lucene tis和 tii 文件
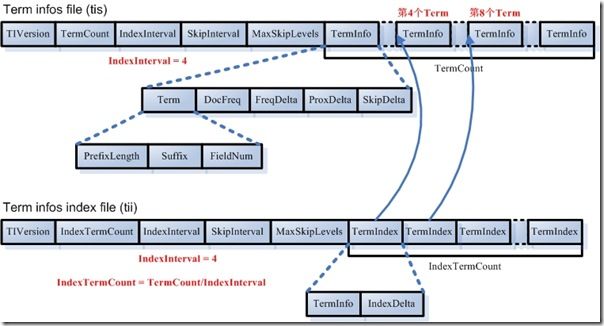
在lucene 中使用 tis 保存了所有term的信息,为了加速检索,还保存了tii文件,他是tis文件的索引,下面图简单的表示了他们之间的关系

上图的左边表示tis中保存的所有的term ,右边tii是保存需要索引的term以及在tis中的位置,这样通过检索tii文件,定位到我们需要查找的term的大概位置,再通关过遍历(或者二分)找到term。 这样做好像比直接对所有的term建立索引会复杂了点,但是它有个好处,就是对tis中的term可以进行压缩(前缀压缩)
我们再引用一位高手的图,来说明整个结构
我们从代码的角度来看看,上面建立的过程
/lucene/src/org/apache/lucene/index/TermInfosWriter.java
添加一个term信息
/** Adds a new <<fieldNumber, termBytes>, TermInfo> pair to the set. Term must be lexicographically greater than all previous Terms added. TermInfo pointers must be positive and greater than all previous.*/ void add(int fieldNumber, byte[] termBytes, int termBytesLength, TermInfo ti) throws IOException { assert compareToLastTerm(fieldNumber, termBytes, termBytesLength) < 0 || (isIndex && termBytesLength == 0 && lastTermBytesLength == 0) : "Terms are out of order: field=" + fieldInfos.fieldName(fieldNumber) + " (number " + fieldNumber + ")" + " lastField=" + fieldInfos.fieldName(lastFieldNumber) + " (number " + lastFieldNumber + ")" + " text=" + new String(termBytes, 0, termBytesLength, "UTF-8") + " lastText=" + new String(lastTermBytes, 0, lastTermBytesLength, "UTF-8"); assert ti.freqPointer >= lastTi.freqPointer: "freqPointer out of order (" + ti.freqPointer + " < " + lastTi.freqPointer + ")"; assert ti.proxPointer >= lastTi.proxPointer: "proxPointer out of order (" + ti.proxPointer + " < " + lastTi.proxPointer + ")"; //写tis文件 //如果是 term数据(!isIndex),每隔 indexInterval个term需要往 tii文件中添加一个term, 简单讲,就是每隔n个,保留一个完整的term if (!isIndex && size % indexInterval == 0) other.add(lastFieldNumber, lastTermBytes, lastTermBytesLength, lastTi); // add an index term writeTerm(fieldNumber, termBytes, termBytesLength); // write term output.writeVInt(ti.docFreq); // write doc freq output.writeVLong(ti.freqPointer - lastTi.freqPointer); // write pointers output.writeVLong(ti.proxPointer - lastTi.proxPointer); //?? if (ti.docFreq >= skipInterval) { output.writeVInt(ti.skipOffset); } //System.out.println(termBytes); //如果是tii ,那么需要谢入tis 文件的位置信息,便于检索 if (isIndex) { output.writeVLong(other.output.getFilePointer() - lastIndexPointer); lastIndexPointer = other.output.getFilePointer(); // write pointer } lastFieldNumber = fieldNumber; lastTi.set(ti); size++; }
这个过程对于tis 和 tii通用的,这里的index 变脸表示是 tis还是tii文件
1 如果是tis ,那么每隔n个需要往tii文件中索引一个term
2 调用writeTerm 写term词
3 写docFreq (term 出现的多少个doc ) , FreqPoint (出现doclist 的指针) ProxPoint(位置指针)
4 如果需要使用跳表,那么就写入跳表的下标
5 对于tii,需要写入term 在tis文件中的位置
下面,我们来看看writeTerm 实现
//采用前缀压缩保存term信息 private void writeTerm(int fieldNumber, byte[] termBytes, int termBytesLength) throws IOException { // TODO: UTF16toUTF8 could tell us this prefix // Compute prefix in common with last term: // 和上个 term 计算公共前缀 int start = 0; final int limit = termBytesLength < lastTermBytesLength ? termBytesLength : lastTermBytesLength; while(start < limit) { if (termBytes[start] != lastTermBytes[start]) break; start++; } //前缀 、后缀长度, 后缀内容, 字段序号 final int length = termBytesLength - start; output.writeVInt(start); // write shared prefix length output.writeVInt(length); // write delta length output.writeBytes(termBytes, start, length); // write delta bytes output.writeVInt(fieldNumber); // write field num //当前term设置为最新term if (lastTermBytes.length < termBytesLength) { lastTermBytes = ArrayUtil.grow(lastTermBytes, termBytesLength); } System.arraycopy(termBytes, start, lastTermBytes, start, length); lastTermBytesLength = termBytesLength; }
1 计算前缀
2 写入前缀长度、后缀长度、后缀内容,字段序号, 从这里可以看出,上面的那个图中的term信息遗漏了后缀内容
最后我们看看term信息的读取,其实就是一个相反的过程
/lucene/src/org/apache/lucene/index/SegmentTermEnum.java
/** Increments the enumeration to the next element. True if one exists.*/ @Override public final boolean next() throws IOException { if (position++ >= size - 1) { prevBuffer.set(termBuffer); termBuffer.reset(); return false; } prevBuffer.set(termBuffer); termBuffer.read(input, fieldInfos); termInfo.docFreq = input.readVInt(); // read doc freq termInfo.freqPointer += input.readVLong(); // read freq pointer termInfo.proxPointer += input.readVLong(); // read prox pointer if(format == -1){ // just read skipOffset in order to increment file pointer; // value is never used since skipTo is switched off if (!isIndex) { if (termInfo.docFreq > formatM1SkipInterval) { termInfo.skipOffset = input.readVInt(); } } } else{ if (termInfo.docFreq >= skipInterval) termInfo.skipOffset = input.readVInt(); } if (isIndex) indexPointer += input.readVLong(); // read index pointer return true; }
用户检索的时候,就是一个查找过程,lucene 采用 二分 + 遍历的方法
/lucene/src/org/apache/lucene/index/TermInfosReader.java
/** Returns the position of a Term in the set or -1. */ final long getPosition(Term term) throws IOException { if (size == 0) return -1; ensureIndexIsRead(); int indexOffset = getIndexOffset(term); SegmentTermEnum enumerator = getThreadResources().termEnum; seekEnum(enumerator, indexOffset); while(term.compareTo(enumerator.term()) > 0 && enumerator.next()) {} if (term.compareTo(enumerator.term()) == 0) return enumerator.position; else return -1; }
其中getIndexOffset 就是采用二分法在tii 中进行检索
/** Returns the offset of the greatest index entry which is less than or equal to term.*/ private final int getIndexOffset(Term term) { int lo = 0; // binary search indexTerms[] int hi = indexTerms.length - 1; while (hi >= lo) { int mid = (lo + hi) >>> 1; int delta = term.compareTo(indexTerms[mid]); if (delta < 0) hi = mid - 1; else if (delta > 0) lo = mid + 1; else return mid; } return hi; }