linux开发过程 --GNU
2.3 GNU二进制工具集
GNU GCC是任何Linux开发环境中可见的也是最明显的一个组成部分,但它却非常依赖于一些外部工具来实际代表Linux开发者执行有用的工作。这些外部工具许多是由GNU的二进制工具集提供的,它是一组工具的集合,用于产生和控制Linux中的二进制应用程序代码。
每个二进制工具都有其特定的目的并出色地完成某一项任务,这遵循了标准的UNIX哲学。有一些工具的用途较为明显,但对于编译大型复杂的软件项目(如Linux内核)来说,每一个工具都是必需的。成千上万的开发人员每天都会依赖这些工具来完成工作,但其中许多人可能甚至都没有意识到这一点。即便你不会直接使用这些工具,但了解它们以及它们所提供的一般功能还是非常重要的。
2.3.1 GNU汇编器
GNU汇编器——它也许是最自然的对应GNU编译器集的工具了。它负责把已编译的C代码(以汇编语言形式表示)转换为能够在某一特定目标处理器上执行的目标代码。GNU as支持许多不同种类的微处理器,其中包括Linux工作站常用的Intel IA32(大部分人称它为“x86”)系列。
安装在你的工作站上的GNU as版本是由Linux发行商针对你的系统所基于的特定处理器类型预配置好的,当然你也可以安装其他配置的版本(更多信息请见2.7节)。但无论你安装的是什么配置的汇编器,它在所有平台上的表现都是类似的。
为了对汇编器的使用进行尝试,你可以要求GCC输出前面的Hello World示例的汇编代码,然后将它汇编为可执行目标代码。要产生一些示例汇编代码,请在编译源文件hello.c时指定“-S”选项标记。
GCC将把你的程序的汇编语言版本输出到文件hello.s。下面是运行在一个Intel工作站上的GCC 4.0所产生的输出:
 |
要学习在Linux上使用GNU的一些有趣的事情,你并不需要理解上面列出的每一行汇编语言代码的含义。目前有许多优秀的关于Linux上Intel汇编语言编程的参考书,例如Professional Assembly Language(Wrox)。你也可以使用Linux来为许多其他体系结构编写汇编语言代码。
在上面列出的汇编语言代码中,请注意源代码是如何通过“.section”命令分为多个段落的。其中每一个段落将在稍后由GNU连接器及其相关的连接器脚本构成程序可执行代码中的各个部分。全局符号也在汇编语言代码中进行了标注,它包括对外部库函数的调用,如puts:
call puts
函数puts由GNU C语言函数库提供。这个函数并不是程序的一部分,但如果以后它通过标准系统函数库连接到程序(例如,当调用GNU连接器来产生可运行的可执行程序文件),程序就可以使用它了。
你可以使用GNU汇编器as来编译源代码hello.s,如下所示:
这将产生文件hello.o,它包含针对指定汇编语言源文件的可执行目标代码。请注意,你现在还不能在自己的Linux工作站上实际地运行这个文件,这是因为它还没有被GNU连接器处理,所以它还没有包含任何Linux系统在试图加载并开始代表你执行应用程序时所必需的额外信息。
2.3.2 GNU连接器
连接是在Linux系统上产生可工作的可执行程序的一个重要阶段。要建立一个可执行程序,源代码必须首先被编译、汇编,然后被连接到一个可以被目标Linux系统理解的标准容器格式(standard container format)。在Linux和现代UNIX/类UNIX系统中,这个容器格式是ELF(Executable and Linking Format,可执行和连接格式)。它既是已编译目标代码和应用程序的文件格式选择,也是GNU ld的格式选择。
Linux应用程序存储在ELF文件中,它由许多段落构成。其中包括程序自身的代码段和数据段以及各种和应用程序本身相关的元数据。如果没有经过适当的连接阶段,一个可执行程序就不会包含足够多的额外数据以让Linux运行时装载器可以成功地装载并执行该程序。虽然程序代码可能已存放在一个特定的目标代码文件中,但这并不足以让它成为一个有用的程序。
除了产生可以在Linux系统上运行的可执行程序以外,连接器还负责确保任何必需的环境设置代码已位于每个要在Linux目标机器上装载并运行的可执行文件的正确位置。在使用GNU C编译代码的情况中,这个启动代码包含在文件crtbegin.o(位于GCC安装目录中)中,在编译程序时它将自动被连接到应用程序。另一个类似的文件crtend.o则提供了在应用程序终止时执行清理退出任务的代码。
连接器的操作
GNU连接器在处理各种目标代码文件并产生所要求的输出时遵循一系列被称为连接器脚本的预编写命令。你的工作站应该已在诸如/usr/lib/ldscripts这样的目录下安装了一些脚本。每当ld需要创建一个特定类型的Linux可执行文件时,它就会使用其中的脚本。你可以查看一下安装在自己系统中的这些脚本以了解隐藏在每个Linux程序背后的复杂性。
在使用GCC编译普通应用程序时,你通常不需要直接调用GNU连接器ld。它的操作相当复杂并且最终决定于你所安装的GCC具体版本和各种外部软件库的位置和版本。如果你想要修改Linux内核的内存布局(当你想为自己的硬件设施创建一个自己的Linux版本时),你就需要理解连接器是如何使用连接器脚本的。
在本书后面讨论Linux内核时,我们将介绍更多有关连接器使用的内容。
2.3.3 GNU objcopy和objdump
GNU二进制工具集中包括几个工具,它们是专用于控制和将二进制目标代码从一种格式转换为另一种格式的。这些工具被称为objcopy和objdump,很多在Linux机器上使用的底层软件在其编译阶段都非常依赖于这些工具,甚至一些普通应用程序在调试时也需要用到它们。
工具objcopy可以用于从一个文件拷贝目标代码到另一个文件,并在这一过程中执行各种转换。通过使用objcopy,我们可以在不同的目标代码格式之间进行自动的转换并操纵这一过程中的内容。objdump和objcopy都建立在非常灵活的bfd二进制操纵函数库之上。这一函数库被许多便利的工具所利用,它们可以以任何你想象的方式来操纵二进制目标文件。
工具objdump用于方便查看可执行文件的内容,并通过执行各种任务使得这一可视化过程更加容易。通过使用objdump,你可以检查本章前面使用的Hello World示例代码的内容。
这些命令开关要求objdump显示二进制文件hello的所有头(-x),试图反汇编任一可执行段落的内容(-d)并将程序的源代码与其对应的反汇编代码混合显示(-S)。最后一个选项只会在某些情况下产生可读的输出。这通常需要使用完整的调试信息(使用GCC命令的“-g”开关)来编译源文件,并且没有进行任何GCC指令调度优化(为了增加可读性)。
objdump产生的输出可能与下面的输出结果类似。这里,你可以看到在一个运行Linux的PowerPC平台上通过objdump输出的Hello World示例程序头部分的内容:
 |
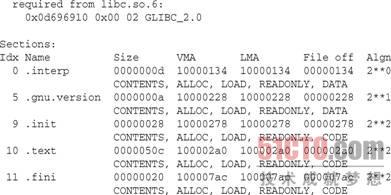 |
ELF头表明这是一个32位的PowerPC目标文件。因为Linux是一个可移植的操作系统,所以作者在各种不同的Linux平台(如PowerPC)上编写和测试本书中的示例。由于ELF本身也是一种跨平台的二进制标准,所以在objdump的输出中没有提及Linux。理论上来说,你可以在任何一台遵循同一个ABI(Application Binary Interface,应用程序二进制接口)并有能力装载ELF文件及其函数库的PowerPC操作系统中运行这段代码。
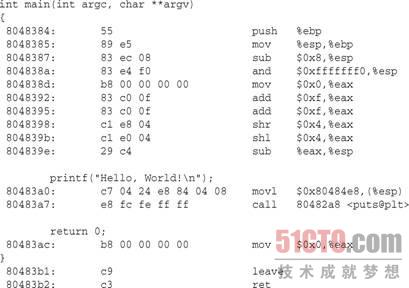
如果我们使用gcc命令的“-g”调试标记来编译源代码,那么objdump的输出还可以包含应用程序源代码的完整反汇编代码。下面是在一台IA32(x86)Linux工作站上的objdump的部分输出结果,它显示了main函数的反汇编代码和对应的源代码:
 |
2.4 GNU Make
正如前面已指出的,Linux机器上的大多数软件是通过GNU make来编译的。从本质上来说,GNU make只是一个简单的依赖性跟踪工具,它遵循一系列的规则以确定对一个大型项目中每个单独源文件必须执行的动作。当你在本章前面学习组成GNU工具链的其他各种编译工具时,你已看到几个简单的Makefile规则。
下面是一个更复杂的Makefile文件,它可以用于编译迄今为止的所有示例代码。
 |
Makefile文件针对可能的目标定义了一系列的规则。其中包括实际编译三个示例(Hello、Goodbye和Trig)的规则,以及定义如何在发布他们的软件给其他开发者之前清理源代码的规则。一条规则是由一个命名标签后跟随一个冒号和一个依赖关系名单组成的。这个依赖关系名单必需首先得到满足,然后才能考虑结果是否成功。如果make通过规则本身不能自动确定如何去做,在该规则之后就需要跟随一些具体应该使用的命令。
GNU Make的规则可以定义的内容非常广泛,从琐碎的源文件依赖到复杂的层次依赖均可,但它们最终总是可以被细分为简单的命令序列。除了定义规则以外,make还支持定义变量、条件和许多其他你可能期望从一个普通编程语言中获得的特征。GNU Make还理解许多标准变量,如$CFLAGS(这个标记将被传递给C编译器)和$CC(默认设置为gcc)。
在上面的Makefile文件中,默认动作(all)试图通过使用针对每个示例程序的规则来编译这三个程序——Hello、Goodbye和Trig。因为hello规则没有定义任何依赖关系,所以make将自动假定它需要将源文件hello.c编译为可执行文件hello。对于goodbye规则来说,make在连接两个依赖文件到一个最终可执行程序之前首先需要自动编译这两个依赖文件。
Trig示例程序的编译过程与其他程序的编译过程稍有不同。在trig规则之后没有指定任何依赖关系,但在这条空规则的下一行给出了一个编译器命令。GNU Make将把它作为一个shell命令来执行,并替换放在括号中的变量扩展。因此,$(CC)将成为gcc,而$(CFLAGS)将扩展为在Makefile文件开头定义的标记内容。要注意的是,当给出这样一个明确的命令时,我们有必要同时包含CFLAGS和CC。
你可以通过阅读安装在本地工作站上的在线文档或通过访问自由软件基金会的网址来了解更多有关Make规则和如何使用GNU Make的信息。但更好的方式是下载一个大型的自由软件项目的源代码,通过阅读它所使用的Makefile文件,你将很快弄清楚GNU make可以使用的复杂规则集。
在John R. Levine所著的非常幽默的图书Linkers and Loaders(Morgan Kaufman,2000)中,你将找到更多有关ELF文件格式的设计和实现以及标准工具如GNU连接器操作的内容。
2.5 GNU调试器
GNU调试器(GDB)是Linux开发者的工具箱中功能最强大的工具之一。GDB不仅是一个数以千计的用户每天都在使用的灵活的工具,而且它也是世界上最普及的调试器之一。这在某种程度上也是因为有为数众多的发行商选择在他们的产品中使用GDB而不是自己从头开始重新实现它的功能。所以,不论你从哪里购买工具,它都很有可能在其内部提供某种形式的GDB。
作为一个独立的软件包,GDB通常作为现代Linux发行版中的任意一个开发工具的一部分安装到你的系统中。使用GDB非常简单,我们以前面的三角函数程序作为一个简单的示例,可以通过在gdb中运行应用程序来调试它,使用的命令如下所示(请确认程序在编译时使用了gcc的“-g”调试标记):
 |
 |
此时程序还没有运行,你可以使用run命令来运行它。在gdb中运行一个程序之前,你最好能在代码中至少插入一个断点。这样做之后,当程序运行到源代码特定的某一行时,GDB将暂停程序的运行以允许你执行任何有助于你调试的查询。人们习惯于在main函数的入口插入第一个程序断点,然后在程序中的其他位置插入其他断点。
在示例代码中插入一个断点,然后运行它,如下所示:
 |
GDB将在trig程序运行到main函数的第一条指令时暂停程序,在本例中,这条指令位于源文件trig.c的第17行。除了在程序运行到断点后GDB自动显示的对printf函数的调用以外,我们还可以使用list命令来显示main函数中的源代码。每一行代码可以使用step和next命令来单步执行——前者会在执行每一条机器指令之后暂停,后者的执行方式类似,但它不会进入外部函数的内部,而是把函数调用语句当作一条普通语句来执行。
我们使用next命令执行printf语句,并在用户通过命令行输入角度之后停止,如下所示:
 |
 |
在默认情况下,程序的输入和输出与GDB的命令输入共用同一个终端。你可以使用GDB的tty命令来重定向程序的输入/输出到一个特定的Linux终端。例如,在图形化桌面环境中,你可以在一个X终端窗口中调试应用程序,并将它的输入和输出传递到另一个终端窗口。你可以使用shell命令行中同名的tty命令来查找一个X终端的终端号。
最后,你可以使用continue命令(简写为c)让程序一直运行,直到它终止(或遇到另一个断点):
 |
 |
GDB的另一个常见用途是用于调试程序的核心转储(core dump)——当应用程序崩溃时包含应用程序当时状态的文件,它用来确定崩溃的具体情况,这和飞机失事后使用的飞机黑匣子记录器非常类似。每当应用程序犯了错误,如非法存取内存或访问NULL指针指向的内容时,Linux将强制终止程序的运行并自动生成这些核心文件。
你选择的Linux发行版在默认情况下可能并不会创建核心转储文件。在这种情况下,你可能需要修改系统设置来要求它这样做,具体细节请参考你的发行商的系统文档。
Linux内核本身会通过在目录/proc中的只读文件kcore的不断更新来显示其内部状态。你可以对这个伪核心转储使用gdb来获得你的Linux工作站的当前状态的一些有限的信息。例如,你可以查看从Linux内核的角度看到的当前时间,它是从系统启动开始计算的系统计时器滴答数,如下所示:
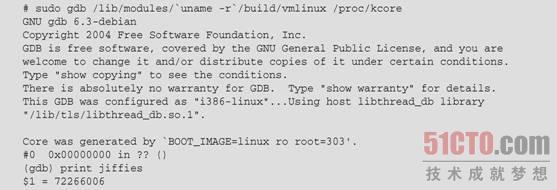 |
因为jiffies的值在调用GDB时已被缓存,所以,如果试图重新显示该值,将获得相同的结果——需要重启GDB来确认这个值已改变了。
这个GDB命令依赖于目录/lib/modules中的当前内核版本子目录下的一个符号连接(该符号连接指向的目录用于编译内核)并要求GDB使用文件/proc/kcore中输出的伪内核文件映像。如果你没有在你的工作站上编译过内核,那么由于在符号连接所指向的目录中不存在vmlinux文件,你将不能运行这个命令。在本书的后面你还将学习到更多有关编译和调试Linux内核的内容。
GDB可以使用的命令比在本章中简要介绍的这些命令多得多。事实上,要想完整地涵盖GDB包含的所有功能,需要一本比本书厚得多的图书来介绍。我们鼓励你使用GDB进行实验,在本书的其余部分,我们也会在需要的时候再次使用它。
2.6 Linux内核和GNU工具链
GNU工具链被世界上无数的软件项目所使用,但几乎没有哪个软件项目像Linux内核那样淋漓尽致地使用了这些工具所提供的功能。正如你将在本书后面看到的那样,Linux内核极度依赖于GCC中的许多语言扩展以及许多其他常用系统工具的GNU扩展。不依赖GNU工具链来编译Linux内核在理论上是可行的,但在实践中很少这样做。
2.6.1 内联汇编
底层Linux内核代码会经常使用GNU C编译器中的一个扩展以支持内联汇编代码。从字面上看,这就是汇编语言代码,它插入到构成大部分内核的普通C函数中。虽然内核的目的是为了尽可能地可移植——因此它大多是由平台独立的C语言代码所编写——但有些操作只能用机器特定的指令来执行。内联汇编有助于实现这一过程。
下面是一个简单的C函数示例,其中就包含了一些内联汇编语言代码:
 |
这个函数有两个参数——一个地址和一些数据。在__asm__属性标记之后的PowerPC汇编语言将传递给函数的数据存储在指定的内存地址中,最后以特殊的机器特定的指令(eieio)结束,该指令强制硬件提交写入某些硬件设备的值,而不论该值是什么。__volatile__标记告诉GCC不要试图优化这段示例代码,因为它必须按照它编写的顺序来执行。
这个示例代码需要一些机器特定的处理器寄存器在汇编语言代码执行之前存放data和address变量。请注意,示例代码中的r标记表明data和address变量将只能被内联汇编语言代码段读取而不能被它更新。如果内联汇编语言命令需要改变它的输入寄存器,我们就需要使用w标记使GCC知道这些寄存器将要被修改。
你并不需要关注本例中所使用的具体汇编语言,而应该留意内联汇编所使用的一般格式:
你将在Linux内核的源代码中找到更多关于内联汇编的例子。
2.6.2 属性标记
Linux内核非常依赖GCC的属性。这些属性是一些和源代码一起使用的特殊标记,它们向GNU C编译器提供额外的信息以告诉它应该如何特别地处理内核源代码。属性包括nonnull和noreturn,前者告诉编译器这个函数不能使用NULL参数,后者告诉编译器这个函数完全可以不返回。
下面是Linux内核中的一个属性定义的例子:
上面的代码定义了module_init函数,它被每一个Linux内核模块(LKM)所使用,当模块第一次被装载时,它用来声明将要运行的函数。在本例的众多参数中,alias属性用于为模块初始化函数设置一个别名#initfn。今后每当一个头文件需要提及这个函数时,它都可以使用宏#initfn来代替完整的函数名。
Linux内核函数经常会利用section属性,它用于指定某些函数必须被放置在Linux内核的二进制文件的特定段中。内核还会用到alignment属性,它强制对变量声明进行精确的内存对齐。出于对高性能的要求,Linux内核中的变量的内存对齐通常是非常严格的。这有助于确保有效地在主存中传输某些数据。
属性可以帮助各种代码分析工具(如Linus Torvald的sparse源代码检查器)来推测Linux内核中所使用的特定函数和变量的附加信息。例如,标记了nonnull属性标记的函数参数将被检查它是否曾经被传递了NULL值。
2.6.3 定制连接器脚本
Linux内核和其他底层软件非常依赖于连接器脚本来创建有着特定二进制映像布局的可执行文件。之所以这样做有很多重要的理由,其中一个理由是我们希望在内核二进制映像中将某些相关的内核特征分组到逻辑段中。例如,Linux内核中的某些函数有__init__或__initdata__标记。这些标记都被定义为GCC的属性,它们的作用是将这类函数分组到内核中的一个特殊段。
一旦Linux内核启动成功,它就不再需要有init之类的标记的代码和数据了,因此用于存储它们的内存也将被释放。这之所以能实现是因为这类代码和数据都被存储在内核的一个特殊段中,它可以作为一大块可回收的内存被释放。这些特殊段在最终内核二进制映像中的物理位置由专门的内核连接器脚本确定,它在其中包含了这样的考虑。
有时候,精确的二进制映像布局是由运行内核的目标机器的硬件决定的。许多现代微处理器期望在内核映像的精确偏移位置找到某些底层的操作系统函数。这包括硬件异常处理函数(用于响应某些同步或异步处理器事件的代码)以及许多用于其他用途的函数。由于Linux内核映像是在机器的物理内存的精确偏移位置被装载的,所以我们可以借助于连接器技巧来满足这一需求。
Linux内核针对每一个它要支持的体系结构使用一个特定的连接器脚本。请查看本地Linux内核源代码目录中arch/i386/kernel/vmlinux.lds文件的内容,你将看到如下的片段:
 |
这些条目执行各种不同的任务,详细的解释请看GNU的连接器文档。在本例中,它指定所有内核代码从内存的虚拟地址0xC000_0000开始,而且几个特定符号必须按8字节边界对齐。完整的连接器脚本是非常复杂的,因为许多平台对Linux内核的要求非常复杂的。
2.7 交叉编译
Linux上的大多数软件开发都发生在与最终运行该软件的机器的类型相同的机器上。一个工作在Intel IA32(x86)工作站上的开发者将为拥有同类型基于Intel工作站的顾客(或自由软件用户)编写应用程序。
但对于嵌入式Linux开发者来说,事情就不是这么容易了。他们必须为各种不同类型的机器开发软件,每一种机器可能是在一个完全不同的处理器架构上运行Linux。而且对于面向个人的设备如PDA和手机而言,由于它们没有提供足够的处理能力或存储空间,所以直接在它们之上进行软件开发是不可行的。相反,我们采用的方法是在更强大的Linux主机上对软件进行交叉编译。
交叉编译(或交叉建立)是这样一种过程,它在一种机器结构下编译的软件将在另一种完全不同的机器结构下执行。一个常见的例子是在基于Intel的工作站上为运行在基于ARM、PowerPC或MIPS的目标设备编译软件。幸运的是,GNU工具使得这一过程所面临的困难要比听起来小得多。
GNU工具链中的一般工具通常都是通过在命令行上调用命令(如gcc)来执行的。在使用交叉编译的情况下,这些工具将根据它编译的目标而命名。例如,要使用交叉工具链为PowerPC机器编译简单的Hello World程序,你可以运行如下所示的命令:
使用如下命令编译并测试这个代码:
$ powerpc-eabi-gcc -o hello hello.c |
请注意交叉编译的目标powerpc-eabi是如何成为特定工具名前缀的。虽然工具的准确名称在很大程度上取决于它所面对的特定目标设备,但类似的命名约定也适用于交叉工具链中的其他工具。许多嵌入式Linux厂商销售各种你可以使用的设备专用工具链,当然你也可以根据下一节中的示例建立自己的工具。
除了直接使用交叉工具链以外,你可能经常会发现自己需要编译那些大型的基于自动编译工具如GNU Autoconf的已有项目。在这种情况下,你需要告诉已有的configure脚本,你要为某一特定的目标交叉编译一些软件,你将发现表2-4中的选项标记很有用。
表2-4 交叉编译时的选项标记
2.8 建立GNU工具链
你无疑已经认识到GNU工具链是由许多单个的组件构成的,它们彼此独立开发但又必须协同工作以实现特定的目标。这些单个的GNU工具本身也必须在某个时候被从因特网上提供的源代码编译为可执行文件。这是一个非常费时的过程,Linux发行商已花了很多时间来解决它,并已为你的本地Linux工作站完成了这一任务,所以你就不需要再做一次了。
但也有时候现有的工具都不适合于手头的任务。有很多原因会导致出现这种情况,包括:
需要一个比发行商提供的工具更新的版本。
为一个特定的或不常见的目标交叉编译应用程序。
为单个工具修改特定的编译时选项。
在这些情况下,你需要自己从头开始获得并编译GNU工具链或为此付费购买需要的工具。从头开始编译一个工具链是一件非常困难和费时的过程,因为你需要针对不同的目标处理器为工具打上许多补丁,而且还要考虑到工具自身之间的相互依赖关系。为了建立一个工具链,你需要将下面列出的单个组件组合到一起:
GCC
binutils
GLIBC
GDB
为了建立一个能够编译一般用户程序的GCC,情况会变得更糟。因为你需要一个预编译的GNU C函数库,但为了获得一个这样的函数库,你需要先有一个编译器。为此,整个建立过程实际上被分成多个阶段,首先建立一个最小的GCC以便编译GLIBC(它本身还需要一份Linux内核头文件的拷贝),然后再重建一个能够编译有用程序的工具链。
顺便提一下,如果只是建立一个用于编译Linux内核或其他底层嵌入式应用程序的工具链,那就不需要用到GLIBC,因此整个建立过程会变得简单一些,但付出的代价是建立的工具链只能用于编译定制内核或为特定的嵌入式板编写一些特定的底层固件。如果这就是你所需要的,那么事情将变得容易一些。
幸运的是,近年来,工具链的建立过程已变得更加容易,这要感谢一些自动化脚本的出现,它们旨在帮助你为特定应用程序自动建立一个定制的工具链。迄今为止,最受欢迎的脚本是Dan Kegel的crosstool。许多爱好者和厂商都以它为基础来建立自己的定制工具链,并且它可以免费从网上获得。如果你也使用它,将省去很多的麻烦。
你可以通过Kegel的网站http://kegel.com/crosstool获得crosstool。它是一个压缩文件,你必须首先将它解包,解包产生的目录中还包括为每一个GNU工具链支持的CPU类型编写的演示脚本。你可以通过修改这些演示脚本来为你所需要的工具链创建一个合适的配置脚本。例如,你可以在基于Intel IA32(x86)的工作站上创建一个可以为PowerPC目标编译应用程序的交叉工具链。或者,你也可以用crosstool为与你的Linux工作站的结构相同的机器建立普通的工具链。
crosstool将从各自相应的项目网站下载单个工具链源代码的过程变得自动化,并自动为期望的目标组合打上必要的补丁。然后crosstool将按照正确的顺序编译工具链的各个部分。在结束时,你还可以选择运行标准的回归测试(它作为GNU工具链源代码的一部分发行)。
2.9 本章总结
全世界成千上万的用户、开发人员和厂商都非常依赖于GNU工具链中的每个工具。他们每天都在使用GNU工具为各种操作系统编译许多不同类型的应用程序。在Linux上,GCC及其相关的工具几乎被用于建立从Linux内核自身到最精致的图形化桌面环境的所有软件。
在本章中,我们介绍了GNU工具链中的每个工具——GCC、binutils、gdb等。我们还介绍了这些工具的一些高级的功能,以及它们在大型Linux软件开发项目中的实际应用。我们还特别关注了一些不常见的项目(如Linux内核)的需求,它依赖于GNU工具链所拥有的一些独特的特点。
使用GNU工具完成任务的一个关键优势是它的灵活性,但除了那些最高级的开发人员以外,对于大多数人来说,它们的功能总是显得非常神秘。当然,我们也可以通过图形化开发工具来完成本章所介绍的许多操作,但对这些工具有一个整体的了解还是很有必要的,因为有时候图形化工具可能会让你失望或它不能解决你手头上的任务。