在Tivoli集群域中实现DB2高可用性灾难恢复
简介和概述
在当今世界上,许多企业为来自世界各地的客户提供一周 7 天每天 24 小时的服务,他们希望自己的计算系统 100% 的可靠。DB2 for Linux, UNIX, and Windows 在数据库领域中非常先进,可以提供工业级的可靠性。在 DB2 UDB V8.2 中,DB2 引入了两个新特性 —— 灾难恢复(HADR)和自动客户机重路由功能,它们为客户提供了更多实现高可用性的选项。通过将数据库的工作负载复制到单独的站点上,这些特性使服务在发 生本地硬件故障或灾难性站点故障时不会中断。这些特性是 DB2 UDB Enterprise Server Edition 或 DB2 Enteprise 9 标准包附带的功能。
在 20 世纪 90 年代中期,HADR 就在 Informix Dynamic Server(IDS)中出现了。IBM 收购了 Informix 之后,这个特性进入了 DB2 8.2。理解 HADR 最容易的方法是设想两台服务器,它们在数据库级保持相互同步。这两台服务器中的主服务器与终端用户的应用程序交互并接收事务,而备用服务器将直接来自主服 务器的日志缓冲区的事务应用于本身,从而与主服务器保持同步。如果主服务器失败,备用服务器就非常快速地接管工作负载(在大多数情况下,转换时间少于 30 秒)。它还支持数据库或操作系统软件的滚动升级,这样就能够在不显著影响生产系统的情况下应用修复。
Tivoli System Automation(TSA)for Multiplatforms 的设计目的是,通过基于策略的自修复特性,为关键的业务应用程序和中间件提供高可用性,这种特性可以轻松地针对自己的应用程序环境进行调整。它为许多 IBM® 和非 IBM 中间件和应用程序(比如 DB2、WebSphere®、Apache 和 mySAP Business Suite)提供了即插即用的自动策略模块。通过使用 TSA for Multiplatforms,可以让一个运营和自动化团队同时负责 z/OS®、Linux 和 AIX® 应用程序,这可以大大简化对问题的判断和分析。
图 1. TSA 集群域拓扑结构中的 DB2 HADR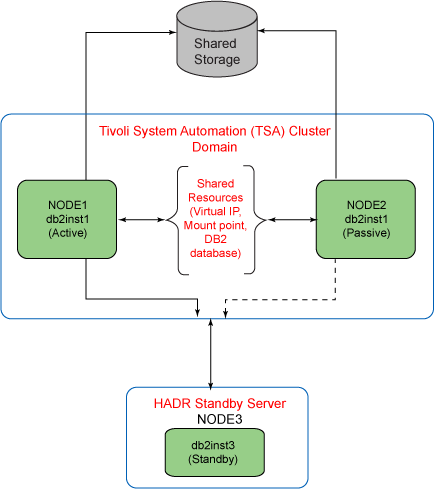
软件配置
下面是为本文设置环境所用的软件配置:
- 操作系统: Red Hat Linux Enterprise Server 2.4.21-27 GNU/Linux
- DB2: DB2 UDB Enterprise Server Edition(ESE) Version 8.1.0.96,Fixpak 10
- TSA: TSA 1.2.0 FP0005 Linux
硬件配置
下面是为本文设置环境所用的硬件配置。
集群域中有两台 IBM eServer pSeries® 690 服务器机器,它们都具有以下配置:
- 处理器:Intel Xeon MP 4 CPU 2.70 GHz
- 内存:8 GB
- 网络适配器:两个 Intel PRO/1000 Ethernet Adapters
灾难恢复站点上的一台 IBM eServer pSeries 690 服务器机器具有以下配置:
- 处理器:Intel Xeon CPU 3.0 GHz
- 内存:8 GB
- 网络适配器:两个 Intel PRO/1000 Ethernet Adapters
外部共享存储
在集群端有 4 个 IBM FastT600 Fiber Channel Disks,在灾难恢复站点上有 4 个 IBM DS4300 Fiber Channel Disks。
安装和配置说明
下面一节介绍一个 3 节点的拓扑结构,如 图 1 所示。在这个示例中,有一个主动 - 被动式的 TSA 集群域,这个域由 2 个节点组成(Node1 和 Node2),它们共享一个存储,其中包含实际的 DB2 数据库文件和软件。这个拓扑结构中的第三个节点(Node3)由远程位置上的灾难恢复站点组成,它托管前面提到的主数据库的备用数据库。TSA 集群域和备用服务器通过专用线路链接在一起。这个 HADR 设置的主数据库名和备用数据库名是 jsbmain。
NODE1:主动 - 被动式的 TSA 集群域设置的机器之一。在当前的设置中,这个节点是主动节点,并拥有集群的资源。
NODE2:TSA 集群域设置的第二台机器。在当前的设置中,这个节点是被动节点,它作为集群的备用节点。
NODE3:这台机器是用于 DB2 故障恢复的 HADR 备用服务器,它不属于 TSA 集群域设置。
下面详细描述在 TSA 集群域中成功配置 DB2 HADR 的步骤。这个设置假设 TSA 集群域已经正确地设置好了。关于如何设置基本 TSA 集群域以及相关命令的更多信息,请参考 附录 A。
步骤 1:基本网络设置
|
步骤 2:RSH 设置
注意:这个设置中使用的许多 TSA 命令要求在所有三个节点上设置 RSH。RSH 允许用户从一个节点上发出在另一个远程节点上执行的命令。关于在 Red Hat Linux 上设置 RSH 的更多信息,请参考本文的 参考资料 一节。
|
步骤 3:TSA 设置
关于基本的 2 节点 TSA 集群域设置,请参考 附录 A。另外,在附录 A 中还有关于相关 TSA 命令的更多信息。步骤 4:HADR 设置
|
从命令行处理程序(CLP)发出以下命令:
在主数据库服务器(Node1)上:
|
存储主服务器的备份的目录(/ jsbmain/jsbbak)应该可以从备用服务器(Node3)访问,或者将它复制到备用服务器上的本地驱动器,这样恢复过程才能完成它。
注意:建议将备份文件复制到备用服务器上的本地驱动器,从而进行本地恢复,这是因为远程恢复要花更多的时间,因为恢复缓冲区必须通过网络传送。
在备用服务器(Node3)上:
|
步骤 5:为自动客户机重路由配置数据库
在主服务器(Node1)上,从 db2 CLP 执行以下命令,从而启用 HADR 的自动客户机重路由特性:
|
|
步骤 6:更新 HADR 配置参数
在集群的主动节点(在这个示例中是 Node1)的数据库上执行以下命令,让这个数据库成为 HADR 设置的主数据库:
|
在备用服务器(Node3)上执行以下命令,让这个数据库成为 HADR 设置的备用数据库:
|
确保 TSA 域中的两个服务器 和 备用服务器都为 DB2 通信启用了 TCPIP 协议。在 TSA 域的两个服务器以及备用服务器上,执行 db2set DB2COMM=TCPIP 命令。
步骤 7:启动 HADR
|
步骤 8:检查 HADR 设置
现在,已经完成了 HADR 设置,就应该检查它是否能够正常工作。在主服务器(Node1)上执行以下命令:
db2 GET SNAPSHOT FOR DB ON jsbmain
输出应该像下面这样:
|
在备用服务器(Node3)上执行以下命令:
db2 GET SNAPSHOT FOR DB ON jsbmain
备用服务器中的输出应该像下面这样:
|
步骤 9:测试 HADR 的故障恢复
设置过程的最后一步是测试 HADR 的故障恢复功能。执行以下步骤:
|
现在,已经在 TSA 集群上设置了 DB2 HADR!!
附录
设置 2 节点 TSA 集群域所用的命令
使用以下命令设置 2 节点 TSA 集群域:
|
对这些命令的详细描述,请参考以下手册,这些手册都可以在 IBM TSA CD 上找到:
IBM Reliable Scalable Cluster Technology for Linux, Administration Guide, SA22-7892
IBM Reliable Scalable Cluster Technology for Linux, Technical Reference, SA22-7893
IBM Reliable Scalable Cluster Technology for AIX 5L: Administration Guide, SA22-7889
IBM Reliable Scalable Cluster Technology for AIX 5L: Technical Reference, SA22-7890
定义和管理集群
下面的场景展示如何创建集群、在集群中添加节点以及检查 IBM TSA 守护进程(IBM.RecoveryRM)的状态。
创建 2 节点的 TSA 集群域
为了创建这个集群,需要执行以下步骤:
1. 作为 root 在集群中的每个节点上登录。
2. 在每个节点上设置环境变量 CT_MANAGEMENT_SCOPE=2:
|
3. 在所有节点上发出 preprpnode 命令,从而使集群节点能够相互通信。
|
4. 现在,可以创建名为 “SA_Domain” 的集群,它在 Node1 和 Node2 上运行。可以从任何节点发出以下命令:
|
注意: 在使用 mkrpdomain 命令创建 RSCT 对等域(集群)时,对等域名使用的字符只限于以下的 ASCII 字符:A-Z、a-z、0-9、.(点号)和 _(下划线)。
5. 要查看 SA_Domain 的状态,发出 lsrpdomain 命令:
|
集群已经定义了,但是处于离线状态。
6.发出 startrpdomain 命令,让集群在线:
|
当再次运行 lsrpdomain 命令时,会看到集群仍然处于启动过程中,OpState 是
Pending Online。
|
注意:
1. 可能会收到下面这样的错误消息:
“2632-044 the domain cannot be created due to the following errors that were detected while harvesting information from the target nodes:
node1: 2632-068 this node has the same internal identifier as node2 and cannot be included in the domain definition.”
如果克隆了 Linux 映像,常常会发生这个错误。集群的配置出现了错误,应该重新设置整个配置。为了解决这样的问题,可以在错误消息中指出的节点上,运行 /usr/sbin/rsct/install/bin/recfgct 命令来重新设置节点 ID。
然后从 preprpnode 命令开始继续设置。
2. 还可能会收到下面这样的错误消息:
“2632-044 The domain cannot be created due to the following errors that were detected while harvesting information from the target nodes:
node1: 2610-418 Permission is denied to access the resources or resource class specified in this command.”
为了解决这个问题,应该检查主机名解析。在所有节点上的本地 /etc/hosts 文件中,确保每个集群节点的所有条目和名称服务器条目是相同的。
在现有的集群中添加节点
在创建 2 节点集群之后,可以按照以下方法在 SA_Domain 中添加第三个节点:1. 作为根用户发出 lsrpdomain 命令,查看集群是否在线:
|
2. 发出 lsrpnode 命令,查看哪些节点在线:
|
3. 作为根用户发出以下的 preprpnode 命令,让现有节点和新节点能够相互通信。
作为根用户登录 Node3 并输入:
|
作为根用户登录 Node2 并输入:
|
作为根用户登录 Node1 并输入:
|
确保在所有节点上执行 preprpnode 命令。强烈建议这样做。
4. 为了将 Node3 添加到集群定义中,作为根用户在 Node1 或 Node2(这两个节点应该已经在集群中在线)上发出 addrpnode 命令:
|
5. 作为根用户,从一个在线节点启动 Node3:
|
经过短暂的延迟之后,Node3 应该也在线了。