java面试笔试题目面试题目收集中-第一集
整理这个试题,主要是笔试面试要用,随后希望能不断的更新。由于内容可能会涉及很多,份几部分逐渐补充,经常看看这些题目,有时候做下练习,补补基础很是有益啊。
1. 在类设计中,类的成员变量要求仅仅能够被同一package下的类访问,请问应该使用下列哪个修辞词
A. protected
B. public
C. private
D. 不需要任何修辞词
答案:D
2. 下面那个是Runable接口的方法?
A. run
B. start
C. yield
D. stop
答案:A
3.下列哪些情况可以终止当前线程的运行?
a. 抛出一个例外时。
b. 当该线程调用sleep()方法时。
c. 当创建一个新线程时。
d. 当一个优先级高的线程进入就绪状态时。
答案:ABD
4.下列正确的有()
A.call by value不会改变实际参数的数值
B.call by reference能改变实际参数的参考地址
C.call by reference不能改变实际参数的参考地址
D.call by reference能改变实际参数的内容
答案:ACD
5. "|DF|A".split("|").length的结果是
A 2 B 3 C 5 D 6
答案:D
6. 下面语句在编译时不会出现警告或错误的是
A. float f=3.14;
B. char c=”c”;
C. Boolean b=null;
D. int i=10.0;
答案:C
7.若某二叉树的前遍历访问顺序是序abdgcefh,中序遍历顺序是dgbaechf,则后序遍历的访问顺序是什么。
由前序遍历结果我们可知a为根结点,再看中序遍历结果,因为中序遍历顺序是左子树、根、右子树,因此由“中序遍历顺序是dgbaechf”可断定,dgb为该二叉树的左子树中序遍历结果,echf为右子树中序遍历结果。
由前序遍历结果可知,左子树的前序遍历结果是bdg,右子树的前序遍历结果是cefh;因此,和第一步分析类似,可知b为左子树的根,再由“dgb为该二叉树的左子树中序遍历结果”可知,dg为该左子树的左子树的中序遍历结果,再由dg在前序遍历结果中排列顺序dg可知,d为根,因此由“dg为该左子树的左子树的中序遍历结果”可推出g为d的右孩子。
到此为止,可以完全推断出该二叉树的左子树的结构了。
按照同样方法,可以推断出该二叉树的右子树的结构,因此整个二叉树的结构图如下:
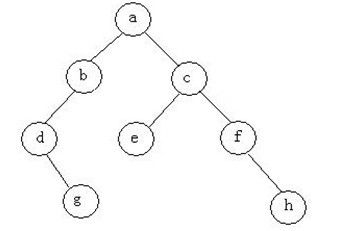
据此图,不难看出该二叉树的后序遍历结果是:gdbehfca
8. String为什么是不可变,StringBuffer
Java运行时会维护一个String Pool(String池),其实就是栈中数据,String池用来存放运行时中产生的各种字符串,并且池中的字符串的内容不重复.而一般对象不存在这个缓冲池,并且创建的对象仅仅存在于方法的堆栈区。
当使用任何方式来创建一个字符串对象时,Java运行时(运行中JVM)会拿着这个字符串在String池中找是否存在内容相同的字符串对象,如果不存在,则在池中创建一个字符串s
Java中,要使用new关键字来创建对象,则一定会(在堆区或栈区)创建一个新的对象.
使用直接指定或者使用纯字符串串联来创建String对象,则仅仅会检查维护String池中的字符串,池中没有就在池中创建一个,有则罢了!但绝不会在堆栈区再去创建该String对象
使用包含变量的表达式来创建String对象,则不仅会检查维护String池,而且还会在堆栈区创建一个String对象.
任何一个对String的赋值操作都会生成一个新的对象,原对象变为无效,等待回收
StringBuffer 线程安全的可变字符序列
StringBuilder 的实例用于多个线程是不安全的
9. SESSION, COOKIE区别
Session是由应用服务器维持的一个服务器端的存储空间,用户在连接服务器时,会由服务器生成一个唯一的SessionID,用该SessionID 为标识符来存取服务器端的Session存储空间。而SessionID这一数据则是保存到客户端,用Cookie保存的,用户提交页面时,会将这一 SessionID提交到服务器端,来存取Session数据。这一过程,是不用开发人员干预的。所以一旦客户端禁用Cookie,那么Session也会失效。
Cookie是客户端的存储空间,由浏览器来维持。在一些投票之类的场合,我们往往因为公平的原则要求每人只能投一票,在一些WEB开发中也有类似的情况,这时候我们通常会使用COOKIE来实现。
http是无状态的协议,客户每次读取web页面时,服务器都打开新的会话,而且服务器也不会自动维护客户的上下文信息,那么要怎么才能实现网上商店中的购物车呢,session就是一种保存上下文信息的机制,它是针对每一个用户的,变量的值保存在服务器端,通过SessionID来区分不同的客户,session是以cookie或URL重写为基础的,默认使用cookie来实现,系统会创造一个名为JSESSIONID的输出cookie,我们叫做session cookie,以区别persistent cookies,也就是我们通常所说的cookie,注意session cookie是存储于浏览器内存中的,并不是写到硬盘上的,这也就是我们刚才看到的JSESSIONID,我们通常情是看不到JSESSIONID的,但是当我们把浏览器的cookie禁止后,web服务器会采用URL重写的方式传递Sessionid,我们就可以在地址栏看到sessionid=KWJHUG6JJM65HS2K6之类的字符串。
明白了原理,我们就可以很容易的分辨出persistent cookies和session cookie的区别了,网上那些关于两者安全性的讨论也就一目了然了,session cookie针对某一次会话而言,会话结束session cookie也就随着消失了,而persistent cookie只是存在于客户端硬盘上的一段文本(通常是加密的),而且可能会遭到cookie欺骗以及针对cookie的跨站脚本攻击,自然不如session cookie安全了。
10. HTTP报文解析及其状态码
HTTP 请求报文
l HTTP Command: //方法字段,说明其使用的是GET 方法
l URI: / //URL 字段,发送请求至保存该网站的服务器。
l HTTP Version: //http 协议版本字段,用是的http/1.1 版本
l Accept: //指示可被接受的请求回应的介质类型范围列表。
l Accept-Language: //限制了请求回应中首选的语言为简体中文,否则使用默认值。
l Accept-Encoding: //限制了回应中可接受的内容编码值,指示附加内容解码方式为gzip,deflate.
l User-Agent: //定义用户代理,即发送请求的浏览器类型为Mozilla/4.0
l Host: www.XX.com ///r/n定义了目标所在的主机
l Connection: Keep-Alive/r/n //告诉服务器使用持久连接
HTTP 回应报文
l HTTP Version: HTTP/1.1 //服务器用的是HTTP/1.1 版本
l HTTP Status: 200 //请求成功,信息可以读取,包含在响应的报文中
l Date: //指服务器从文件系统中检索到该对象,插入到响应报文,并发送该响应报文的时间
l Server: //表明刻报文是由一个Apache/2.0.52 的服务器产生的
l X-Powered-By: //表明是使用PHP(版本)的动态网页
l Set- cookie: //
l Vary: //
l Content-Length: //表明实体的长度
l Connection: //告诉客户机在报文发送完毕后仍然保持连接
l Content-Type: //表明实体中的对象是html 文档
l Binary Data: //二进制数据
说明:在服务器给的回应请求中,我们可以从状态码中看到访问的相关信息。状态码表示响应类型,常用的有:
l 1×× 保留
l 2×× 表示请求成功地接收
l 3×× 为完成请求客户需进一步细化请求
l 4×× 客户错误
l 5×× 服务器错误
TCP/IP(Transmission Control Protocol/Internet Protocol)的简写,中文译名为传输控制协议/因特网互联协议,这个协议是Internet最基本的协议、Internet国际互联网络的基础,简单地说,就是由网络层的IP协议和传输层的TCP协议组成的。TCP/IP 定义了电子设备(比如计算机)如何连入因特网,以及数据如何在它们之间传输的标准
11. 栈Stack和堆Heap
存在栈中的数据可以共享,存取速度快,缺点其数据大小和生存期是确定的。
堆是运行时数据区,类的对象从堆中分配空间,由垃圾回收机制负责回收。
12. PreparedStatement和Statement区别的一点小总结
数据库会PreparedStatement语句进行预编译,下次执行相同的sql语句时,数据库端不会再进行预编译了,而直接用数据库的缓冲区,提
高数据访问的效率,提高安全性(防止SQL Injeciton)
String sql = "select * from tb_name where name= '"+varname+"' and passwd='"+varpasswd+"'";
如果我们把[' or '1' = '1]作为varpasswd传入进来.用户名hzy,看看会成为什么?
select * from tb_name = 'hzy' and passwd = '' or '1' = '1';
因为'1'='1'肯定成立,所以可以任何通过验证.
13. Forward与Redirect
|
类别
|
概念
|
共享数据
|
应用
|
|
Redirect
|
URL重新定向:可以是任意的URL
|
不能共享request里面的数据
|
一般用于用户注销登录时返回主页面和跳转到其它的网站等等
|
|
Forward
|
页面的转发:只能是同一个Web应用程序的其他Web组件
|
转发页面和转发到的页面可以共性request里面的数据
|
一般用于用户登录的时候根据角色转发到相应的模块等等
|
14. rownum与rowid
rownum是在得到结果集的时候产生的,用于标记结果集中结果顺序的一个字段,这个字段被称为“伪数列”,也就是事实上不存在的一个数列。它的特点是按顺序标记,而且是逐次递加的,换句话说就是只有有rownum=1的记录,才可能有rownum=2的记录。
和rownum相似,oracle还提供了另外一个伪数列:rowid。不过rowid和rownum不同,一般说来每一行数据对应的rowid是固定而且唯一的,在这一行数据存入数据库的时候就确定了。可以利用rowid来查询记录,而且通过rowid查询记录是查询速度最快的查询方法。(这个我没有试过,另外要记住一个长度在18位,而且没有太明显规律的字符串是一个很困难的事情,所以我个人认为利用rowid查询记录的实用性不是很大)rowid只有在表发生移动(比如表空间变化,数据导入/导出以后),才会发生变化。
15. 索引的优点和缺点
第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二,可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四,在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
增加索引也有许多不利的一个方面。
第一,创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
第二,索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空 间就会更大。
第三,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度
16 . 反射和注释
分标记注释,单值注释 普通注释
反射:是Java被视为动态(或准动态)语言的一个关键性质。这个机制允许程序在运行时透过Reflection APIs取得任何一个已知名称的类的内部信息,在运行的时候获得任意对象的类:
a. 使用类的.class语法
b. 通过类的对象的getClass()方法。getClass()方法在Object类里面定义的。
c. 通过Class对象的forName()方法
17. Hibernate工作原理
- 读取并解析配置文件
- 读取并解析映射信息,创建SessionFactory
- 打开Sesssion
- 创建事务Transation
- 持久化操作
- 提交事务
- 关闭Session
- 关闭SesstionFactory
Hibernate有什么好处
- 对JDBC访问数据库的代码做了封装,大大简化了数据访问层繁琐的重复性代码。
- 很大程度的简化DAO层的编码工作
- hibernate使用Java反射机制,而不是字节码增强程序来实现透明性。
- 映射的灵活性很出色。它支持各种关系数据库,从一对一到多对多的各种复杂关系。
Hibernate的缓存机制介绍
http://blog.csdn.net/ziliang871118/archive/2011/02/21/6198314.aspx
18. JDK5或者JDK6有什么新的特性?
for-each循环: for-each能自动遍历数组或集合中的每个元素
泛型:
枚举:
自动拆箱装箱:
可变参数: 使用可变参数需要注意两点:如果函数中传入的参数中有可变参数和固定参数,可变参数必须要处于行参列表的最后。
调用一个包含可变参数的方法时,传入的可以是多个参数或一个数组
静态导入:静态导入使用import static 语句导入一个类的全部静态方法和静态属性
标注:向 Java 类、接口、方法和字段关联附加的数据。这些附加的数据或者注释,可以被 javac 编译器或其他工具读取,
并且根据配置不同,可以被保存在类文件中,也可以在运行时使用 Java 反射 API 被发现
19. 在持久化层,对象分为哪些状态?分别列出来
瞬时态(Transient)
是对象是创建时,瞬时对象在内存孤立存在,它是携带信息的载体,不和数据库的数据有任何关联关系,在Hibernate中,可通过session的save()或 saveOrUpdate()方法将瞬时对象与数据库相关联,并将数据插入数据库中,此时该瞬时对象转变成持久化对象。
持久态(Persistent)
是该对象在数据库中已有对应的记录,并拥有一个持久化标识,如果是用hibernate的delete()方法,对应的持久对象就变成瞬时对象,因数据库中的对应数据已被删除,该对象不再与数据库的记录关联。
当一个session执行close()或clear()、evict()之后,持久对象变成脱管对象,此时持久对象会变成脱管对象,此时该对象虽然具有数据库识别值,但它已不在hibernate持久层的管理之下。
持久对象具有如下特点:
1. 和session实例关联;
2. 在数据库中有与之关联的记录。
脱管态(Detached)
当与某持久对象关联的session被关闭后,该持久对象转变为脱管对象。当脱管对象被重新关联到session上时,并再次转变成持久对象。
脱管对象拥有数据库的识别值,可通过update()、saveOrUpdate()等方法,转变成持久对象。
脱管对象具有如下特点:
1.本质上与瞬时对象相同,在没有任何变量引用它时,JVM会在适当的时候将它回收;
20.你对J2EE的理解?
J2EE应用一般分4层架构: 客户层,web层,业务层,持久层
J2EE平台对每一种主要的组件类型都定义了相应的容器类型.J2EE平台由4种类型的程序容器组成它们是:
EJB容器——为Enterprise JavaBean组件提供运行时环境,它对应于业务层和数据访问层,主要负责数据处理以及和数据库或其他Java程序的通信.
Web容器——管理JSP和Servlet等Web组件的运行,主要负责Web应用和浏览器的通信,它对应于表示层.
应用客户端容器——负责Web应用在客户端组件的运行,它对应于用户界面层.
Applet容器——负责在Web浏览器和Java插件(Java Plug-in)上运行Java Applet程序,它对应于用户界面层.
每种容器内都使用相关的各种Java Web编程技术.这些技术包括应用组件技术(例如,Servlet,JSP,EJB等技术构成了应用的主体),应用服务技术(例如,JDBC,JNDI等服务保证组件具有稳定的运行时环境),通信技术(例如,RMI,JavaMail等技术在平台底层实现机器和应用程序之间的信息传递)等3类.
21. HASHTABLE, HASHMAP,TreeMap区别
Hashmap 是一个最常用的Map,它根据键的HashCode 值存储数据,根据键可以直接获取它的值,具有很快的访问速度。HashMap最多只允许一条记录的键为Null;允许多条记录的值为 Null;HashMap不支持线程的同步,即任一时刻可以有多个线程同时写HashMap;可能会导致数据的不一致。如果需要同步,可以用 Collections的synchronizedMap方法使HashMap具有同步的能力.
HashMap的原理参考文章: http://blog.csdn.net/ziliang871118/archive/2011/03/03/6221804.aspx
Hashtable 与 HashMap类似,但是主要有6点不同。
1.HashTable的方法是同步的,HashMap未经同步,所以在多线程场合要手动同步HashMap这个区别就像Vector和ArrayList一样。
2.HashTable不允许null值,key和value都不可以,HashMap允许null值,key和value都可以。HashMap允许 key值只能由一个null值,因为hashmap如果key值相同,新的key, value将替代旧的。
3.HashTable有一个contains(Object value)功能和containsValue(Object value)功能一样。
4.HashTable使用Enumeration,HashMap使用Iterator。
5.HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
6.哈希值的使用不同,HashTable直接使用对象的hashCode