Linux 系统资源监控常用命令
Linux 系统由若干主要物理组件组成,如 CPU、内存、网卡和存储设备。要有效地管理 Linux 环境,您应该能够以合理的精度测量这些资源的
各种指标 — 每个组件处理多少资源、是否存在瓶颈等。 下面我们介绍下linux资源监控有关的一些命令:
内存 : top、free、vmstat、mpstat、iostat、sar 、 pmap
CPU : top、vmstat、mpstat、iostat、sar
I/O : vmstat、mpstat、iostat、sar
进程 : ipcs、ipcrm
系统运行负载:uptime、w
1,top
运行 top 命令后,CPU 使用状态会以全屏的方式显示,并且会处在对话的模式 – 用基于 top 的命令,可以控制显示方式等等。
退出 top 的命令为 q (在 top 运行中敲 q 键一次)。
作用:
top命令用来显示执行中的程序进程,使用权限是所有用户。
格式:
top [-] [d delay] [q] [c] [S] [s] [i] [n]
主要参数:
d:指定更新的间隔,以秒计算。
q:没有任何延迟的更新。如果使用者有超级用户,则top命令将会以最高的优先序执行。
c:显示进程完整的路径与名称。
S:累积模式,会将己完成或消失的子行程的CPU时间累积起来。
s:安全模式。
i:不显示任何闲置(Idle)或无用(Zombie)的行程。
n:显示更新的次数,完成后将会退出top。
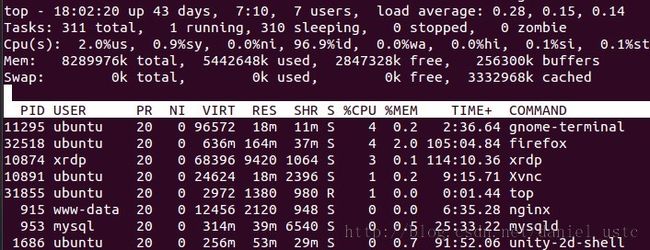
第一行表示的项目依次为当前时间、系统启动时间、当前系统登录用户数目、平均负载(最近1,5,15分钟)。
第二行显示的是所有启动的进程、目前运行的、挂起(Sleeping)的和无用(Zombie)的进程。
第三行显示的是目前CPU的使用情况,包括系统占用的比例、用户使用比例、闲置(Idle)比例。
第四行显示物理内存的使用情况,包括总的可以使用的内存、已用内存、空闲内存、缓冲区占用的内存。
第五行显示交换分区使用情况,包括总的交换分区、使用的、空闲的和用于高速缓存的大小。
第六行显示的项目最多,下面列出了详细解释。
PID(Process ID):进程标示号。
USER:进程所有者的用户名。
PR:进程的优先级别。
NI:进程的优先级别数值。
VIRT:进程占用的虚拟内存值。
RES:进程占用的物理内存值。
SHR:进程使用的共享内存值。
S:进程的状态,其中S表示休眠,R表示正在运行,Z表示僵死状态,N表示该进程优先值是负数。
%CPU:该进程占用的CPU使用率。
%MEM:该进程占用的物理内存和总内存的百分比。
TIME+:该进程启动后占用的总的CPU时间。
Command:进程启动的启动命令名称,如果这一行显示不下,进程会有一个完整的命令行。
top命令使用过程中,还可以使用一些交互的命令来完成其它参数的功能。这些命令是通过快捷键启动的。
<空格键>:立刻刷新。
P:根据CPU使用大小进行排序。
T:根据时间、累计时间排序。
q:退出top命令。
m:切换显示内存信息。
t:切换显示进程和CPU状态信息。
c:切换显示命令名称和完整命令行。
M:根据使用内存大小进行排序。
W:将当前设置写入~/.toprc文件中。这是写top配置文件的推荐方法。
top命令是一个功能十分强大的监控系统的工具,对于系统管理员而言尤其重要。
2,uptime 命令
作用:
Unix 命令,显示系统已经运行了多长时间。
它依次显示下列信息:
当前时间、系统已经运行了多长时间、目前有多少登陆用户、系统在过去的1分钟、5分钟和15分钟内的平均负载。
一般 load avarage <3 系统良好,大于5 则有严重的性能问题,平均负载的最佳值是1,这意味着每个进程都可以立
即执行不会错过CPU周期。注意,这个值还应当除以CPU数目。如果load avarage=8 ,CPU=3,8/3=2.666,
2.66这个值表示系统状态良好.
![]()
提示:你可以使用 w 命令来代替 uptime。w 也提供关于当前系统登录用户和用户所进行工作的相关信息。
3,free
作用:
free命令用来显示内存的使用情况,使用权限是所有用户。
格式:
free [-b-k-m] [-o] [-s delay] [-t] [-V]
主要参数:
-b -k -m:分别以字节(B、KB、MB)为单位显示内存使用情况。
-s delay:显示每隔多少秒数来显示一次内存使用情况。
-t:显示内存总和列。
-o:不显示缓冲区调节列。
举例:
free命令是用来查看内存使用情况的主要命令。和top命令相比,它的优点是使用简单,并且只占用很少的系统资源。
通过-S参数可以使用free命令不间断地监视有多少内存在使用,这样可以把它当作一个方便实时监控器。
如下:
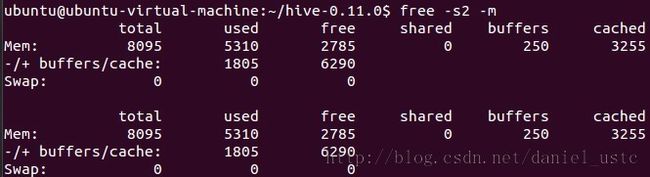
free -s2 -m 使用这个命令后终端会连续不断地报告内存使用情况(以MB为单位),每2秒更新一次。
此外为了获得详细的内存信息可以查看/proc/meminfo. Meminfo 可让你获取内存的详细信息,你可以使用 cat 和 grep 命令来显示
meminfo 信息:cat/proc/meminfo
4,vmstat
你可以使用 vmstat 来监控虚拟内存,一般 Linux 上的开发者喜欢使用虚拟内存来获得最佳的存储性能。该命令报告关于内核线程、
虚拟内存、磁盘、陷阱和 CPU 活动的统计信息。由 vmstat 命令生成的报告可以用于平衡系统负载活动。系统范围内的这些统计
信息(所有的处理器中)都计算出以百分比表示的平均值,或者计算其总和。
一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,如:
vmstat <interval> <count>
interval 是两次运行之间的时间间隔,以秒为单位。 count 是 vmstat 重复的次数。
比如我们希望 vmstat 每隔 5 秒运行一次并在第 2次运行后停止时的示例。 每 5 秒之后都会输出一行并显示此时的统计信息。

该输出显示有关系统资源的信息:
procs 显示进程数
r 等待运行的进程。系统上的负载越多,等待运行 CPU 周期的进程数量越多。
b 不可中断睡眠的进程,也称为“被阻塞”的进程。这些进程最有可能等待 I/O,但也可能等待其他事情。
wpd,free,buff,cache显示了内存值
wpd 虚拟内存或交换内存的数量(以 KB 为单位)
free 可用物理内存的数量(以 KB 为单位)
buff 用作缓冲区的内存数量(以 KB 为单位)
cache 用作缓存的物理内存数量(以 KB 为单位)
si so 显示了交换活动:
si 将内存从磁盘交换回物理 RAM 的速率(以 KB/秒为单位)
so 将内存从物理 RAM 交换到磁盘的速率(以 KB/秒为单位)
bi,bo显示了 I/O 活动:
bi 系统向块设备发送数据的速率(以块/秒为单位)
bo 系统从块设备中读取数据的速率(以块/秒为单位)
in,cs 显示了系统相关活动:
in 系统每秒接收到的中断数
cs 在进程空间中切换上下文的速率(以数量/秒为单位)
us,sy,id,wa 显示了 CPU 负载的信息:
us 显示花费在用户进程中的 CPU 百分比。Oracle 进程属于这一类。
sy 系统进程(如所有根进程)使用的 CPU 百分比
id 可用 CPU 百分比
wa 花费在“等待 I/O”上的百分比
理想情况下,等待或阻塞的进程数量(位于“procs”下)应该为 0 或接近于 0。 如果数值较高,则表示系统没有足够的资源
(如 CPU、内存或 I/O)。
如果您看到“proc”和“b”列(正在阻塞的进程)下有较大的数值和较高的 I/O,则可能出现了严重的 I/O 争用问题。
“swap”下的数据表明交换是否过多。如果交换过多,则表明物理内存可能不足。应该减少内存需求或增加物理 RAM。
“io”下的数据表示往返于磁盘的数据流。这表明正在进行的磁盘活动量,这并不一定表明存在问题。
“cpu”标题下是最有用的信息。“id”列显示空闲 CPU。如果用 100 减去该数值,则会得到繁忙 CPU 的百分比。
CPU 的空闲百分比(和top的区别):top 显示每个 CPU 的空闲百分比,而 vmstat 显示所有 CPU 的空闲百分比。
如果系统显示较高的数值,请使用 top 命令确定占有 CPU 的系统进程 。
5,mpstat
mpstat mpstat是MultiProcessor Statistics的缩写,是实时系统监控工具。其报告与CPU的一些统计信息,这些信息存放在/proc/stat
文件中。在多CPUs系统里,其不但能查看所有CPU的平均状况信息,而且能够查看特定CPU的信息。
语法:mpstat [ { -d | -i | -s | -a } ] [ -w ] [ interval [ count ] ]
描述:mpstat 命令收集和显示系统中所有逻辑 CPU 的性能统计信息。用户既可以定义统计信息显示的次数,也可以定义数据更新的
时间间隔。调用 mpstat 命令时,它显示两部分的统计信息。第一部分显示系统配置,在命令开始执行时以及只要系统配置发生更改时
显示。第二部分显示使用率统计数据,每隔一定时间间隔显示,并且只要度量值与上一时间间隔有变化便会重新显示。
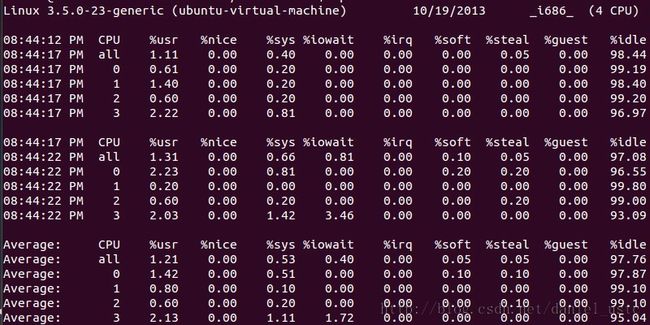
让我们看一看这些列值的含义:
%user 表示处理用户进程所使用 CPU 的百分比。用户进程是用于应用程序(如 Oracle 数据库)的非内核进程。
在本示例输出中,用户 CPU 百分比非常低。
%nice 表示使用 nice 命令对进程进行降级时 CPU 的百分比。在之前的部分中已经对 nice 命令进行了介绍。简单来说,nice 命令更改进程的优先级。
%system 表示内核进程使用的 CPU 百分比
%iowait 表示等待进行 I/O 所使用的 CPU 时间百分比
%irq 表示用于处理系统中断的 CPU 百分比
%soft 表示用于软件中断的 CPU 百分比
%idle 显示 CPU 的空闲时间
%intr/s 显示每秒 CPU 接收的中断总数
vmstat 和 mpstat 的区别:mpstat 可以显示每个处理器的统计, 而 vmstat 显示所有处理器的统计。因此,编写比较差的应用程序(不使用多线程体系结构)
可能会运行在一个多处理器机器上, 而不使用所有处理器。从而导致一个 CPU 过载,而其他 CPU却很空闲。通过 mpstat 可以轻松诊断这些类型的问题。
6,netstat
Netstat 和 ps 命令类似,是 Linux 管理员基本上每天都会用的工具,它显示了大量跟网络相关的信息,例如 socket 的使用、路由、接口、协议、网络等等,
下面是一些常用的参数:
-a (all)显示所有选项,默认不显示LISTEN相关
-t (tcp)仅显示tcp相关选项
-u (udp)仅显示udp相关选项
-n 拒绝显示别名,能显示数字的全部转化成数字。
-l 仅列出有在 Listen (监听) 的服務状态
-p 显示建立相关链接的程序名
-r 显示路由信息,路由表
-e 显示扩展信息,例如uid等
-s 按各个协议进行统计
-c 每隔一个固定时间,执行该netstat命令。
提示:LISTEN和LISTENING的状态只有用-a或者-l才能看到

更多netstat具体详情参考链接:http://www.cnblogs.com/ggjucheng/archive/2012/01/08/2316661.html
其实ss命令在多数情况下已经取代了netstat. ss是Socket Statistics的缩写,ss命令可以用来获取socket统计信息,它可以显示和netstat类似的内容。
但ss的优势在于它能够显示更多更详细的有关TCP和连接状态的信息,而且比netstat更快速更高效。使用方法参考 Linux网络状态工具ss命令使用详解。
7,iostat
性能评估的一个主要部分就是磁盘性能。iostat 命令提供了存储接口的性能指标,通常用它来监控磁盘 I/O 的情况。要特别注意 iostat 统
计结果中的 %iowait 值,太大了表明你的系统存储子系统性能低下。

输出的开始部分显示了可用 CPU 和 I/O 等待时间等指标,与您在 mpstat 命令中看到的相同。
输出的下一部分显示对系统上每个磁盘设备非常重要的指标。让我们看一看这些列的含义:
tps 每秒的传输数量,例如,每秒的 I/O 操作数。注:这只是 I/O 操作的数量;每个操作可能非常大,也可能非常小。
Blk_read/s 每秒从该设备读取的块数。通常,块的大小为 512 字节。这是一个磁盘利用率较好的值。
Blk_wrtn/s 每秒写入该设备的块数
Blk_read 到目前为止从该设备读取的块数。注意,这并不是正在发生的情况。很多块已经从该设备读取。
可能现在什么也没有读取。观察一段时间,看是否有变化。
Blk_wrtn 写入该设备的块数。
可以通过将该设备作为参数传递只获得特定设备的指标。如 iostat vda
具体详细内容参见:http://blog.csdn.net/evils798/article/details/7524486
8,sar
sar 代表 System Activity Recorder。
sar 程序是系统监控工具里的瑞士军刀。该程序包含三个工具:sar 用来显示数据,sa1 和 sa2 用来收集数据并保存。sar 可用来显示
CPU 使用率、内存页数据、网络 I/O 和传输统计、进程创建活动和磁盘设备的活动详情。sar 和 nmon 最大的不同就是 sar 跟适合用作
长期的监控。
sar 它在一个特殊的位置(/var/log/sa 目录)记录 Linux 系统的主要组件(CPU、内存、磁盘、网络等)的指标。
每天的数据记录在一个名为 sa<nn> 的文件中,其中 <nn> 是每月中的第 nn 天(两位数字)。
例如,文件 sa27 包含该月第 27 日的数据。可以通过 sar 命令查询该数据。
详情参见:http://blog.csdn.net/evils798/article/details/7524501
9,ps 和 pstree
ps 和 pstree 命令是 Linux 系统管理员最好的朋友,都可以用来列表正在运行的所有进程。ps 告诉你每个进程占用的内存和 CPU 处理时间,
而 pstree 显示的信息没那么详细,但它以树形结构显示进程之间的依赖关系,包括子进程信息.一旦发现某个进程有问题,你可以使用 kill 来杀掉它。
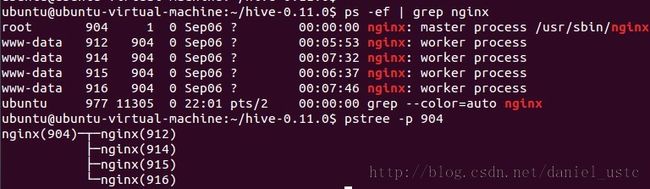
ps是个很有用的命令,可以man一下查看详情。
10,pmap
pmap 命令用来报告每个进程占用内存的详细情况,可用来看是否有进程超支了,该命令需要进程 id 作为参数。
你可以使用这个工具来了解服务器上的某个进程分配了多少内存,并以此来判断这是否是导致内存瓶颈的原因。
要得到更加详细的信息,使用pmap -d选项。
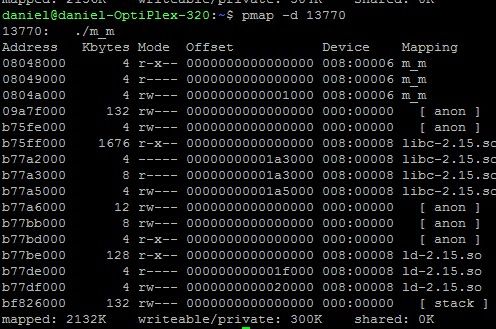
最后一行的值mapped 表示该进程映射的虚拟地址空间大小,也就是该进程预先分配的虚拟内存大小,即ps出的vsz。
writeable/private 表示进程所占用的私有地址空间大小,也就是该进程实际使用的内存大小。
shared 表示进程和其他进程共享的内存大小。
几点总结:
pmap -d 结论:
1, mapped 和writeable/private 能够反映内存的变化.
2, delete 和free 不能在 mapped 和writeable/private 立即反映出来,比方删除100k就没有变化.
pmap -x 结论:
1, 尽管你已经调用了 new分配内存(step 3), 但是 OS不一定一下把所有的page都分配。
2, 多次相同的new操作可能在不同的[anon]虚拟地址空间分配。
11,strace
strace 经常被认为是程序员调试的工具,但不止如此。它可以记录进程进行系统调用的详情,因此它也是一个非常好的诊断工具,例如你可以使用
它来找出某个程序正在打开某个配置文件。Strace 也有一个缺陷,但它在跟踪某个进程时会让该进程的性能变得非常差,因此请谨慎使用。
12,tcpdump
Tcpdump 是一个简单、可靠的网络监控工具,用来做基本的协议分析,看看那些进程在使用网络以及如何使用网络。当然,如果你要获取跟详细的信息,
你应该使用 Wireshark (比较好用).
13,ipcs、ipcrm
ipcs - 分析消息队列、共享内存和信号量
它的语法:
ipcs [-mqs] [-abcopt] [-C core] [-N namelist]
-m 输出有关共享内存(shared memory)的信息
-q 输出有关信息队列(message queue)的信息
-s 输出信号量(semaphore)的信息
ipcrm - 删除ipc(清除共享内存信息)
它的语法:
ipcrm -m|-q|-s shm_id
-m 输出有关共享内存(shared memory)的信息
-q 输出有关信息队列(message queue)的信息
-s 输出信号量(semaphore)的信息
shm_id 共享内存id
#ipcrm -m 501
好了,先介绍到这里以上这些神器需要常用 才能够熟练!