用python实现一个redis的zset数据结构
用了redis也有2年多了,常常感叹于redis的优美和精悍,麻雀虽小五脏俱全。
最近手痒冒出用python在内存中实现一个zset数据结构的想法。
思路是这样的:
hash + sortedlist
其中hash用于使获取键值的复杂度变成O(1)
而用bisect模块二分法作用于sortedlist实现其它操作O(logN)
下面上代码。
#coding=utf-8
from bisect import bisect_left,bisect_right,insort
#定义节点
class SNode:
def __init__(self,key=None, score=float('-inf'),next=None):
self.key = key
self.score = score
def __lt__(self,other):
return self.score < getattr(other,'score',other)
def __gt__(self,other):#没定义__gt__的话会导致bisect_right出问题,即使已经定义了__lt__
return self.score > getattr(other,'score',other)
#定义数组,用bisect维护顺序
class Slist(object):
def __init__(self):
self.key2node = {}
self.card = 0
self.orderlist = []
def findpos(self, snode):
curpos = bisect_left(self.orderlist,snode)
while 1:
if self.orderlist[curpos].key==snode.key:
break
curpos += 1
return curpos
def insert(self,key,score):
if not isinstance(score,int):raise Exception('score must be integer')
snode = self.key2node.get(key)
if snode:
if score == snode.score:
return 0
del self.orderlist[self.findpos(snode)]
snode.score = score
else:
self.card += 1
snode = SNode(key=key,score=score)
self.key2node[key] = snode
insort(self.orderlist, snode)
return 1
def delete(self,key):
snode = self.key2node.get(key)
if not snode:
return 0
self.card -= 1
del self.orderlist[self.findpos(snode)]
del self.key2node[key]
del snode
return 1
def search(self,key):
return self.key2node.get(key)
class SortedSet:
def __init__(self):
self.slist = Slist()
def zadd(self, key, score):
return self.slist.insert(key, score)
def zrem(self, key):
return self.slist.delete(key)
def zrank(self, key):#score相同则按字典序
snode = self.slist.key2node.get(key)
if not snode:
return None
return self.slist.findpos(snode)
def zrevrank(self, key):
return self.zcard - 1 - self.zrank(key)
def zscore(self, key):
snode = self.slist.key2node.get(key)
return getattr(snode,'score',None)
def zcount(self, start, end):
ol = self.slist.orderlist
return bisect_left(ol,end+1) - bisect_right(ol,start-1)
@property
def zcard(self):
return self.slist.card
def zrange(self, start, end, withscores=False):#score相同则按字典序
nodes = self.slist.orderlist[start: end+1]
if not nodes:return []
if withscores:
return [(x.key, x.score) for x in nodes]
else:
return [x.key for x in nodes]
def zrevrange(self, start, end, withscores=False):
card = self.zcard
if end<0:
end = end + card
if start<0:
start = start + card
nodes = self.slist.orderlist[max(card-end-1, 0): max(card-start, 0)][::-1]
if not nodes:return []
if withscores:
return [(x.key, x.score) for x in nodes]
else:
return [x.key for x in nodes]
def zrangebyscore(self, start, end, withscores=False):
ol = self.slist.orderlist
nodes = ol[bisect_left(ol, start):bisect_right(ol, end)]
if not nodes:return []
if withscores:
return [(x.key, x.score) for x in nodes]
else:
return [x.key for x in nodes]
def zrevrangebyscore(self, end, start, withscores=False):
return self.zrangebyscore(start, end, withscores)[::-1]
def zincrby(self, key):
snode = self.slist.key2node.get(key)
if not snode:
return self.zadd(key, 1)
score = snode.score
self.zrem(key)
return self.zadd(key, score+1)
import contextlib
import time
timeobj = {}
class timetrace:
@contextlib.contextmanager
def mark(self,name):
t = time.time()
yield
timeobj[name] = time.time() - t
def stat(self):
print '---------benchmark(100000 requests)---------'
for k,v in timeobj.iteritems():
print '{} {}s'.format(k,v)
tt = timetrace()
if __name__ == '__main__':
s = SortedSet()
s.zadd('kzc',17)
s.zadd('a',1)
s.zadd('b',2)
s.zadd('c',2)
s.zadd('d',6)
s.zadd('hello',18)
s.zadd('world',18)
s.zincrby('kzc')
print 'kzc score',s.zscore('kzc')
print 'kzc rank',s.zrank('kzc')
print 'kzc revrank',s.zrevrank('kzc')
print 'zcount(1,20)',s.zcount(1,20)
print 'zrange(2,4,withscores=True)',s.zrange(2,4,withscores=True)
print 'zrangebyscore(1,5,withscores=True)',s.zrangebyscore(1,5,withscores=True)
print 'zrem("c")',s.zrem('c')
print 'zrangebyscore(1,5,withscores=True)',s.zrangebyscore(1,5,withscores=True)
print 'zcard',s.zcard
print 's.zadd("c",7)',s.zadd('c',7)
print 'zcard',s.zcard
print 'zrevrange all',s.zrevrange(0,-1,withscores=True)
#benchmark
import random
keys = [str(x) for x in range(0,100000)]
values = range(0,100000)
random.shuffle(keys)
with tt.mark('zadd'):
map(lambda x,y:s.zadd(x,y),keys,values)
with tt.mark('zscore'):
map(s.zscore,keys)
with tt.mark('zrank'):
map(s.zrank,keys)
tt.stat()
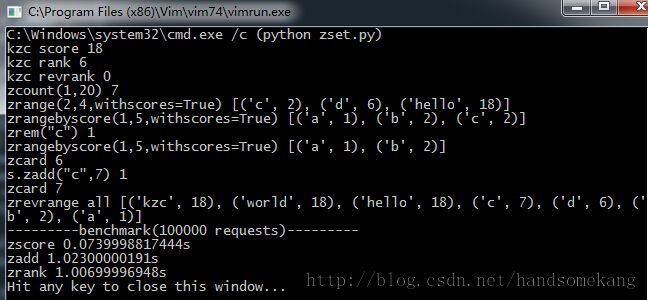
结果截图如下: