The 2010 ACM-ICPC Asia Chengdu Regional Contest
The 2010 ACM-ICPC Asia Chengdu Regional Contest - C
Binary Number
Time Limit: 2 Seconds Memory Limit: 65536 KB
For 2 non-negative integers x and y, f(x, y) is defined as the number of different bits in the binary format of x and y. For example, f(2, 3)=1, f(0, 3)=2, f(5, 10)=4.
Now given 2 sets of non-negative integers A and B, for each integer b in B, you should find an integer a in A such that f(a, b) is minimized. If there are more than one such integers in set A, choose the smallest one.
Input
The first line of the input is an integer T (0 < T ≤ 100), indicating the number of test cases. The first line of each test case contains 2 positive integers m and n (0 < m, n ≤ 100), indicating the numbers of integers of the 2 sets A and B, respectively. Then follow (m + n) lines, each of which contains a non-negative integers no larger than 1000000. The first m lines are the integers in set A and the other n lines are the integers in set B.
Output
For each test case you should output n lines, each of which contains the result for each query in a single line.
Sample Input
2
2 5
1
2
1
2
3
4
5
5 2
1000000
9999
1423
3421
0
13245
353
Sample Output
1
2
1
1
1
9999
0
纯模拟
#include<iostream> #include<stdio.h> using namespace std; #define INF 0x3fffffff int count(int num) { int s=0; while(num!=0) { if(num&1) s++; num>>=1; } return s; } int n,m,a[105],b[105],minn; int main() { int i,j,cas,index; scanf("%d",&cas); while(cas--) { scanf("%d%d",&n,&m); for(i=0;i<n;i++) scanf("%d",&a[i]); for(i=0;i<m;i++) scanf("%d",&b[i]); for(i=0;i<m;i++) { minn=INF; for(j=0;j<n;j++) { int t=count(a[j]^b[i]); if(t<minn) minn=t,index=j; else if(t==minn&&a[index]>a[j]) index=j; } printf("%d/n",a[index]); } } return 0; }
The 2010 ACM-ICPC Asia Chengdu Regional Contest - F
Error Curves
Time Limit: 2 Seconds Memory Limit: 65536 KB
Josephina is a clever girl and addicted to Machine Learning recently. She pays much attention to a method called Linear Discriminant Analysis, which has many interesting properties.
In order to test the algorithm's efficiency, she collects many datasets. What's more, each data is divided into two parts: training data and test data. She gets the parameters of the model on training data and test the model on test data.
To her surprise, she finds each dataset's test error curve is just a parabolic curve. A parabolic curve corresponds to a quadratic function. In mathematics, a quadratic function is a polynomial function of the form f(x) = ax2 + bx + c. The quadratic will degrade to linear function if a = 0.
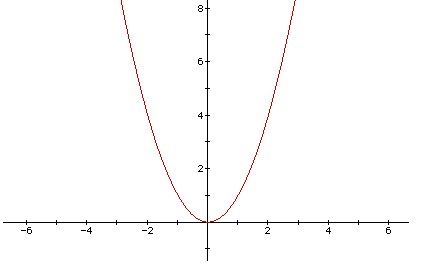
It's very easy to calculate the minimal error if there is only one test error curve. However, there are several datasets, which means Josephina will obtain many parabolic curves. Josephina wants to get the tuned parameters that make the best performance on all datasets. So she should take all error curves into account, i.e., she has to deal with many quadric functions and make a new error definition to represent the total error. Now, she focuses on the following new function's minimal which related to multiple quadric functions.
The new function F(x) is defined as follow:
F(x) = max(Si(x)), i = 1...n. The domain of x is [0, 1000]. Si(x) is a quadric function.
Josephina wonders the minimum of F(x). Unfortunately, it's too hard for her to solve this problem. As a super programmer, can you help her?
Input
The input contains multiple test cases. The first line is the number of cases T (T < 100). Each case begins with a number n(n ≤ 10000). Following n lines, each line contains three integers a (0 ≤ a ≤ 100), b (|b| ≤ 5000), c (|c| ≤ 5000), which mean the corresponding coefficients of a quadratic function.
Output
For each test case, output the answer in a line. Round to 4 digits after the decimal point.
Sample Input
2 1 2 0 0 2 2 0 0 2 -4 2
Sample Output
0.0000 0.5000
分析得,出现最小指的地方必然是函数相交的地方,但是求函数两两相交的交点必然超时
注意到范围[0,1000],而且F(i)在出现最小值的x左右两侧都是单调的
所以用三分解决……
#include<iostream>
#include<stdio.h>
#include<cmath>
#define INF 0x3fffffff
#define eps 1e-10
using namespace std;
#define max(a,b) a>b?a:b
struct FC
{ double a,b,c; }F[10010];
double f(FC fm,double x)
{return fm.a*x*x+fm.b*x+fm.c;}
double calmax(int n,double x)
{
double maxn=-INF;
for(int i=0;i<n;i++)
maxn=max(maxn,f(F[i],x));
return maxn;
}
double solve(int n)
{
double i1=0,i2=0,i3=1000,i4=1000;
while(fabs(i1-i4)>eps)
{
i2=i1+(i4-i1)/3;
i3=i4-(i4-i1)/3;
if(calmax(n,i2)<calmax(n,i3))
i4=i3;
else
i1=i2;
}
return calmax(n,i1);
}
int main()
{
int cas,i,j,n;
scanf("%d",&cas);
while(cas--)
{
scanf("%d",&n);
for(i=0;i<n;i++)
scanf("%lf%lf%lf",&F[i].a,&F[i].b,&F[i].c);
printf("%.4lf/n",solve(n));
}
}
The 2010 ACM-ICPC Asia Chengdu Regional Contest - J
Similarity
Time Limit: 2 Seconds Memory Limit: 65536 KB
When we were children, we were always asked to do the classification homework. For example, we were given words {Tiger, Panda, Potato, Dog, Tomato, Pea, Apple, Pear, Orange, Mango} and we were required to classify these words into three groups. As you know, the correct classification was {Tiger, Panda, Dog}, {Potato, Tomato, Pea} and {Apple, Pear, Orange, Mango}. We can represent this classification with a mapping sequence {A,A,B,A,B,B,C,C,C,C}, and it means Tiger, Panda, Dog belong to group A, Potato, Tomato, Pea are in the group B, and Apple, Pear, Orange, Mango are in the group C.
But the LABEL of group doesn't make sense and the LABEL is just used to indicate different groups. So the representations {P,P,O,P,O,O,Q,Q,Q,Q} and {E,E,F,E,F,F,W,W,W,W} are equivalent to the original mapping sequence. However, the representations {A,A,A,A,B,B,C,C,C,C} and {D,D,D,D,D,D,G,G,G,G} are not equivalent.
The pupils in class submit their mapping sequences and the teacher should read and grade the homework. The teacher grades the homework by calculating the maximum similarity between pupils' mapping sequences and the answer sequence. The definition of similarity is as follow.
Similarity(S, T) = sum(Si == Ti) / L
L = Length(S) = Length(T), i = 1, 2,... L, where sum(Si == Ti) indicates the total number of equal labels in corresponding positions.
The maximum similarity means the maximum similarities between S and all equivalent sequences of T, where S is the answer and fixed.
Now given all sequences submitted by pupils and the answer sequence, you should calculate the sequences' maximum similarity.
Input
The input contains multiple test cases. The first line is the total number of cases T (T < 15). The following are T blocks. Each block indicates a case. A case begins with three numbers n (0 < n < 10000), k (0 < k < 27), m (0 < m < 30), which are the total number of objects, groups, and students in the class. The next line consists of n labels and each label is in the range [A...Z]. You can assume that the number of different labels in the sequence is exactly k. This sequence represents the answer. The following are m lines, each line contains n labels and each label also is in the range [A...Z]. These m lines represent the m pupils' answer sequences. You can assume that the number of different labels in each sequence doesn't exceed k.
Output
For each test case, output m lines, each line is a floating number (Round to 4 digits after the decimal point). You should output the m answers in the order of the sequences appearance.
Sample Input
2
10 3 3
A A B A B B C C C C
F F E F E E D D D D
X X X Y Y Y Y Z Z Z
S T R S T R S T R S
3 2 2
A B A
C D C
F F E
Sample Output
1.0000
0.7000
0.5000
1.0000
0.6667
KM最优匹配,将标准答案串T与输入串S的每一位连线
左右各26个字母,求最大匹配。
#include<iostream> #include<string> #include<stdio.h> #include<memory.h> using namespace std; #define maxn 10010 #define maxm 30 #define INF 0xfffffff int visit_x[maxm], visit_y[maxm], mat[maxm][maxm]; int x[maxm], y[maxm],tlink[maxm]; int T[maxn] , S[maxn] ; int N, M, slack; int DFS(int t) { int i, tmp; visit_x[t] = 1; for (i = 0; i < M; i++) { if (!visit_y[i]){ tmp = x[t] + y[i] - mat[t][i]; if (tmp == 0) { visit_y[i] = 1; if (tlink[i] == -1 || DFS(tlink[i])) { tlink[i] = t; return 1; } } else if (tmp < slack) slack = tmp; } } return 0; } int KM(){ int i, j; for (i = 0; i < N; i++) { x[i] = 0; for (j = 0; j < M; j++) { if (mat[i][j] > x[i]) x[i] = mat[i][j]; } } for (j = 0; j < M; j++) { y[j] = 0; } memset(tlink, -1, sizeof(tlink)); for (i = 0; i < N; i++) { while (1) { memset(visit_x, 0, sizeof(visit_x)); memset(visit_y, 0, sizeof(visit_y)); slack = INF; if (DFS(i)) break; for (j = 0; j < N; j++) { if (visit_x[j]) x[j] -= slack; } for (j = 0; j < M; j++) { if (visit_y[j]) y[j] += slack; } } } int ans=0; for(i=0;i<N;i++) ans+=x[i]+y[i]; return ans; } int main() { int test,t ,K,i,j,tn,cas; double ans; char in[3]; scanf("%d" ,&test); while(test--) { scanf("%d%d%d" , &N , &K ,&K); tn=N; for(i = 0 ; i < N ; ++ i) { scanf("%s",in); T[i] = in[0]-'A' ; } for(cas=0;cas<K;cas++) { N=tn; for(i=0;i<=26;i++) for(j=0;j<=26;j++) mat[i][j]=0; for(i = 0 ; i < N ; ++ i) { scanf("%s" ,in) , S[i] = in[0]-'A'; mat[T[i]][S[i]]++; } M=N=26; printf("%.4lf/n",(double)KM()/tn); } } return 0; }