【转】NTFS Sparse Files For Programmers(稀疏文件)
NTFS Sparse Files For Programmers
- Sparse Files - What Is It?
- What MSDN Doesn't Tell About Sparse Files
- Programming Considerations
- Downloads
Sparse Files - What Is It?
Imagine that you are implementing a virtual drive that is based on a regular NTFS file. In fact, such drives are quite common, just look on those numerous file-based 'virtual encrypted disks'.
What if a user requests creation of a drive, say, 10 Gb large? You have two options - either pre-allocate 10 gigabytes of storage no matter how much is actually used, or implement a rather complex storage allocation system, allowing the base file to grow and shrink dynamically.
Both the alternatives don't look especially good. Pre-allocation wastes a lot of space, and shrinking the file on-the-fly will likely be a very time-consuming operation.
Fortunately, Windows 2000 and later systems offer a better solution: sparse files. When you need to free a chunk of in-file storage, you just tell the system that that part of the file is no more used, and the system will free the corresponding actual disk space. This way a file can allocate hundreds of gigabytes, but occupy only a few kilobytes of physical storage. The FlexHEX tour shows an example of 250 megabyte large file which uses only 64 kb of disk space.
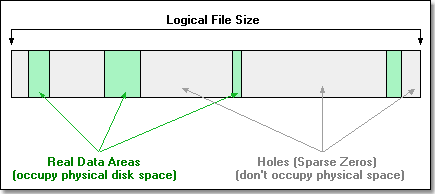
Note that a sparse file is still fully usable by customary applications. When a program attempts reading from a 'hole' area, the system fills the read buffer with zeros. For the program this operation will look as successful reading of a zero data block.
However a program that can distinguish between real data and sparse zero areas, may have significant advantages over a sparse-unaware application. Imagine a terabyte large sparse file - a sparse-aware program will load, copy, or scan such a file in no time, whereas a customary application will either require ages to process a file that large, or just fail completely.
What MSDN Doesn't Tell About Sparse Files
The Actual Sparse File Layout
Although you can declare any area as sparse using the FSCTL_SET_ZERO_DATA control code, the system considers this simply as a recommendation, which it doesn't have to follow. Windows will rearrange the actual sparse area layout as it sees fit (our FAQ mentions this effect).
When it comes to a compressed or a sparse file, NTFS divides the file into chunks called compression units . If a chunk occupies a disk area of the same size, then the disk area contains uncompressed data. If the allocated space is less than the compression unit size, then the data is compressed. If the compression unit has no corresponding disk clusters, then it contains sparse zeros.
It is obvious that a sparse zero area is always aligned to the nearest compression unit boundaries (if it is not, NTFS considers the unit compressed, not sparse). So the question is: "How large the compression unit is?". The number of disk clusters per compression unit may vary for different files, and even for different streams of the same file, however NTFS seems to use the same value of sixteen clusters per unit for all data streams. Remembering that NTFS hard drives are formatted with a cluster size of 4kb by default, the typical compression unit size is 64kb.
For example, if your file contains a sparse zero area 60000 bytes long followed by a single real data byte, the resulting file will contain 60001 bytes of data and no sparse zeros at all.
If you create a file containing 70000 sparse zero bytes followed by a real byte, the resulting file will have a sparse zero area 65536 bytes long followed by (70001 - 65536) = 4465 bytes of real data.
Can They Really Be That Large?
Jeffrey Richter and Luis Felipe Cabrera in their article "A File System for the 21st Century " in November 1998 MSJ issue wrote about sparse streams: "Since a stream can hold as many as 16 billion billion bytes..." . This is not exactly true. You can create a largest possible 16 terabyte sparse file if and only if it consists of a single sparse zero area, no data at all. Writing even a single data byte drops the size limit far, far below. The exact limit depends on many factors: availability of system resources, the layout of the real data areas, even the order of the I/O requests; in some cases the limit may be as low as several hundreds gigabytes. If you don't mind experimenting, you can use FlexHEX to find your system limit.
It is probably safe to assume that you always can create a 300-500 gigabyte large sparse file, but any attempt to create a larger file might result in the Disk full error, no matter how little real data have been written. An amusing fact is that you may get this error even when you are marking some area as a hole, thus releasing physical storage.
This does look strange because NTFS does not have any such limitation, and decoding the data runs of a sparse stream is no more complex than obtaining the cluster list for an ordinary file. Obviously Microsoft didn't believe anybody would ever need a terabyte-large file, and never cared about efficient implementation.
"640 kilobytes of computer memory ought to be enough for anybody."
Programming Considerations
In order to improve readability, the code examples below don't include any error processing. You should add some error checks if you want to use this code in your program.
The Win32 API function GetVolumeInformation returns a set of file system flags that you can analyze to determine if the drive supports sparse streams.
char szVolName[MAX_PATH], szFSName[MAX_PATH];
DWORD dwSN, dwMaxLen, dwVolFlags;
::GetVolumeInformation("C://", szVolName, MAX_PATH, &dwSN,
&dwMaxLen, &dwVolFlags, szFSName, MAX_PATH);
if (dwVolFlags & FILE_SUPPORTS_SPARSE_FILES) {
// File system supports sparse streams
}
else {
// Sparse streams are not supported
}
Determining If A File Is Sparse
In order to check if a file is sparse, use GetFileAttributes , GetFileAttributesEx , or GetFileInformationByHandle functions. Note, however, that the two former functions return the attributes of the unnamed stream. That is, if a file consists of a monolithic main stream, and a sparse alternate stream , both GetFileAttributes and GetFileAttributesEx will report the file as not sparse. If your application is stream-aware and can work with sparse alternate streams, you should use GetFileInformationByHandle .
HANDLE hFile = ::CreateFile("C://Sparse.dat:alt", GENERIC_READ,
0, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL);
BY_HANDLE_FILE_INFORMATION bhfi;
::GetFileInformationByHandle(hFile, &bhfi);
if (bhfi.dwFileAttributes & FILE_ATTRIBUTE_SPARSE_FILE) {
// Sparse stream
}
else {
// Monolithic stream
}
For example, FlexHEX shows a composite sparse attribute in its File Properties window. To find the actual attribute, it calls GetFileInformationByHandle for each stream of the file, and reports the file as sparse if it has one or more sparse streams.
Marking The File As Sparse
Use the DeviceIoControl function with the FSCTL_SET_SPARSE control code to mark the file as sparse:
HANDLE hFile = ::CreateFile("C://Sparse.dat", GENERIC_WRITE,
0, NULL, CREATE_NEW, FILE_ATTRIBUTE_NORMAL, NULL);
DWORD dwTemp;
::DeviceIoControl(hFile, FSCTL_SET_SPARSE, NULL, 0, NULL, 0, &dwTemp, NULL);
If you don't mark the file as sparse, the FSCTL_SET_ZERO_DATA control code will actually write zero bytes to the file instead of marking the region as sparse zero area.
Note that marking a file as sparse is a one-way operation. You cannot unmark a sparse file even if it contains no sparse area; the only way to convert the file back to the non-sparse state is to recreate it from the scratch.
Converting A File Region To A Sparse Zero Area
No trouble here. Just specify the starting and the ending address (not the size!) of the sparse zero block:
FILE_ZERO_DATA_INFORMATION fzdi;
DWORD dwTemp;
fzdi.FileOffset.QuadPart = uAddress;
fzdi.BeyondFinalZero.QuadPart = uAddress + uSize;
::DeviceIoControl(hFile, FSCTL_SET_ZERO_DATA,
&fzdi, sizeof(fzdi), NULL, 0, &dwTemp, NULL);
Note, however, that this operation does not perform actual file I/O, and unlike the WriteFile function, it does not move the current file I/O pointer or sets the end-of-file pointer. That is, if you want to place a sparse zero block in the end of the file, you must move the file pointer accordingly using the SetFilePointer function and call the SetEndOfFile function, otherwise DeviceIoControl will have no effect.
You may ask: "What if we set a new end-of-file marker without calling DeviceIoControl ?", for example, by executing the following function calls:
::SetFilePointer(hFile, 0x1000000, NULL, FILE_END); ::SetEndOfFile(hFile);
What will we find in those 16 megabytes between the old and the new end-of-file markers? Sparse zeros, real zeros, just some junk? The right answer is: sparse zeros. You don't need to call DeviceIoControl/FSCTL_SET_ZERO_DATA to create a sparse zero block in the end of the file - simply moving the end-of-file marker will do the trick.
The last thing worth mentioning is that we can use FSCTL_SET_ZERO_DATA on a non-sparse file as well. MSDN states that "It is equivalent to using the WriteFile function to write zeros to a file." This is not quite correct though - unlike WriteFile , FSCTL_SET_ZERO_DATA affects neither the current file I/O pointer, nor the end-of-file marker - exactly as in the case of the sparse file. For instance, if you call WriteFile immediately after FSCTL_SET_ZERO_DATA , it will overwrite the just written zeros.
Querying The Sparse File Layout
Not much of a problem either - just specify what range you wish to query and provide a sufficient buffer for output info. The following example prints the positions and sizes of allocated blocks in a sparse file.
// The uFileSize variable (either 32- or 64-bit long)
// contains the size of the file being queried.
FILE_ALLOCATED_RANGE_BUFFER queryrange; // Range to be examined
FILE_ALLOCATED_RANGE_BUFFER ranges[1024]; // Allocated areas info
DWORD nbytes, n, i;
BOOL br;
queryrange.FileOffset.QuadPart = 0; // File range to query
queryrange.Length.QuadPart = uFileSize; // (the whole file)
do {
// We assume in this example that the only possible error is
// ERROR_MORE_DATA so there is no need to check the actual error code.
br = ::DeviceIoControl(hFile, FSCTL_QUERY_ALLOCATED_RANGES,
&queryrange, sizeof(queryrange),
ranges, sizeof(ranges), &nbytes, NULL);
// Calculate the number of records returned and print them
n = nbytes / sizeof(FILE_ALLOCATED_RANGE_BUFFER);
for (i=0; i<n; i++)
printf("Address: %I64u/tSize: %I64u/n",
ranges[i].FileOffset.QuadPart,
ranges[i].Length.QuadPart);
// Set starting address and size for the next query
if (!br && n > 0) {
queryrange.FileOffset.QuadPart = ranges[n-1].FileOffset.QuadPart +
ranges[n-1].Length.QuadPart;
queryrange.Length.QuadPart = (LONGLONG)uFileSize -
queryrange.FileOffset.QuadPart;
}
} while (!br); // Continue loop if ERROR_MORE_DATA
Note that FSCTL_QUERY_ALLOCATED_RANGES returns the positions of allocated areas, not the positions of non-zero areas. An allocated area may consist of zeros as well; the only question that matters is whether any given area occupies physical storage or not.
Determining the Actual File Size
In order to determine the actual file size, that is the amount of physical storage being used by the file, just sum up all the file ranges. In the example code above ranges is the array of the ranges, and n contains the number of ranges, so the code for finding the actual size may look as follows:
ULONGLONG uSize = 0; for (i=0; i<n; i++) uSize += ranges[i].Length.QuadPart;
Downloads
All the content is provided on the "as is" basis and without any warranty, express or implied. You can use the supplied tools and examples for any commercial or non-commercial purpose without charge. You can copy and redistribute these tools and examples freely, provided that you distribute the original umodified archives.
sparse.zip - Visual C++ source code for a sparse file enabled Copy Stream utility. As the original utility, it performs stream-to-stream copy, however if the source stream is sparse, the target stream will also be sparse.
参考:
原始链接:http://www.flexhex.com/docs/articles/sparse-files.phtml#prog
有个参照该文的“稀疏文件”的中文介绍:http://www.cppblog.com/lonestep/archive/2007/10/12/34027.html
百度百科中:http://baike.baidu.com/view/1520961.html?fromTaglist
用途:“稀疏文件被普遍用来磁盘图像,数据库快照,日志文件,还有其他科学运用上。”
另一个相关的概念是文件空洞:
http://blogold.chinaunix.net/u2/72383/showart_1432837.html
1. 文件是可以有空洞的,空洞不占用磁盘空间,但是我们用ls查看的文件大小是将空洞算在内的。
2. cp命令拷贝的文件,空洞部分不拷贝,所以生成的文件同样占用磁盘空间小
3. 用read读取空洞部分读出的数据是0,所以如果用read和write拷贝一个有空洞的文件,那么最终得到的文件没有了空洞,空洞部分都被0给填充了,文件占用的磁盘空间就大了。不过文件大小不变。