YARN安装配置初体验
本安装在开发实验环境中部署,只涉及到全局资源管理调度系统YARN的安装,HDFS还是第一代,没有部署HDFS Federation和HDFS HA,后续会加上。
OS: CentOS Linux release 6.0 (Final) x86_64
部署机器:
dev80.hadoop 192.168.7.80
dev81.hadoop 192.168.7.81
dev82.hadoop 192.168.7.82
dev83.hadoop 192.168.7.83
dev80主要作为ResourceManager, Namenode,SecondaryNamenode,slave节点(起datanode和nodemanager)包括 dev80,dev81,dev82,dev83
首先需要安装jdk,并保证和各个slave节点ssh打通。
从hadoop官网上下载2.0.5 alpha版本(目前最新的打包版本,beta版本已经从trunk上拉出了分支,不过需要自己build)
wget http://apache.fayea.com/apache-mirror/hadoop/common/hadoop-2.0.5-alpha/hadoop-2.0.5-alpha.tar.gz tar xzvf hadoop-2.0.5-alpha.tar.gz
解压开来后发现整个目录和hadoop 1.0发生很大变化,和linux根目录结构很相似,客户端的启动命令都放到bin下面,而管理员服务端启动命令都在sbin(super bin)下面,配置文件统一放在了etc/hadoop下,在原有基础上多了一个yarn-site.xml和yarn-env.sh,启动yarn的话可以用sbin/yarn-daemon.sh和sbin/yarn-daemons.sh(启动多个slave上的service)
drwxr-xr-x 2 hadoop hadoop 4096 Aug 16 18:18 bin drwxr-xr-x 3 hadoop hadoop 4096 Aug 14 10:27 etc drwxr-xr-x 2 hadoop hadoop 4096 Aug 14 10:27 include drwxr-xr-x 3 hadoop hadoop 4096 Aug 14 10:27 lib drwxr-xr-x 2 hadoop hadoop 4096 Aug 16 15:58 libexec drwxrwxr-x 3 hadoop hadoop 4096 Aug 14 18:15 logs drwxr-xr-x 2 hadoop hadoop 4096 Aug 16 18:25 sbin drwxr-xr-x 4 hadoop hadoop 4096 Aug 14 10:27 share
配置
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.0.5-alpha 加入/etc/profile文件中,这样启动的时候就会加载到系统环境变量中
hadoop-env.sh中设置JAVA HOME和ssh参数
export JAVA_HOME=/usr/local/jdk export HADOOP_SSH_OPTS="-p 58422"slaves文件加入如下节点:
dev80.hadoop dev81.hadoop dev82.hadoop dev83.hadoopcore-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://dev80.hadoop:8020</value>
<final>true</final>
</property>
</configuration>hdfs-site.xml中配置namenode存放editlog和fsimage的目录、和datanode存放block storage的目录
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/yarn/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/yarn/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>yarn-site.xml,yarn中shuffle部分被独立成一个service,需要在nodemanager启动的时候作为auxiliary service一起启动,这样可以自定义第三方的shuffle provider,和
ShuffleConsumer,比如可以替换现阶段的HTTP Shuffle
为RDMA Shuffle,对于中间结果merge可以采用更合适的策略来得到更好的性能提升
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.address</name>
<value>dev80.hadoop:9080</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>dev80.hadoop:9081</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>dev80.hadoop:9082</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce.shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>mapred-site.xml中需要配置mapreduce.framework.name为yarn,这样mr job会被提交到ResourceManager
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>将上述conf文件rsync到各个slave节点上
启动Service
先启动HDFS
bin/hdfs namenode -format
这条命令执行后/data/yarn/name下面就被formatted了
启动namenode:
sbin/hadoop-daemon.sh start namenode
启动datanode
sbin/hadoop-daemons.sh start datanode (注意这边是hadoop-daemons.sh,他会调用salves.sh,读取slaves文件ssh到各个slave节点上启动service)
至此namenode和datanode启动完毕
可以通过http://192.168.7.80:50070 查看hdfs页面
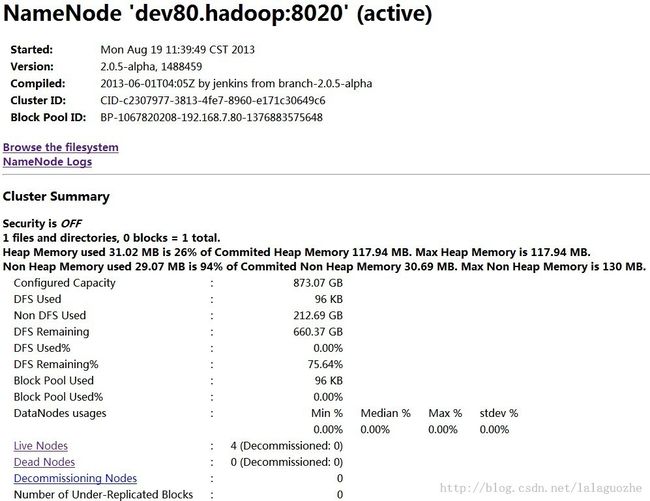
启动ResourceManager
sbin/yarn-daemon.sh start resourcemanager
启动NodeManager
sbin/yarn-daemons.sh start nodemanager
检查YARN的页面http://192.168.7.80:8088/cluster
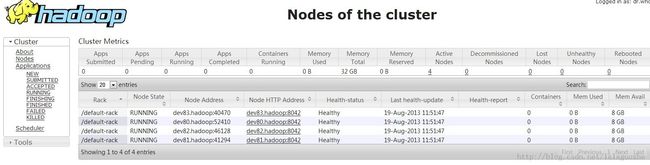
启动history server
sbin/mr-jobhistory-daemon.sh start historyserver
查看页面http://192.168.7.80:19888

跑一个简单的例子
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.0.5-alpha.jar pi 30 30
Number of Maps = 30
Samples per Map = 30
13/08/19 12:03:50 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Wrote input for Map #5
Wrote input for Map #6
Wrote input for Map #7
Wrote input for Map #8
Wrote input for Map #9
Wrote input for Map #10
Wrote input for Map #11
Wrote input for Map #12
Wrote input for Map #13
Wrote input for Map #14
Wrote input for Map #15
Wrote input for Map #16
Wrote input for Map #17
Wrote input for Map #18
Wrote input for Map #19
Wrote input for Map #20
Wrote input for Map #21
Wrote input for Map #22
Wrote input for Map #23
Wrote input for Map #24
Wrote input for Map #25
Wrote input for Map #26
Wrote input for Map #27
Wrote input for Map #28
Wrote input for Map #29
Starting Job
13/08/19 12:03:52 INFO service.AbstractService: Service:org.apache.hadoop.yarn.client.YarnClientImpl is inited.
13/08/19 12:03:52 INFO service.AbstractService: Service:org.apache.hadoop.yarn.client.YarnClientImpl is started.
13/08/19 12:03:53 INFO input.FileInputFormat: Total input paths to process : 30
13/08/19 12:03:53 INFO mapreduce.JobSubmitter: number of splits:30
13/08/19 12:03:53 WARN conf.Configuration: mapred.jar is deprecated. Instead, use mapreduce.job.jar
13/08/19 12:03:53 WARN conf.Configuration: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative
13/08/19 12:03:53 WARN conf.Configuration: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
13/08/19 12:03:53 WARN conf.Configuration: mapred.output.value.class is deprecated. Instead, use mapreduce.job.output.value.class
13/08/19 12:03:53 WARN conf.Configuration: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
13/08/19 12:03:53 WARN conf.Configuration: mapreduce.map.class is deprecated. Instead, use mapreduce.job.map.class
13/08/19 12:03:53 WARN conf.Configuration: mapred.job.name is deprecated. Instead, use mapreduce.job.name
13/08/19 12:03:53 WARN conf.Configuration: mapreduce.reduce.class is deprecated. Instead, use mapreduce.job.reduce.class
13/08/19 12:03:53 WARN conf.Configuration: mapreduce.inputformat.class is deprecated. Instead, use mapreduce.job.inputformat.class
13/08/19 12:03:53 WARN conf.Configuration: mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir
13/08/19 12:03:53 WARN conf.Configuration: mapred.output.dir is deprecated. Instead, use mapreduce.output.fileoutputformat.outputdir
13/08/19 12:03:53 WARN conf.Configuration: mapreduce.outputformat.class is deprecated. Instead, use mapreduce.job.outputformat.class
13/08/19 12:03:53 WARN conf.Configuration: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
13/08/19 12:03:53 WARN conf.Configuration: mapred.output.key.class is deprecated. Instead, use mapreduce.job.output.key.class
13/08/19 12:03:53 WARN conf.Configuration: mapred.working.dir is deprecated. Instead, use mapreduce.job.working.dir
13/08/19 12:03:53 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1376884226092_0001
13/08/19 12:03:53 INFO client.YarnClientImpl: Submitted application application_1376884226092_0001 to ResourceManager at dev80.hadoop/192.168.7.80:9080
13/08/19 12:03:53 INFO mapreduce.Job: The url to track the job: http://dev80.hadoop:8088/proxy/application_1376884226092_0001/
13/08/19 12:03:53 INFO mapreduce.Job: Running job: job_1376884226092_0001
13/08/19 12:04:00 INFO mapreduce.Job: Job job_1376884226092_0001 running in uber mode : false
13/08/19 12:04:00 INFO mapreduce.Job: map 0% reduce 0%
13/08/19 12:04:10 INFO mapreduce.Job: map 3% reduce 0%
13/08/19 12:04:11 INFO mapreduce.Job: map 23% reduce 0%
13/08/19 12:04:13 INFO mapreduce.Job: map 27% reduce 0%
13/08/19 12:04:14 INFO mapreduce.Job: map 43% reduce 0%
13/08/19 12:04:15 INFO mapreduce.Job: map 73% reduce 0%
13/08/19 12:04:16 INFO mapreduce.Job: map 100% reduce 0%
13/08/19 12:04:17 INFO mapreduce.Job: map 100% reduce 100%
13/08/19 12:04:17 INFO mapreduce.Job: Job job_1376884226092_0001 completed successfully
13/08/19 12:04:17 INFO mapreduce.Job: Counters: 44
File System Counters
FILE: Number of bytes read=666
FILE: Number of bytes written=2258578
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=8060
HDFS: Number of bytes written=215
HDFS: Number of read operations=123
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=30
Launched reduce tasks=1
Data-local map tasks=27
Rack-local map tasks=3
Total time spent by all maps in occupied slots (ms)=358664
Total time spent by all reduces in occupied slots (ms)=5182
Map-Reduce Framework
Map input records=30
Map output records=60
Map output bytes=540
Map output materialized bytes=840
Input split bytes=4520
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=840
Reduce input records=60
Reduce output records=0
Spilled Records=120
Shuffled Maps =30
Failed Shuffles=0
Merged Map outputs=30
GC time elapsed (ms)=942
CPU time spent (ms)=14180
Physical memory (bytes) snapshot=6924914688
Virtual memory (bytes) snapshot=22422675456
Total committed heap usage (bytes)=5318574080
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=3540
File Output Format Counters
Bytes Written=97
Job Finished in 24.677 seconds
Estimated value of Pi is 3.13777777777777777778job history页面
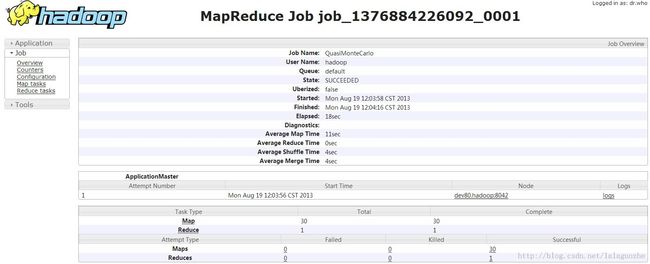
dev80 jps出来的java进程
27172 JobHistoryServer 28627 Jps 26699 ResourceManager 26283 NameNode 26507 DataNode 27014 NodeManager
dev81 jps出来的java进程
3232 Jps 1858 NodeManager 1709 DataNode
这样yarn cluster算搭建完成了
参考:
http://dongxicheng.org/mapreduce-nextgen/hadoop-yarn-install/
本文链接http://blog.csdn.net/lalaguozhe/article/details/10062619,转载请注明