中状态是重做日志文件常见的状态,下面两种状态是在重做日志组损坏或者特殊情况下的状态。
5、clearing:说明该重做日志文件正被重建(重建后状态变为unused)
6、clearing_cyrrent:说明此重做日志文件重建是出现错误
下面是日志大小设置问题
日志文件设置大小问题,值得我们思考
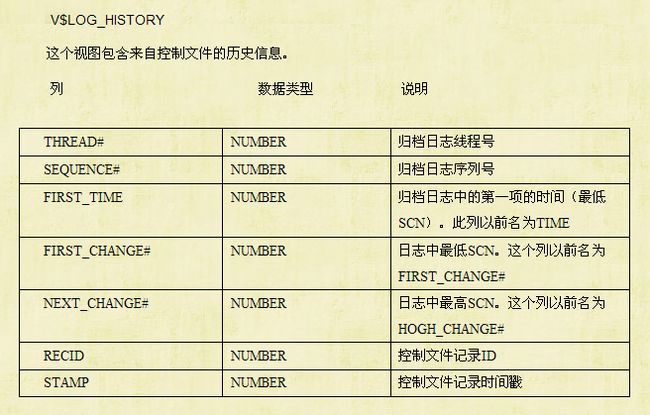
v$log_history 这个动态视图查询日志切换的频率,根据这个频率来判断日志的大小是否合适
SQL> desc v$log_history;
Name Null? Type
----------------------------------------- -------- ----------------------------
RECID NUMBER
STAMP NUMBER
THREAD# NUMBER
SEQUENCE# NUMBER
FIRST_CHANGE# NUMBER
FIRST_TIME DATE
NEXT_CHANGE# NUMBER
RESETLOGS_CHANGE# NUMBER
RESETLOGS_TIME DATE
日志组空间太小的话,第一会导致dbwr写的频率增加,增加了i/o;第二会造成事务的等待,延长事务周期,导致数据库假死,后果严重。
如果太大的话,记录的事务多了,这时日志文件损坏,丢失数据就会很多;如果发生崩溃,那么redo的时间会很长。(原因:数据在修改时不是直接写入datafile,而是操作记录在redo log,当ckpt发生,他才会从redo log读取已经修改的数据,写入datafile,而要想让他写入datafile的条件之一就是日志切换,如果不考虑其他条件,只有等日志切换时,才会写入datafile,一般情况下没事,但是发生日志损坏)
还有要考虑业务的繁忙程度,按照最忙的时候去设置日志的大小
总之一句话要保证lgwr有可写的日志组去写日志。按照官方建议,日志切换时间一般在10-15分钟比较适合
三、下面是一些基本概念
1、重做日志组(Redo Log Group)
日志组由一组完全相同的重做日志文件组成,每个日志组至少包含一个重做日志文件。如果一个日志组包含多个重做日志文件,后台进程LGWR会将相同的事务变化写入到同一个日志组的各个重做日志文件中。日志组汇总的每个重做日志文件都被称为日志成员,同一个日志组中所有日志成员都具有相同的日志序列号和尺寸。
2、重做日志条目(Redo Entry)
重做记录,由一组变化向量组成,这些变化向量包含表块变化(快位置、变化数据)、UNDO块变化和UNDO事务表的变化。
3、lgwr发生的条件
http://blog.csdn.net/yujin2010good/article/details/7709120
LGWR,用于将重做日志缓冲区所记载的全部内容写入到重做日志文件中。
Oracle 总是“先日志后修改”(先记载变化然后修改数据);
在DBWR工作之前,LGWR首先将事务变化写入到重做日志。
LGWR工作触发条件:
1、提交事务(commit)
2、每隔3秒钟
3、当重做日志信息超过1M
4、重做日志缓冲区超过1/3满
4、SCN(System Change Number)
SCN用于标识数据变化的唯一标识号,其数值顺序递增。执行事务操作时,系统会为每个事务变化生成相应的SCN.
基本上是发生dml操作时scn+1,正常关闭或者commit时也scn+1
5、日志序列号
日志序列号是重做日志的使用标识号,其数值也是循序递增的,当进行日志切换时,日志序列会自动增一,并将该信息写入到控制文件中去。

6、重做线程(Redo Thread)
重做线程由一组相关的重做日志组成。对于单实例的数据库系统来说,只有一个重做线程,而对于RAC(Real Application Cluster)来说,多个实例会同时访问数据库,并 且每个实例都有独立的重做线程。

7、日志切换
日志切换至后台进程LGWR停止写一个日志组,并开始写另一个日志组的事件,默认情况下,当日志组写满后,后台进程LGWR会自动进行日志切换。
当日志切换时,当前日志序列号会自动递增
也有手工切换日志
SQL> alter system switch logfile;
System altered.
SQL> select * from v$log;
GROUP# THREAD# SEQUENCE# BYTES BLOCKSIZE MEMBERS ARC
---------- ---------- ---------- ---------- ---------- ---------- ---
STATUS FIRST_CHANGE# FIRST_TIM NEXT_CHANGE# NEXT_TIME
---------------- ------------- --------- ------------ ---------
1 1 10 52428800 512 1 YES
ACTIVE 1137238 08-JUL-12 1139309 08-JUL-12
2 1 11 52428800 512 1 NO
CURRENT 1139309 08-JUL-12 2.8147E+14
3 1 9 52428800 512 1 YES
INACTIVE 1132531 08-JUL-12 1137238 08-JUL-12
SQL> alter system switch logfile;
System altered.
SQL> select * from v$log;
GROUP# THREAD# SEQUENCE# BYTES BLOCKSIZE MEMBERS ARC
---------- ---------- ---------- ---------- ---------- ---------- ---
STATUS FIRST_CHANGE# FIRST_TIM NEXT_CHANGE# NEXT_TIME
---------------- ------------- --------- ------------ ---------
1 1 10 52428800 512 1 YES
ACTIVE 1137238 08-JUL-12 1139309 08-JUL-12
2 1 11 52428800 512 1 YES
ACTIVE 1139309 08-JUL-12 1139367 08-JUL-12
3 1 12 52428800 512 1 NO
CURRENT 1139367 08-JUL-12 2.8147E+14
SQL> alter system archive log current;(手动归档)
System altered.
SQL> select * from v$log;
GROUP# THREAD# SEQUENCE# BYTES BLOCKSIZE MEMBERS ARC
---------- ---------- ---------- ---------- ---------- ---------- ---
STATUS FIRST_CHANGE# FIRST_TIM NEXT_CHANGE# NEXT_TIME
---------------- ------------- --------- ------------ ---------
1 1 13 52428800 512 1 NO
CURRENT 1139443 08-JUL-12 2.8147E+14
2 1 11 52428800 512 1 YES
ACTIVE 1139309 08-JUL-12 1139367 08-JUL-12
3 1 12 52428800 512 1 YES
ACTIVE 1139367 08-JUL-12 1139443 08-JUL-12
日志切换是,chpt发出checkpoint,然后促使scn写入控制文件和数据文件头,lgwr写完之后,dbwr开始把缓冲区脏数据写入数据文件。
当数据块处于归档模式时,日志切换时促使后台进程arch讲日志内容保存到归档日志
如下:
# pwd
/oracle/products/diag/rdbms/wolf/wolf/alert
# ls
log.xml
# tail -f log.xml
<txt>Completed checkpoint up to RBA [0xd.2.10], SCN: 1139443
</txt>
</msg>
<msg time='2012-07-08T21:35:06.308-05:00' org_id='oracle' comp_id='rdbms'
client_id='' type='UNKNOWN' level='16'
host_id='oracle' host_addr='192.168.8.254' module=''
pid='6160592'>
<txt>Incremental checkpoint up to RBA [0xd.273.0], current log tail at RBA [0xd.2aa.0]
</txt>
</msg>
<msg time='2012-07-08T21:44:00.575-05:00' org_id='oracle' comp_id='rdbms'
client_id='' type='UNKNOWN' level='16'
host_id='oracle' host_addr='192.168.8.254' module='sqlplus@oracle (TNS V1-V3)'
pid='14680092'>
<txt>ALTER SYSTEM ARCHIVE LOG
</txt>
</msg>
<msg time='2012-07-08T21:44:00.713-05:00' org_id='oracle' comp_id='rdbms'
client_id='' type='UNKNOWN' level='16'
host_id='oracle' host_addr='192.168.8.254' module=''
pid='6357218'>
<txt>Beginning log switch checkpoint up to RBA [0xe.2.10], SCN: 1140448
</txt>
</msg>
<msg time='2012-07-08T21:44:00.713-05:00' org_id='oracle' comp_id='rdbms'
client_id='' type='UNKNOWN' level='16'
host_id='oracle' host_addr='192.168.8.254' module=''
pid='6357218'>
<txt>Thread 1 advanced to log sequence 14 (LGWR switch)
</txt>
</msg>
<msg time='2012-07-08T21:44:00.713-05:00' org_id='oracle' comp_id='rdbms'
client_id='' type='UNKNOWN' level='16'
host_id='oracle' host_addr='192.168.8.254' module=''
pid='6357218'>
<txt> Current log# 2 seq# 14 mem# 0: /oracle/products/oradata/wolf/redo02.log
</txt>
</msg>
<msg time='2012-07-08T21:44:00.890-05:00' org_id='oracle' comp_id='rdbms'
client_id='' type='UNKNOWN' level='16'
host_id='oracle' host_addr='192.168.8.254' module='sqlplus@oracle (TNS V1-V3)'
pid='14680092'>
<txt>Archived Log entry 10 added for thread 1 sequence 13 ID 0xffffffffdfbf1c80 dest 1:
</txt>
</msg>
<msg time='2012-07-08T21:49:47.708-05:00' org_id='oracle' comp_id='rdbms'
client_id='' type='UNKNOWN' level='16'
host_id='oracle' host_addr='192.168.8.254' module=''
pid='6160592'>
<txt>Completed checkpoint up to RBA [0xe.2.10], SCN: 1140448
</txt>
</msg>
<msg time='2012-07-08T22:05:15.112-05:00' org_id='oracle' comp_id='rdbms'
client_id='' type='UNKNOWN' level='16'
host_id='oracle' host_addr='192.168.8.254' module=''
pid='6160592'>
<txt>Incremental checkpoint up to RBA [0xe.295.0], current log tail at RBA [0xe.b9b.0]
</txt>
</msg>
8、检查点
检查点(Checkpoint)是一个数据库事件,它拥有同步数据库的所有数据文件,控制文件和重做日志。当发出检查点时,后台进程CKPT会将检查点时刻的SCN(System Change Number)写入到控制文件和数据文件头部,同时促使后台进程DBWR将所有的脏缓冲区写入到数据文件中。当Oracle发出检查点时,后台进程CKPT促使后台进程DBWR开始工作,而后台进程DBWR又促使后台进程LGWR开始工作。因为当发出检查点时CKPT、DBWR、LGWR同时工作,所以数据文件、控制文件和重做日志的SCN完全一致,从而使三种数据库文件保持完全同步。
Chpt反生-------他会叫dbwr写-------他会叫lgwr写------lgwr他写完了---dbwr在写-写完
日志切换,日志组写满后,后台进程lgwr会进行日志切换,切换时,系统会促使后台进程ckpt发出checkpoint。
关闭数据库,正常关闭数据库,后台进程会发出检查点,而且要检查点完成之后才关闭数据库,就是上面的一个流程走完。
alter system switch logfile;一般在备份的时候,为了把脏数据块写入数据文件,就手工执行命令,强制ckpt发出checkpoint。
Fast_start_mttr_target,手工指定恢复最大时间,(如果人为设置不科学)当然oracle也会根据参数去调整。
9、实例恢复
实例恢复是指当出现实例失败时有后台进程SMON自动同步数据文件、控制文件和重做日志并打开数据库的过程。
Smon实例恢复过程:
1)确定不同步的物理文件。通过比较数据文件、控制文件和重做日志的SCN,后台进程SMON可以确定哪些文件处于不同步状态。
2)REDO.确定了不同步的数据文件后,SMON会重新应用哪些在数据文件未执行的事务操作,并且DBWR会将提交和未提交的数据写到数据文件及UNDO段上。
3)REDO之后会打开数据库,此时客户应用可以访问数据库。
4)UNDO。在第二步后,数据文件既包含被提交的数据,也包含被提交的数据。打开数据库后,SMON会自动使用UNDO段取消未提交的数据。
四、基本操作
(建议日子切换时间在15-30分钟之间,太短了日志可能归档来不及,太长了,恢复时间增加了)
1) 查看当前日志
SQL> select * from v$log;
2) 查看日志文件路径
SQL> select * from v$logfile;
3) 手动强制切换日志
SQL> alter system switch logfile;
4) 手动归档
SQL> alter system archive log current;
5) 查看历史文件
SQL> select * from v$log_history;
desc v$log_history
select SEQUENCE#,to_char(FIRST_TIME,'yyyy-mm-ddhh24:mi:ss') from v$log_history;
6) 查看归档模式
SQL> select log_mode from v$database;
SQL> archive log list;
7) 增加日志组
SQL> col member for a50
SQL> select * from v$logfile;
GROUP# STATUS TYPE MEMBER
---------- ------- ------- --------------------------------------------------
IS_
---
3 ONLINE /oracle/products/oradata/wolf/redo03.log
NO
2 ONLINE /oracle/products/oradata/wolf/redo02.log
NO
1 ONLINE /oracle/products/oradata/wolf/redo01.log
NO
SQL> alter database add logfile '/oracle/products/oradata/wolf/redo04.log' size 50m;
Database altered.
SQL> select * from v$logfile;
GROUP# STATUS TYPE MEMBER
---------- ------- ------- --------------------------------------------------
IS_
---
3 ONLINE /oracle/products/oradata/wolf/redo03.log
NO
2 ONLINE /oracle/products/oradata/wolf/redo02.log
NO
1 ONLINE /oracle/products/oradata/wolf/redo01.log
NO
GROUP# STATUS TYPE MEMBER
---------- ------- ------- --------------------------------------------------
IS_
---
4 ONLINE /oracle/products/oradata/wolf/redo04.log
NO
SQL> alter database add logfile group 6 '/oracle/redo06.log' size 50m;
上面两种方法都可以添加日志组,不多截图了,占空间。
当然日子组的个数也是有限制的。查看限制也有几种方法
盖总写的

自己按照这个方法去找,没找到,谁帮忙看看?(trace)
SQL> show parameter user_dump_dest
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
user_dump_dest string /oracle/products/diag/rdbms/wo
lf/wolf/trace
SQL> alter system set events 'immediate trace name controlf level 10'
Database altered.
8)删除日志组
SQL> alter database drop logfile group 6;
9) 增加和删除日志成员
alter database add logfile member '/oracle/redo09.log' to group 5;
alter database add logfile member '/oracle/redo10.log' to group 5;
SQL> alter database drop logfile member '/oracle/redo10.log';
在oracle里面删除之后,文件需要手动去删除
10) 移动日志文件或者修改名字
SQL> alter database rename file '/oracle/products/oradata/wolf/redo04.log' to '/oracle/redo04.log';
移动之后目录下redo04.log文件还存在,需要手动删除
11) 如果日志文件发生损坏或者丢失,试用下面的命令恢复
SQL> alter database clear logfile group 5;
SQL> alter database clear logfile group 4;
这里强调一下一定要注意一个问题:无论是移动还是删除日志,日志组的时候一定要看清楚是否是inactive,不然可能报错
SQL> startup force;
\ORACLE instance started.
Total System Global Area 1570009088 bytes
Fixed Size 2207128 bytes
Variable Size 1090519656 bytes
Database Buffers 469762048 bytes
Redo Buffers 7520256 bytes
Database mounted.
ORA-03113: end-of-file on communication channel
Process ID: 8978452
Session ID: 191 Serial number: 3
欢迎加入qq群:
119224876(db china联盟),233065499(db china联盟),229845401(虚拟化-云计算-物联网)