Linux服务器故障排查
问题:服务器A无法与服务器B通信
可能大家在实际工作中最常见的网络故障就是一台服务器无法与另一台网络上的服务器进行通信。本小节将通过实例讲解具体处理办法。在实例中,一台名为dev1的服务器无法访问另一台名为web1的服务器中的网络服务(端口80)。导致这一现象的原因相当繁杂,因此我们需要一步步测试操作活动,进而通过排除法找到故障的根源。
一般说来,在对这样的问题进行故障排查时,大家可能会跳过某些初始步骤(例如检查链接等),因为接下来的某些测试环节能起到同样的诊断作用。举例来说,如果我们测试并确认DNS能够正常工作,那么就证明我们的主机是能够与本地网络进行通信的。但在本次实例解析中,我们将本着谨慎的态度执行每一个步骤,借以理解各个级别的不同测试方式。
- 问题出在客户机还是服务器端?
大家可以利用一项快速测试缩小造成故障的范围,即通过同一网络中的另一台主机尝试访问对应服务器。在本实例中,我们姑且将另一台与dev1同处一套网络环境下的服务器命名为dev2,并尝试通过它访问web1。如果dev2也不能正常访问web1,那么显然问题很可能出在web1或者是dev1、dev2及web1之间的网络身上。如果dev2能够正常访问web1,那么我们就可以断定dev1出问题的机率较大。首先,我们假设dev2能够访问web1,因此我们开始将故障排查的重点放在dev1这边。
- 线缆插好了吗?
故障排查的第一步要在客户机上进行。大家首先要确认自己客户机的网络连接没有问题。要做到这一点,我们可以使用ethtool程序(通过ethtool工具包安装)对链接(即以太网设备与网络构成物理连接)情况加以检测。如果大家无法确定自己使用的是哪个端口,那么请运行/sbin/ifconfig命令将所有可用的网络端口及其设定列出。我们假设自己的以太网设备在eth0端口上,那么:
$ sudo ethtool eth0
Settings for eth0:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Half 1000baseT/Full
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Half 1000baseT/Full
Advertised auto-negotiation: Yes
Speed: 100Mb/s
Duplex: Full
Port: Twisted Pair
PHYAD: 0
Transceiver: internal
Auto-negotiation: on
Supports Wake-on: pg
Wake-on: d
Current message level: 0x000000ff (255)
Link detected: yes
在最后一行中,大家可以看到检测结果显示链接设置为“yes”,所以dev1已经与网络构成物理连接。如果这项检测的结果为“no”,那么我们需要亲自检查dev1的网络连接,并将线缆插实到位。在确定物理连接没有问题之后,执行下面的步骤。
注意:ethtool绝不仅仅是一款用于检测链接状况的工具,它还能够诊断并纠正双工问题。当Linux服务器与网络连通时,通常会与网络自动协商以获取传输速度信息以及该网络是否支持全双工。在本实例中,传输速度经ethtool检测为100Mb/秒,且该网络支持全双工机制。如果大家发现主机的网络传输速度缓慢,那么速度及双工设定是首先需要关注的重点。如前文所示运行ethtool,若大家发现双工被设定为一半,则运行以下命令:
$ sudo ethtool -s eth0 autoneg off duplex full
意思是利用自己的以太网设备代替eth0。
端口正常吗?
一旦确认了服务器与网络之间物理连接的完好性,接下来就是判断主机上的网络端口是否配置正确。在这方面,最好的检查方式就是运行ifconfig命令并将端口作为参数后缀。因此要测试eth0的设置,大家应该运行以下内容:
$ sudo ifconfig eth0
eth0 Link encap:Ethernet HWaddr 00:17:42:1f:18:be
inet addr:10.1.1.7 Bcast:10.1.1.255 Mask:255.255.255.0
inet6 addr: fe80::217:42ff:fe1f:18be/64 Scope:Link
UP BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:1 errors:0 dropped:0 overruns:0 frame:0
TX packets:11 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:229 (229.0 B) TX bytes:2178 (2.1 KB)
Interrupt:10
在上述输出结果中,第二行可能最值得我们关注,因为其内容是解释我们的主机已经被配置了一套IP地址(10.1.1.7)与子网掩码(255.255.255.0)。现在,大家需要确认这样的设置结果是否正确。如果端口未受配置,请尝试运行sudo ifup eth0,然后再次运行ifconfig重新检查端口是否出现。如果设置错误或端口未出现,则检查/etc/network/interfaces路径(Debian系统)或/etc/-sysconfig/-network_scripts/ifcfg-<interface>路径(红帽系统)。在这些文件中,大家可以修正网络设置中存在的所有错误。现在如果主机通过DHCP获得自身IP,我们则需要将故障排查转移到DHCP主机处,找出为什么我们没有正确获得IP租用周期。
问题出在本地网络中吗?
排除了端口出现的问题之后,接下来我们就该检查默认网关是否被设置及我们能否对其进行访问。route命令将显示出我们当前的路由表,包括默认网关:
$ sudo route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 10.1.1.0 * 255.255.255.0 U 0 0 0 eth0 default 10.1.1.1 0.0.0.0 UG 100 0 0 eth0
以上内容中值得关注的在于最后一行,也就是default那段内容。在这里,大家可以看到主机网关为10.1.1.1.请注意,由于我们在route命令后添加了-n选项,所以命令不会尝试将这些IP地址解析为实际主机名称。这种方式能让命令的运行更迅速,但更重要的是,我们不希望故障排查工作受到任何潜在DNS错误的影响。如果大家没有在这里看到经过配置的默认网关,而我们想要检查的主机处于另一子网之下(例如web1为10.1.2.5),那么问题很可能就出在这里。要将其解决,大家一定要确保网关设置要么处于Debian系统的/etc/network/interfaces路径下、要么是在红帽系统的/etc/-sysconfig/network_scripts/ifcfg-<interface>路径下;如果IP是由DHCP所分配,则确保网关在DHCP服务器中被正确设置。在Debian系统中,我们运行如下命令进行端口重置:
$ sudo service networking restart
而在红帽系统中我们需要运行如下命令进行端口重置:
$ sudo service network restart
请大家注意,即使是如此基本的操作命令在不同的系统发行版中也存在着差异。
一旦确认网关配置完成,我们可以利用ping命令来确认与网关的通信效果:
$ ping -c 5 10.1.1.1 PING 10.1.1.1 (10.1.1.1) 56(84) bytes of data. 64 bytes from 10.1.1.1: icmp_seq=1 ttl=64 time=3.13 ms 64 bytes from 10.1.1.1: icmp_seq=2 ttl=64 time=1.43 ms 64 bytes from 10.1.1.1: icmp_seq=3 ttl=64 time=1.79 ms 64 bytes from 10.1.1.1: icmp_seq=5 ttl=64 time=1.50 ms --- 10.1.1.1 ping statistics --- 5 packets transmitted, 4 received, 20% packet loss, time 4020ms rtt min/avg/max/mdev = 1.436/1.966/3.132/0.686 ms
如大家所见,我们已经能够正确ping通网关,这至少意味着大家与10.1.1.0网络能够进行通信。如果无法ping通网关,那么原因可能分以下几种。首先,这可能表示我们的网关自动阻断ICMP数据包。如果是这样,请告诉网络管理员阻断ICMP是种讨厌的坏习惯,由此带来的安全收益也微乎其微。然后尝试ping同一子网下的另一台Linux主机。如果ICMP没有被阻断,那么可能是主机交换机端口的VLAN设置有误,所以我们需要进一步检查接入的交换机。
DNS能正常工作吗?
一旦确认了与网关之间的通信能力,下面要做的就是测试DNS功能是否正常。nslookup与dig两款工具都能用于排查DNS方面的问题,但由于在本实例中大家只需要进行一基础测试,因此我们建议使用nslookup命令可查看服务器能否将web1正确解析为IP地址:
$ nslookup web1 Server: 10.1.1.3 Address: 10.1.1.3#53 Name: web1.example.net Address: 10.1.2.5
如上所示,实例中的DNS服务器能够正常工作。web1主机扩展为web1.example.net且被解析为10.1.2.5地址。当然,大家别忘了确认解析出的IP地址与web1应该使用的IP地址相匹配。在本实例中,因为DNS没有问题,所以我们可以直接跳到下一部分;但有时候DNS也可能出现问题。
没有配置过的名称服务器或无法访问名称服务器
如果大家看到如下错误,这可能意味着要么我们的主机没有配置过的名称服务器,要么这些服务器无法进行访问:
$ nslookup web1 ;; connection timed out; no servers could be reached
在这两种情况下,我们都需要检查/etc/resolv.conf文件以确认是否存在已配置的名称服务器。如果我们在这里找不到任何已配置的IP地址,则需要在文件中添加一个名称服务器。相反,如果我们看到如下所示的内容,则需要通过ping命令对主机与名称服务器之间的连接进行排查:
search example.net nameserver 10.1.1.3
如果无法ping通名称服务器,且其IP地址与我们的主机处于同一子网下(在本实例中,10.1.1.3代表处于同一子网下),则代表名称服务器本身可能已经崩溃。如果无法ping通名称服务器且其IP地址与我们的主机处于不同子网下,则直接跳转至"我能路由至远程主机吗?"章节,选择其中与名称服务器IP故障排查相关的内容加以执行。如果通过ping通名称服务器但对方无响应,则跳转至"远程端口是否打开?”章节。
缺少搜索路径或名称服务器的问题
在运行nslookup命令后,我们还可能得到以下错误信息:
$ nslookup web1 Server: 10.1.1.3 Address: 10.1.1.3#53 ** server can't find web1: NXDOMAIN
在这里大家可以看到服务器没有响应,因为它给出的回应表明:服务器无法找到web1。这可能意味着两种可能性:第一,这可能代表web1这一域名并不在DNS搜索路径当中。这部分搜索设置内容位于/etc/resolv.conf文件当中。推荐一种比较好的测试方式,即执行同样的nslookup命令,但只使用全称域名(在本实例中为web1.example.net)。如果能够被正确解析,则要么在命令中始终使用全称域名,要么在/etc/resolv.conf中将主机名称添加到搜索路径当中(如果大家懒得重复输入)。
如果连全称域名也不能奏效,那么问题肯定出在名称服务器上。这里我们汇总了一些DNS问题的故障排查指南。如果名称服务器保存有记录,则需要对其配置进行检查。如果使用的是递归名称服务器,我们则必须通过查找其它一些域来测试名称服务器的递归机制是否正常。如果其它域都能被正确列出,我们就要看看问题是不是出在包含上述区域的远程名称服务器端。
我能路由至远程主机吗?
在排除了DNS问题并看到web1被正确解析为IP 10.1.2.5之后,大家需要测试自己能否路由至远程主机。假如我们的网络启用了ICMP,那么最快捷的测试办法是ping web1。如果该主机能被ping通,我们就知道数据包已经被路由至目的地,这样的话可以直接跳转至"远程端口打开了吗?"章节。如果无法ping通web1,则尝试与网络中的另一台主机通信看看能否ping通。如果我们无法在远程网络中ping通任何主机,就说明数据包无法被正确路由。最好的路由问题测试工具这一就是traceroute。一旦与一台主机建立起路由追踪,它会测试我们与主机之间的每一次数据包跳转。举例来说,dev1与web1之间的一次成功路由追踪流程将如下所示:
$ traceroute 10.1.2.5 traceroute to 10.1.2.5 (10.1.2.5), 30 hops max, 40 byte packets 1 10.1.1.1 (10.1.1.1) 5.432 ms 5.206 ms 5.472 ms 2 web1 (10.1.2.5) 8.039 ms 8.348 ms 8.643 ms
这里我们会看到数据包从dev1到达其网关(10.1.1.1),然后再跳转至web1。这代表着起始位置与目标主机可能都采用10.1.1.1网关。如果大家的操作环境中存在更多路由中转点,那么显示的结果可能与上述内容有所不同。如果无法ping通web1,那么输入结果将如下所示:
$ traceroute 10.1.2.5 traceroute to 10.1.2.5 (10.1.2.5), 30 hops max, 40 byte packets 1 10.1.1.1 (10.1.1.1) 5.432 ms 5.206 ms 5.472 ms 2 * * * 3 * * *
一旦我们在输出结果中看到星号,就说明问题出在网关方面。大家需要从路由器着手,看看为什么它无法在两套网络之间路由数据包。通过追踪,大家会看到如下内容:
$ traceroute 10.1.2.5 traceroute to 10.1.2.5 (10.1.2.5), 30 hops max, 40 byte packets 1 10.1.1.1 (10.1.1.1) 5.432 ms 5.206 ms 5.472 ms 1 10.1.1.1 (10.1.1.1) 3006.477 ms !H 3006.779 ms !H 3007.072 ms
在这种情况下,我们发现ping操作在网关环节出现了超时,这说明该主机可能已经崩溃或无法通过同一子网进行访问。有鉴于此,如果大家还没有从同一子网下的其它设备访问过web1,请尝试ping及其它测试。
注意:如果某套烦人的网络仍然在阻断ICMP,不用担心,我们仍然有办法进行路由排查工作。大家只需要安装tcptraceroute软件包(sudo apt-get install tcptraceroute)然后运行相同的路由追踪命令,惟一的区别是用tcptraceroute来代替traceroute 。
远程端口打开了吗?
现在我们已经能够路由至目标设备,但仍然无法在端口80上访问web服务器。接下来的测试意在检查端口是否打开。要实现这一目的,我们可以选择的方案很多。选择其一,我们可以尝试telnet:
$ telnet 10.1.2.5 80 Trying 10.1.2.5... telnet: Unable to connect to remote host: Connection refused
如果大家看到连接被拒绝,那么端口很可能处于关闭状态(可能是Apache未能运行在远程主机上或没有侦听该端口),也可能是防火墙阻断了我们的访问。如果telnet能够连接,那么恭喜各位,现在大家已经解决了所有网络问题。但如果web服务的工作状态与我们的预期不符,则需要检查web1上的Apache配置(web服务器的故障排查工作在本文的其它章节会谈到)。
但相对于telnet,我个人更偏向使用nmap来进行端口测试,因为它往往能够检测到防火墙的影响。如果大家还没有安装nmap,可以使用软件包管理器快速安装nmap软件包。要对web1进行测试,请输入以下内容:
$ nmap -p 80 10.1.2.5 Starting Nmap 4.62 ( http://nmap.org ) at 2009-02-05 18:49 PST Interesting ports on web1 (10.1.2.5): PORT STATE SERVICE 80/tcp filtered http
nmap果然不负众望,它一般都能发现所谓"关闭的端口"到底是直接处于关闭状态、还是在防火墙后处于关闭状态。通常情况下,nmap会将真正关闭的端口报告为"关闭",而将防火墙后的端口报告为"过滤"。在我们的测试中它报告其状态为"过滤",意味着期间有防火墙作梗并忽略掉了我们的数据包。如此一来,大家就需要检查网关(10.1.1.1)以及web1上的全部防火墙规则,看看端口80是否处于阻断状态。
在本地测试远程主机
到了这里,摆在我们面前的就有两种可能性:要么将故障范围缩小为网络问题,要么认定毛病出在主机自身。如果大家认定毛病出在主机自身,我们可以通过一系列操作检查端口80是否可用。
侦听端口测试
我们在web1上要做的第一件事就是测试端口80是否处于侦听状态。大家可以使用netstat -lnp命令来列出所有打开且处于侦听状态的端口。我们当然可以直接运行这条命令并从输出结果中筛选出自己想要的结论,但效率更高的方式则是利用grep指定显示端口80的侦听状态:
$ sudo netstat -lnp | grep :80 tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 919/apache
第一列内容显示出端口所使用的传输协议。第二及第三列则显示接收及发送队列(这里两者都被设置为0)。现在我们要注意的是第四列,因为它列出了主机所侦听的本地地址。此处的0.0.0.0:80告诉我们该主机正侦听所有端口80流量中与其IP有关的数据。如果Apache只侦听web1的以太网地址,我们将在输出结果中看到10.1.2.5:80。
最后一列显示的是哪个进程令端口处于开放状态。这里我们看到是运行中的Apache正在进行侦听。如果大家在自己的netstat输出结果中没有看到这部分内容,则需要启动Apache服务器。
防火墙规则
如果进程正在运行且侦听端口80,那就说明可能是web1中某种形式的防火墙导致了问题的发生。利用iptables命令列出全部现有防火墙规则。如果我们的防火墙已被禁用,那么输出结果应如下所示:
$ sudo /sbin/iptables -L Chain INPUT (policy ACCEPT) target prot opt source destination Chain FORWARD (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination
请注意,默认政策被设置为ACCEPT。尽管规则本身没有问题,但防火墙仍然有可能默认弃用所有数据包。如果属于这类情况,大家会看到如下所示的输出内容:
$ sudo /sbin/iptables -L Chain INPUT (policy DROP) target prot opt source destination Chain FORWARD (policy DROP) target prot opt source destination Chain OUTPUT (policy DROP) target prot opt source destination
另一方面,如果某条防火墙规则阻断了端口80,那么输出结果则应如下所示:
$ sudo /sbin/iptables -L -n Chain INPUT (policy ACCEPT) target prot opt source destination REJECT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:80 reject-with( icmp-port-unreachable Chain FORWARD (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination
在后一种情况下,我们显然需要修改防火墙规则,以允许服务器接收来自端口80的主机数据流量。
网络缓慢状况的故障排查
从某种角度来说,网络无法工作的问题更容易解决。当一台主机无法访问,我们可以执行前面讨论过的故障排查步骤直到一切恢复正常。但如果仅仅是网络缓慢,追查其根本原因往往变得更为棘手。本章节将讨论一些相关技巧,帮助大家追踪导致网络速度缓慢的各种原因。
DNS问题
虽然DNS在网络出现问题时常常蒙冤受责,但在导致网络性能不佳方面,DNS倒真该被优先检查一番。举例来说,如果我们为某个域名配置了两台DNS服务器,那么在第一台出现问题时,我们发出的DNS请求会等待30秒之后才传输至第二台DNS服务器。虽然当我们使用像dig或nslookup这样的工具时此类情况显得一目了然,但对于日常使用来说,DNS故障往往会以令人意外的方式造成网络缓慢;这是因为有太多服务需要借助DNS实现将主机名称解析为IP地址的工作。这些问题甚至有可能影响到我们的网络故障诊断工具。
Ping、tracerouter、oute、netstat甚至包括iptables在内的多款网络故障排查工具都会受到DNS问题的牵连而导致速度缓慢。在默认情况下,上述所有工具都会尽可能尝试将IP地址解析为主机名称。一旦DNS服务器有了毛病,这些命令就会在查找IP地址的过程中停滞不前并最终导致执行失效。在ping或traceroute方面,问题表现为整个ping应答周期耗时相当长,但最终的请求往返时间却比较短。而在netstat与iptables方面,其请求结果可能会拖延很久才输出到屏幕上,这是因为系统一直在等待已经超时的DNS请求。
在前面提到的各种情况中,我们都能很容易地绕过DNS来保证故障排查结果的准确性。所有列举的命令都可以通过添加-n参数来禁止其将IP地址解析为主机名称。我也是刚刚养成在所有命令后加-n的好习惯--正如第一章提到的那样--除非我确定自己想解析IP地址。
注意:DNS解析还可能以其它一些意想不到的方式影响我们的web服务器性能。某些web服务器会根据配置对访问的第一个IP地址进行解析,并将得到的主机名称记录下来。虽然这会让记录信息更具可读性,但同时也会在出现问题时大大降低web服务器的速度--例如存在大量访问者时。这时web服务器会忙着解决这些IP地址的解析工作,而选择将服务流量搁置在一边。
利用traceroute解决网络缓慢问题
当处于不同网络中的服务器与主机间的连接发生拖慢状况时,我们可能很难追查到真正的罪魁祸首。尤其是在拖慢以延迟形式(即响应所消耗的时间)出现而不涉及全局带宽的情况下,真正能力挽狂澜的就只有traceroute了。正如前文所说,tracerout是一种在远程网络中测试客户机与服务器间全局连接的有效方式,但它同时也能有效诊断出导致网络缓慢的潜在根源。由于traceroute会输出当前与目标设备之间每次数据转发所消耗的时间,因此我们可以利用它追踪由地域相距过大或网关问题所引发的过载及网络缓慢原因。举例来说,我们利用traceroute检查美国与中国两边的雅虎服务器,输出结果如下所示:
$ traceroute yahoo.cn traceroute to yahoo.cn (202.165.102.205), 30 hops max, 60 byte packets 1 64-142-56-169.static.sonic.net (64.142.56.169) 1.666 ms 2.351 ms 3.038 ms 2 2.ge-1-1-0.gw.sr.sonic.net (209.204.191.36) 1.241 ms 1.243 ms 1.229 ms 3 265.ge-7-1-0.gw.pao1.sonic.net (64.142.0.198) 3.388 ms 3.612 ms 3.592 ms 4 xe-1-0-6.ar1.pao1.us.nlayer.net (69.22.130.85) 6.464 ms 6.607 ms 6.642 ms 5 ae0-80g.cr1.pao1.us.nlayer.net (69.22.153.18) 3.320 ms 3.404 ms 3.496 ms 6 ae1-50g.cr1.sjc1.us.nlayer.net (69.22.143.165) 4.335 ms 3.955 ms 3.957 ms 7 ae1-40g.ar2.sjc1.us.nlayer.net (69.22.143.118) 8.748 ms 5.500 ms 7.657 ms 8 as4837.xe-4-0-2.ar2.sjc1.us.nlayer.net (69.22.153.146) 3.864 ms 3.863 ms 3.865 ms 9 219.158.30.177 (219.158.30.177) 275.648 ms 275.702 ms 275.687 ms 10 219.158.97.117 (219.158.97.117) 284.506 ms 284.552 ms 262.416 ms 11 219.158.97.93 (219.158.97.93) 263.538 ms 270.178 ms 270.121 ms 12 219.158.4.65 (219.158.4.65) 303.441 ms * 303.465 ms 13 202.96.12.190 (202.96.12.190) 306.968 ms 306.971 ms 307.052 ms 14 61.148.143.10 (61.148.143.10) 295.916 ms 295.780 ms 295.860 ms ...
既然不了解有关网络的更多细节信息,我们也能够单纯通过往返时间把握数据包的动向。从第九次跳转开始,IP地址变成了219.158.30.177,这意味着数据包已经离开美国抵达中国,而跳转的往返时间也从3毫秒提高到275毫秒。
利用iftop找出是谁占用了带宽
有时候我们的网络缓慢并不是由远程服务器或路由器所引起,而只是因为系统中的某些进程占用了太多可用带宽。虽然从直观角度我们很难确定哪些进程正在使用带宽,但也有一些工具能帮大家把这些捣蛋的家伙揪出来。
top就是这样一款出色的故障排查工具,它的出现还带来一系列思路相似的衍生品,例如iotop--能够确定到底是哪些进程占用了大部分磁盘I/O性能。最终名为iftop的工具横空出世,能够在网络连接领域提供同等功能。与top不同,iftop不会亲自关注进程情况,而是列出用户服务器与远程IP之间占用带宽最多的连接对象。举例来说,我们可以在iftop中快速查看备份服务器IP地址在输出结果中的位置来判断备份工作有没有大量占用网络带宽。
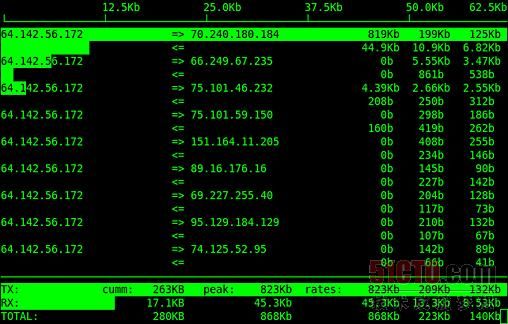
iftop输出图示
红帽与Debian的各个发行版都能使用iftop这一名称的软件包,但在红帽发行版方面大家可能需要从第三方资源库才能获取。一旦安装过程完成,我们在命令行中运行iftop命令即可启用(需要root权限)。和top命令一样,我们可以点Q键退出。
在iftop界面屏幕的最上方是显示全局流量的信息栏。信息栏之下则是另外两列信息,一列为源IP、另一列为目标IP,二者之间以箭头填充帮助我们了解带宽被用于从自己的主机向外发送数据还是从远程主机端接收数据。再往下则是另外三个栏位,表示两台主机之间在2秒、10秒及40秒中的数据传输速率。与平均负载相似,大家可以看到目前带宽使用是否达到峰值,或者在过去的哪个时段达到过峰值。在屏幕的最下方,我们会找到传输数据(简称TX)与接收数据(简称RX)的总体统计结果。与top差不多,iftop的界面也会定期更新。
在不添加额外参数的情况下,iftop命令通常能够满足我们故障排查的全部需求;但有的时候,我们可能也希望利用一些选项实现特殊功能。iftop命令在默认情况下会显示查找到的第一个端口的统计信息,但在某些服务器中大家可能会使用多个端口,所以如果我们希望让iftop打理第二个以太网端口(即实例中的eth1),那么请输入iftop -i eth1。
默认情况下,iftop会试图将所有IP地址通过解析转换为主机名称。这样做的缺点在于一旦远程DNS服务器速度缓慢,报告的生成速度也将随之惨不忍睹。另外,所有DNS解析活动都会增加额外的网络流量,而这些都会显示在iftop的报告界面当中。因此要禁用网络解析功能,别忘了在iftop命令后面加-n哦。
一般说来,iftop显示的是主机之间所使用的全局带宽;但为了帮助大家缩小排查范围,我们可能希望每台主机具体使用哪个端口进行通信。毕竟只要找到了主机中占用最大带宽的网络端口,我们就可以在判断是否接入FTP端口之外进行其它排查手段。启动iftop之后,按P键可以切换端口的显示与隐藏状态。不过大家可能会注意到,有时候显示所有端口状态可能导致我们正在关注的主机被挤出当前显示屏幕。如果出现这种情况,我们还可以按S或D键来仅显示来自特定源或特定目标的端口。由于服务项目众多,目标主机可能随机使用多个端口并发生带宽占用峰值,这将导致工具无法识别出正在使用的服务,因此仅显示源端口还是相当有用的。不过服务器上的端口也可能与当前设备上的服务相对应。在这种情况下,我们可以使用前面提到的netstat -lnp来找出服务所侦听的端口。
与大多数Linux命令相似,iftop也拥有多种高级选项。我们在文章中提到的这些已经足以涵盖大多数故障排查需求,但为了满足大家进一步了解iftop功能的愿望,我教各位一个小技巧:只要输入man iftop,就可以阅读包含在软件包当中的使用手册、获得更多与之相关的知识。