Linux 的内核调试
※ 调试工作艰苦,是内核级开发区别于用户级开发的一个显著特点。
※ 驾驭内核调试的能力,很大程度上取决于经验和对整个操作系统的把握。
一、调试前的准备
内核级bug具有行为不可靠,定义不清晰或者说很难再现的诸多特定,为内核级的bug跟踪和调试带来了很大的困难。
※ 对于一些定义不清楚地bug,问题的关键就是找到bug的源头,很多时候,当你精确地重现一个bug的时候,你就离成功不远了。
二、内核中的bug
从隐藏在源代码中的错误到展现在目击者面前的bug,其发作往往是一系列连锁反应的事件才可能出发的。
虽然内核调试有一定的困难,但是通过你的努力和理解,说不定你会喜欢上这样的挑战。
三、printk( )
内核提供的格式化打印函数。
1、printk函数的健壮性
健壮性是printk最容易被接受的一个特质,几乎在任何地方,任何时候内核都可以调用它(中断上下文、进程上下文、持有锁时、多处理器处理时等)。
※ 在系统启动过程中,终端初始化之前,在某些地方是不能调用的。
2、记录等级
printk函数可以指定一个记录级别,内核根据这个级别来判断是否在终端上打印消息。
记录级别定义在<linux/kernel.h>中:
#define
KERN_EMERG "<0>" /* system is unusable */
#define KERN_ALERT "<1>" /* action must be taken immediately */
#define KERN_CRIT "<2>" /* critical conditions */
#define KERN_ERR "<3>" /* error conditions */
#define KERN_WARNING "<4>" /* warning conditions */
#define KERN_NOTICE "<5>" /* normal but significant condition */
#define KERN_INFO "<6>" /* informational */
#define KERN_DEBUG "<7>" /* debug-level messages */
#define KERN_ALERT "<1>" /* action must be taken immediately */
#define KERN_CRIT "<2>" /* critical conditions */
#define KERN_ERR "<3>" /* error conditions */
#define KERN_WARNING "<4>" /* warning conditions */
#define KERN_NOTICE "<5>" /* normal but significant condition */
#define KERN_INFO "<6>" /* informational */
#define KERN_DEBUG "<7>" /* debug-level messages */
调用方式:printk(KER_DEBUG “This is a debug notice!/n”);
内核用这个指定的纪录等级和当前终端的纪录等级console_loglevel比较,来决定是不是向终端打印。
关于< linux/kernel.h >的console_loglevel 定义:
#define console_loglevel (console_printk[0])
<printk.c>定义:
int console_printk[4] = {
DEFAULT_CONSOLE_LOGLEVEL, /* console_loglevel */
DEFAULT_MESSAGE_LOGLEVEL, /* default_message_loglevel */
MINIMUM_CONSOLE_LOGLEVEL, /* minimum_console_loglevel */
DEFAULT_CONSOLE_LOGLEVEL, /* default_console_loglevel */
};
3、记录缓冲区
内核消息都被保存在一个LOG_BUF_LEN大小的环形队列中。
关于LOG_BUF_LEN定义:
#define __LOG_BUF_LEN (1 << CONFIG_LOG_BUF_SHIFT)
※ 变量CONFIG_LOG_BUF_SHIFT在内核编译时由配置文件定义,对于i386平台,其值定义如下(在linux26/arch/i386/defconfig中):
CONFIG_LOG_BUF_SHIFT=18
记录缓冲区操作:
①、消息被读出到用户空间时,此消息就会从环形队列中删除。
②、当消息缓冲区满时,如果再有printk()调用时,新消息将覆盖队列中的老消息。
③、在读写环形队列时,同步问题很容易得到解决。
※ 这个纪录缓冲区之所以称为环形,是因为它的读写都是按照环形队列的方式进行操作的。
4、syslogd和klogd
在标准的Linux系统上,用户空间的守护进程klogd从纪录缓冲区中获取内核消息,再通过syslogd守护进程把这些消息保存在系统日志文件中。klogd进程既可以从/proc/kmsg文件中,也可以通过syslog()系统调用读取这些消息。默认情况下,它选择读取/proc方式实现。klogd守护进程在消息缓冲区有新的消息之前,一直处于阻塞状态。一旦有新的内核消息,klogd被唤醒,读出内核消息并进行处理。默认情况下,处理例程就是把内核消息传给syslogd守护进程。
syslogd守护进程一般把接收到的消息写入/var/log/messages文件中。不过,还是可以通过/etc/syslog.conf文件来进行配置,可以选择其他的输出文件。
图1 X光了此过程:

四、OOPS
OOPS(也称 Panic)消息包含系统错误的细节,如 CPU 寄存器的内容等。是内核告知用户有不幸发生的最常用的方式。
内核只能发布OOPS,这个过程包括向终端上输出错误消息,输出寄存器保存的信息,并输出可供跟踪的回溯线索。通常,发送完OOPS之后,内核会处于一种不稳定的状态。
OOPS的产生有很多可能原因,其中包括内存访问越界或非法的指令等。
※ 作为内核的开发者,必定将会经常处理OOPS。
※ OOPS中包含的重要信息,对所有体系结构的机器都是完全相同的:寄存器上下文和回溯线索(回溯线索显示了导致错误发生的函数调用链)。
1、ksymoops
在 Linux 中,调试系统崩溃的传统方法是分析在发生崩溃时发送到系统控制台的 Oops 消息。一旦您掌握了细节,就可以将消息发送到 ksymoops 实用程序,它将试图将代码转换为指令并将堆栈值映射到内核符号。
※ 如:回溯线索中的地址,会通过ksymoops转化成名称可见的函数名。
图2X光了格式化 Oops 消息过程:
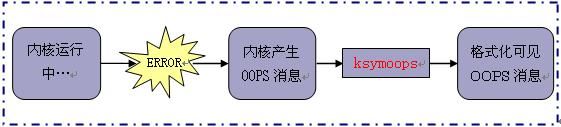
ksymoops需要几项内容:Oops 消息输出、来自正在运行的内核的 System.map 文件,还有 /proc/ksyms、vmlinux 和 /proc/modules。
关于如何使用 ksymoops,内核源代码 /usr/src/linux/Documentation/oops-tracing.txt 中或 ksymoops 手册页上有完整的说明可以参考。Ksymoops 反汇编代码部分,指出发生错误的指令,并显示一个跟踪部分表明代码如何被调用。
2、kallsyms
开发版2.5内核引入了kallsyms特性,它可以通过定义CONFIG_KALLSYMS编译选项启用。该选项可以载入内核镜像所对应的内存地址的符号名称(即函数名),所以内核可以打印解码之后的跟踪线索。相应,解码OOPS也不再需要System.map和ksymoops工具了。另外,
这样做,会使内核变大些,因为地址对应符号名称必须始终驻留在内核所在内存上。
#cat /proc/kallsyms
c0100240 T _stext
c0100240 t run_init_process
c0100240 T stext
c0100269 t init
…
五、内核调试配置选项
在编译内核的时候,为了方便调试和测试代码,内核提供了许多配置选项。
※ 启用选项例如:
slab layer debugging(slab层调试选项)、high-memory debugging(高端内存调试选项)、I/O mapping debugging(I/O映射调试选项)、spin-lock debugging(自旋锁调试选项)、stack-overflow checking(栈溢出检查选项)和sleep-inside-spinlock checking(自旋锁内睡眠选项)等。
1、调试原子操作
从内核2.5开发,为了检查各类由原子操作引发的问题,内核提供了极佳的工具。
内核提供了一个原子操作计数器,它可以配置成,一旦在原子操作过程中,进城进入睡眠或者做了一些可能引起睡眠的操作,就打印警告信息并提供追踪线索。
所以,包括在使用锁的时候调用schedule(),正使用锁的时候以阻塞方式请求分配内存等,各种潜在的bug都能够被探测到。
下面这些选项可以最大限度地利用该特性:
CONFIG_PREEMPT = y
CONFIG_DEBUG_KERNEL = y
CONFIG_KLLSYMS = y
CONFIG_SPINLOCK_SLEEP = y
六、引发bug并打印信息
1、一些内核调用可以用来方便标记bug,提供断言并输出信息。最常用的两个是BUG()和BUG_ON()。
定义在<include/asm-generic>中:
#ifndef HAVE_ARCH_BUG
#define BUG() do {
printk( " BUG: failure at %s:%d/%s()! " , __FILE__, __LINE__, __FUNCTION__);
panic( " BUG! " ); /* 引发更严重的错误,不但打印错误消息,而且整个系统业会挂起 */
} while ( 0 )
#endif
#ifndef HAVE_ARCH_BUG_ON
#define BUG_ON(condition) do { if (unlikely(condition)) BUG(); } while(0)
#endif
当调用这两个宏的时候,它们会引发OOPS,导致栈的回溯和错误消息的打印。
※ 可以把这两个调用当作断言使用,如:BUG_ON(bad_thing);
2、dump_stack()
有些时候,只需要在终端上打印一下栈的回溯信息来帮助你调试。这时可以使用dump_stack()。这个函数只在终端上打印寄存器上下文和函数的跟踪线索。
if (!debug_check) {
printk(KERN_DEBUG “provide some information…/n”);
dump_stack();
}
备注:大部分内容引自《Linux内核设计与实现 - 第2版》