hive功能简介
Hive提供了类SQL语法的功能,可通过它来检索Hadoop存储数据,查询操作是基于MapReduce来完成的
2.通过where语句过滤查询条件
3.通过group by语句将查询结果进行分组
4.执行join查询操作
使用写有Join操作的查询语句时有一条原则:应该将条目少的表/子查询放在Join操作符的左边。原因是在Join操作的Reduce阶段,位于Join操作符左边的表的内容会被加载进内存,将条目少的表放在左边,可以有效减少发生OOM错误的几率。
inner join:
SELECT sales.*, things.* FROM sales JOIN things ON (sales.id = things.id);
outer join:
SELECT sales.*, things.* FROM sales LEFT OUTER JOIN things ON (sales.id = things.id);
SELECT sales.*, things.* FROM sales RIGHT OUTER JOIN things ON (sales.id = things.id);
SELECT sales.*, things.* FROM sales FULL OUTER JOIN things ON (sales.id = things.id);
semi join:等同于in函数
SELECT * FROM things LEFT SEMI JOIN sales ON (sales.id = things.id);
相当于sql语句:SELECT * FROM things WHERE things.id IN (SELECT id from sales);
map join:
Join操作在map阶段完成,不再需要reduce操作,因此map join不能结合RIGHT OUTER JOIN和FULL OUTER JOIN使用(需要reduce进行聚合)
SELECT /*+ MAPJOIN(things) */ sales.*, things.* FROM sales JOIN things ON (sales.id = things.id);
*前提:在join字段,join左边的记录集合(sales)是join右边(things)的子集*,例如:
sales things
1 1
2 2
3 3
4
...
5.管理数据库表格(create,drop,alter)
6.将查询结果保存到其他Table
通过insert语句:
INSERT OVERWRITE TABLE target
PARTITION (dt='2010-01-01')
SELECT col1, col2
FROM source;
注意:和关系数据库不同,insert操作不是追加记录,而是将新的记录覆盖掉以前的记录,因此OVERWRITE关键字是必须的
通过CTAS语句:
CREATE TABLE target
AS
SELECT col1, col2
FROM source;
7.将查询结果保存到HDFS
INSERT OVERWRITE DIRECTORY '/path' SELECT...
8.将查询结果保存到本地目录
INSERT OVERWRITE LOCAL DIRECTORY 'path' SELECT...
9.自定义MapReduce脚本用于查询
使用Hive需注意:
查询出的数据可能会有延迟
不能对数据执行更新和删除操作
Hive is not designed for online transition processing and does not offer real-time queries and row level
updates.it is best used for batch jobs over large sets of immutable data
DataBase、Tables:概念同关系数据库
其中Table又分为managed table和external table
删除external table的时候,只会删除表格的元数据信息,而不会删除表格的数据
删除managed table的时候,元数据和数据都会删除
Partitions:
当表格数据量较大时,可对表格进行分区处理(Partition),便于局部数据的查询操作,如按时间分区、按地域分区等,将具有相同性质的数据存储到同一磁盘块上,从而加快查询效率。
Buckets:
Table所存储的数据进行分区(Partition)之后,每个Partition还可划分成更细的粒度以水平切片的方式进行存储,被划分后的数据单元称为Bucket或Cluster
bucket多用于提高map-join的效率
a mapper working on a bucket of the left table only needs to load the corresponding buckets of the right table to perform the join
(1)、定义表格:
CREATE TABLE page_view(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
friends ARRAY<BIGINT>, properties MAP<STRING, STRING>, #1
ip STRING COMMENT 'IP Address of the User') #2
COMMENT 'This is the page view table'
PARTITIONED BY(dt STRING, country STRING) #3
CLUSTERED BY(userid) SORTED BY(viewTime) INTO 32 BUCKETS #4
ROW FORMAT DELIMITED #5
FIELDS TERMINATED BY '1'
COLLECTION ITEMS TERMINATED BY '2'
MAP KEYS TERMINATED BY '3'
STORED AS SEQUENCEFILE; #6
注释:
1.Hive的字段类型包括私有类型(Primitive Type)和复杂类型(Complex Type)
其中,私有类型包括:TINYINT、SMALLINT、INT、BIGINT、BOOLEAN、FLOAT、DOUBLE和STRING
复杂类型包括:Structs、Maps和Arrays,通常为私有类型的集合
2.通过COMMENT关键字为表格和字段添加注释
3.通过PARTITIONED BY关键字为表格分区
4.通过CLUSTERED BY关键字将PATITION划分成BUCKET
5.定义每条记录的存储格式,包括:
字段之间如何分隔;
集合字段中的元素如何分隔;
Map的key值如何分隔
6.指定存储格式为Hadoop的SequenceFile
(2)查看表结构
DESCRIBE tablename;
(3)修改表格
为表格添加字段
ALTER TABLE pokes ADD COLUMNS (new_col INT);
(4)删除表格
DROP TABLE tablename;
DML
(1)、导入数据
导入操作,只是将文件复制到对应的表格目录中,并不会对文档的schema进行校验
从HDFS导入
LOAD DATA INPATH 'data.txt' INTO TABLE page_view PARTITION(date='2008-06-08', country='US')
从本地导入,并覆盖原数据
LOAD DATA LOCAL INPATH 'data.txt' OVERWRITE INTO TABLE page_view PARTITION(date='2008-06-08', country='US')
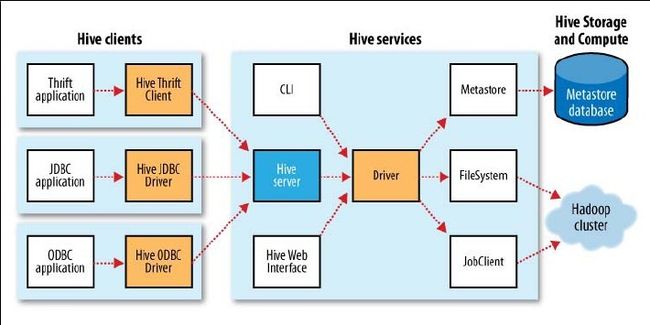
hiveserver
hiveserver启动方式:hive --service hiveserver
HiveServer支持多种连接方式:Thrift、JDBC、ODBC
metastore
metastore用来存储hive的元数据信息(表格、数据库定义等),默认情况下是和hive绑定的,部署在同一个JVM中,将元数据存储到Derby中
这种方式不好的一点是没有办法为一个Hive开启多个实例(Derby在多个服务实例之间没有办法共享)
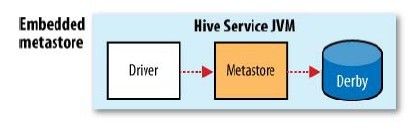
Hive提供了增强配置,可将数据库替换成MySql等关系数据库,将存储数据独立出来在多个服务实例之间共享
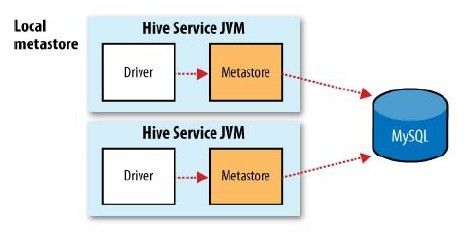
甚至还可以将metastore Service也独立出来,部署到其他JVM中去,在通过远程调用的方式去访问

metastore的常用配置:
hive.metastore.warehouse.dir 存储表格数据的目录
hive.metastore.local 使用内嵌的metastore服务(默认为true)
hive.metastore.uris 如果不使用内嵌的metastore服务,需指定远端服务的uri
javax.jdo.option.ConnectionURL 所使用数据库的url
javax.jdo.option.ConnectionDriverName 数据库驱动类
javax.jdo.option.ConnectionUserName 连接用户名
javax.jdo.option.ConnectionPassword 连接密码
CREATE TABLE ...
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
默认为纯文本文件TEXTFILE
如果存储的数据不是纯文本,而包含二进制的数据,可用SequenceFile和RCFile
RCFile:基于列存储,类似于HBase,查询Table时,如果要检索的数据不是整条记录,而是具体的column,RCFile较比SequenceFile高效一些,只需遍历指定column对应的数据文件即可
使用RCFile,创建Table时使用如下语法:
CREATE TABLE ...
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe'
STORED AS RCFILE;
除此之外,Hive还可通过正则表达式的方式指定输入数据源的格式:
CREATE TABLE stations (usaf STRING, wban STRING, name STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "(\\d{6}) (\\d{5}) (.{29}) .*"
);
参考资料:
http://www.alidata.org/archives/595
https://cwiki.apache.org/confluence/display/Hive/Home
hadoop权威指南
Hive功能
1.通过select语句查询指定column的数据2.通过where语句过滤查询条件
3.通过group by语句将查询结果进行分组
4.执行join查询操作
使用写有Join操作的查询语句时有一条原则:应该将条目少的表/子查询放在Join操作符的左边。原因是在Join操作的Reduce阶段,位于Join操作符左边的表的内容会被加载进内存,将条目少的表放在左边,可以有效减少发生OOM错误的几率。
inner join:
SELECT sales.*, things.* FROM sales JOIN things ON (sales.id = things.id);
outer join:
SELECT sales.*, things.* FROM sales LEFT OUTER JOIN things ON (sales.id = things.id);
SELECT sales.*, things.* FROM sales RIGHT OUTER JOIN things ON (sales.id = things.id);
SELECT sales.*, things.* FROM sales FULL OUTER JOIN things ON (sales.id = things.id);
semi join:等同于in函数
SELECT * FROM things LEFT SEMI JOIN sales ON (sales.id = things.id);
相当于sql语句:SELECT * FROM things WHERE things.id IN (SELECT id from sales);
map join:
Join操作在map阶段完成,不再需要reduce操作,因此map join不能结合RIGHT OUTER JOIN和FULL OUTER JOIN使用(需要reduce进行聚合)
SELECT /*+ MAPJOIN(things) */ sales.*, things.* FROM sales JOIN things ON (sales.id = things.id);
*前提:在join字段,join左边的记录集合(sales)是join右边(things)的子集*,例如:
sales things
1 1
2 2
3 3
4
...
5.管理数据库表格(create,drop,alter)
6.将查询结果保存到其他Table
通过insert语句:
INSERT OVERWRITE TABLE target
PARTITION (dt='2010-01-01')
SELECT col1, col2
FROM source;
注意:和关系数据库不同,insert操作不是追加记录,而是将新的记录覆盖掉以前的记录,因此OVERWRITE关键字是必须的
通过CTAS语句:
CREATE TABLE target
AS
SELECT col1, col2
FROM source;
7.将查询结果保存到HDFS
INSERT OVERWRITE DIRECTORY '/path' SELECT...
8.将查询结果保存到本地目录
INSERT OVERWRITE LOCAL DIRECTORY 'path' SELECT...
9.自定义MapReduce脚本用于查询
使用Hive需注意:
查询出的数据可能会有延迟
不能对数据执行更新和删除操作
Hive is not designed for online transition processing and does not offer real-time queries and row level
updates.it is best used for batch jobs over large sets of immutable data
Hive数据模型
按照粒度由粗到细,Hive数据可划分成如下几个单元DataBase、Tables:概念同关系数据库
其中Table又分为managed table和external table
删除external table的时候,只会删除表格的元数据信息,而不会删除表格的数据
删除managed table的时候,元数据和数据都会删除
Partitions:
当表格数据量较大时,可对表格进行分区处理(Partition),便于局部数据的查询操作,如按时间分区、按地域分区等,将具有相同性质的数据存储到同一磁盘块上,从而加快查询效率。
Buckets:
Table所存储的数据进行分区(Partition)之后,每个Partition还可划分成更细的粒度以水平切片的方式进行存储,被划分后的数据单元称为Bucket或Cluster
bucket多用于提高map-join的效率
a mapper working on a bucket of the left table only needs to load the corresponding buckets of the right table to perform the join
Hive语法
DDL(1)、定义表格:
CREATE TABLE page_view(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
friends ARRAY<BIGINT>, properties MAP<STRING, STRING>, #1
ip STRING COMMENT 'IP Address of the User') #2
COMMENT 'This is the page view table'
PARTITIONED BY(dt STRING, country STRING) #3
CLUSTERED BY(userid) SORTED BY(viewTime) INTO 32 BUCKETS #4
ROW FORMAT DELIMITED #5
FIELDS TERMINATED BY '1'
COLLECTION ITEMS TERMINATED BY '2'
MAP KEYS TERMINATED BY '3'
STORED AS SEQUENCEFILE; #6
注释:
1.Hive的字段类型包括私有类型(Primitive Type)和复杂类型(Complex Type)
其中,私有类型包括:TINYINT、SMALLINT、INT、BIGINT、BOOLEAN、FLOAT、DOUBLE和STRING
复杂类型包括:Structs、Maps和Arrays,通常为私有类型的集合
2.通过COMMENT关键字为表格和字段添加注释
3.通过PARTITIONED BY关键字为表格分区
4.通过CLUSTERED BY关键字将PATITION划分成BUCKET
5.定义每条记录的存储格式,包括:
字段之间如何分隔;
集合字段中的元素如何分隔;
Map的key值如何分隔
6.指定存储格式为Hadoop的SequenceFile
(2)查看表结构
DESCRIBE tablename;
(3)修改表格
为表格添加字段
ALTER TABLE pokes ADD COLUMNS (new_col INT);
(4)删除表格
DROP TABLE tablename;
DML
(1)、导入数据
导入操作,只是将文件复制到对应的表格目录中,并不会对文档的schema进行校验
从HDFS导入
LOAD DATA INPATH 'data.txt' INTO TABLE page_view PARTITION(date='2008-06-08', country='US')
从本地导入,并覆盖原数据
LOAD DATA LOCAL INPATH 'data.txt' OVERWRITE INTO TABLE page_view PARTITION(date='2008-06-08', country='US')
Hive体系结构
hiveserver
hiveserver启动方式:hive --service hiveserver
HiveServer支持多种连接方式:Thrift、JDBC、ODBC
metastore
metastore用来存储hive的元数据信息(表格、数据库定义等),默认情况下是和hive绑定的,部署在同一个JVM中,将元数据存储到Derby中
这种方式不好的一点是没有办法为一个Hive开启多个实例(Derby在多个服务实例之间没有办法共享)
Hive提供了增强配置,可将数据库替换成MySql等关系数据库,将存储数据独立出来在多个服务实例之间共享
甚至还可以将metastore Service也独立出来,部署到其他JVM中去,在通过远程调用的方式去访问
metastore的常用配置:
hive.metastore.warehouse.dir 存储表格数据的目录
hive.metastore.local 使用内嵌的metastore服务(默认为true)
hive.metastore.uris 如果不使用内嵌的metastore服务,需指定远端服务的uri
javax.jdo.option.ConnectionURL 所使用数据库的url
javax.jdo.option.ConnectionDriverName 数据库驱动类
javax.jdo.option.ConnectionUserName 连接用户名
javax.jdo.option.ConnectionPassword 连接密码
hive数据存储格式
定义表格时如不指定Row Format和Stored As从句,hive采用如下默认配置:CREATE TABLE ...
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
默认为纯文本文件TEXTFILE
如果存储的数据不是纯文本,而包含二进制的数据,可用SequenceFile和RCFile
RCFile:基于列存储,类似于HBase,查询Table时,如果要检索的数据不是整条记录,而是具体的column,RCFile较比SequenceFile高效一些,只需遍历指定column对应的数据文件即可
使用RCFile,创建Table时使用如下语法:
CREATE TABLE ...
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe'
STORED AS RCFILE;
除此之外,Hive还可通过正则表达式的方式指定输入数据源的格式:
CREATE TABLE stations (usaf STRING, wban STRING, name STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "(\\d{6}) (\\d{5}) (.{29}) .*"
);
参考资料:
http://www.alidata.org/archives/595
https://cwiki.apache.org/confluence/display/Hive/Home
hadoop权威指南