怎么在ArcSDE中使用SQL Server分区表
前面有关于怎么在ArcSDE使用Oracle分区表的相关参考
怎么在ArcSDE中使用Oracle分区表
怎么在ArcSDE中使用Oracle分区表2——索引分区
今天就跟大家介绍一下关于SQL Server库的分区,其实对分区来说大家都明白相关的意义,简单说说oracle与SQL Server分区的区别,对Oracle来说,我们是建立不同的表空间,这些表空间是建立在不同磁盘上,然后根据我们的分区关键字将数据分别存储在不同磁盘上的表空间,那么在读取数据时候,可以从不同磁盘进行小范围的读写或者并发的读写以达到提高性能的需求。
那么对SQLServer来说,没有表空间的概念,但是他是使用了SQLServer特有的文件组的概念,我们可以创建多个文件组,然后创建在所属不同文件组的数据文件,那么这些数据文件也是物理存储在不同的磁盘上,那么在读取数据也可以达到提高性能的需求。
分区表的创建主要有以下四个步骤:
创建文件组和数据文件
创建分区函数
创建分区方案
创建分区表
创建文件组和数据文件
创建文件组这一步并非是必须的,因为可以直接使用数据库的PRIMARY文件,但是,为了方便管理,还是可以先创建几个文件组,这样可以将不同的小表放在不同的文件组里,既便于理解又可以提高运行速度。
添加文件组
创建文件组的方法很简单。打开SQL Server Management Studio,找到需要创建分区表的数据库,右击鼠标,在弹出的菜单中选择属性,在属性页中选择文件组,再点击添加按钮即可。如图所示:
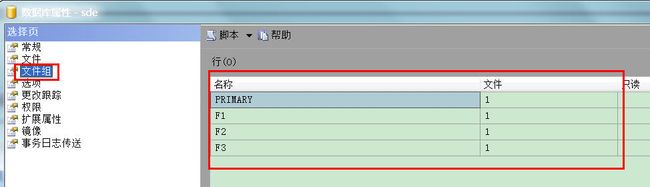
当然,如果习惯与使用代码搞定的也可以使用以下代码来创建文件组
USE [master] GO ALTER DATABASE [sde] ADD FILEGROUP [F1] GO ALTER DATABASE [sde] ADD FILEGROUP [F2] GO ALTER DATABASE [sde] ADD FILEGROUP [F3] GO
添加数据库文件
添加文件组之后,再分别为每一个文件组建立对应的数据文件,为什么要创建数据库文件呢,道理很简单,因为分区后的小表数据要存储到磁盘上。建立数据库文件时,将不同的文件组指定到不同的数据库文件中,当然一个文件组中也可以包含多个数据库文件。如果条件允许的话,可以将不同的文件放在不同的硬盘分区里,最好是放在不同的独立硬盘里。因为IO的速度往往是影响SQL Server运行速度的重要条件之一。将不同的文件放在不同的硬盘上,可以加快SQL Server的运行速度。现在仅以将文数据库文件放到同一个磁盘上为例,如图所示:
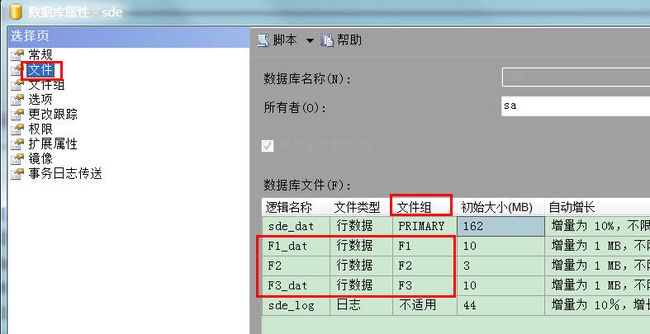
以上设置注意逻辑名称与文件组的对应,后面的物理路径就可以设置在不同磁盘上了
代码参考如下
ALTER DATABASE [sde] ADD FILE ( NAME = N'F1_dat', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\F1_dat.ndf' , SIZE = 3072KB , FILEGROWTH = 1024KB ) TO FILEGROUP [F1] GO ALTER DATABASE [sde] ADD FILE ( NAME = N'F2_dat', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\F2_dat.ndf' , SIZE = 10240KB , FILEGROWTH = 1024KB ) TO FILEGROUP [F2] GO ALTER DATABASE [sde] ADD FILE ( NAME = N'F3_dat', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\F3_dat.ndf' , SIZE = 10240KB , FILEGROWTH = 1024KB ) TO FILEGROUP [F3] GO
创建分区函数
该步骤是告诉我们是以什么方式来进行分区的。
比如我有一个3000条的要素类,我想以ObjectID来进行分区
1:0-1000 一个小表区
2:1000-2000 一个小表区
3:2000以上一个小表区
那么分区函数应该写为
USE sde CREATE PARTITION FUNCTION pf_objectid(int) AS RANGE RIGHT FOR VALUES(1000,2000) go解释一下
CREATE PARTITION FUNCTION:创建分区函数
pf_objectid:分区函数名
(int):分区字段的类型
AS RANGE Right:设置分区范围的方式,Right:右置式(即<),Left:左置式(即<=)
FOR VALUES:分区值,即按这些值对表进行分区
创建分区方案
分区方案的作用是将分区函数生成的分区映射到文件组中去。分区函数的作用是告诉SQLServer如何将数据进行分区,而分区方案的作用则是告诉SQL Server将已分区的数据放在哪个文件组中。分区方案的代码如下所示:
Use sde CREATE PARTITION SCHEME ps_objectid AS PARTITION pf_objectid TO(F1,F2,F3) go
CREATE PARTITION SCHEME:创建分区方案
ps_objectid:分区方案名
AS PARTITION:使用的分区函数
TO:(F1,F2,F3)分区函数划分出来的数据对应存放的文件组
以上步骤全部创建完毕,在SQL Server的manger Studio可以看到

ArcSDE的DBTUNE修改与导入
剩下了 就是修改ArcSDE的Dbtune文件了,至于怎么导出导入具体我就不多说了,如下文件
##PARTITION A_CLUSTER_RASTER 0 A_CLUSTER_ROWID 0 A_CLUSTER_SHAPE 1 A_CLUSTER_STATEID 0 A_CLUSTER_USER 0 A_CLUSTER_XML 0 A_INDEX_RASTER "WITH FILLFACTOR = 75" A_INDEX_ROWID "WITH FILLFACTOR = 75" A_INDEX_SHAPE "WITH FILLFACTOR = 75" A_INDEX_STATEID "WITH FILLFACTOR = 75" A_INDEX_USER "WITH FILLFACTOR = 75" A_INDEX_XML "WITH FILLFACTOR = 75" A_MS_SPINDEX "GRIDS = (MEDIUM, MEDIUM, MEDIUM, MEDIUM), CELLS_PER_OBJECT = 16" A_OUT_OF_ROW 0 A_STORAGE "" AUX_CLUSTER_COMPOSITE 1 AUX_INDEX_COMPOSITE "WITH FILLFACTOR = 75" AUX_STORAGE "" B_CLUSTER_RASTER 0 B_CLUSTER_ROWID 0 B_CLUSTER_SHAPE 1 B_CLUSTER_TO_DATE 0 B_CLUSTER_USER 0 B_CLUSTER_XML 0 B_INDEX_RASTER "WITH FILLFACTOR = 75" B_INDEX_ROWID "WITH FILLFACTOR = 75" B_INDEX_SHAPE "WITH FILLFACTOR = 75" B_INDEX_TO_DATE "WITH FILLFACTOR = 75" B_INDEX_USER "WITH FILLFACTOR = 75" B_INDEX_XML "WITH FILLFACTOR = 75" B_MS_SPINDEX "GRIDS = (MEDIUM, MEDIUM, MEDIUM, MEDIUM), CELLS_PER_OBJECT = 16" B_OUT_OF_ROW 0 B_STORAGE "ON ps_objectid(objectid)"------------------主要修改就这一句 BLK_CLUSTER_COMPOSITE 1 BLK_INDEX_COMPOSITE "WITH FILLFACTOR = 75" BLK_OUT_OF_ROW 0 BLK_STORAGE "" BND_CLUSTER_COMPOSITE 0 BND_CLUSTER_ID 0 BND_INDEX_COMPOSITE "WITH FILLFACTOR = 75" BND_INDEX_ID "WITH FILLFACTOR = 75" BND_STORAGE "" COLLATION_NAME "" CROSS_DB_QUERY_FILTER 0 D_CLUSTER_ALL 0 D_CLUSTER_DELETED_AT 1 D_INDEX_ALL "WITH FILLFACTOR = 75" D_INDEX_DELETED_AT "WITH FILLFACTOR = 75" D_STORAGE "" F_CLUSTER_FID 1 F_INDEX_AREA "WITH FILLFACTOR = 75" F_INDEX_FID "WITH FILLFACTOR = 75" F_INDEX_LEN "WITH FILLFACTOR = 75" F_OUT_OF_ROW 0 F_STORAGE "" GEOM_SRID_CHECK 1 GEOMETRY_STORAGE "SDEBINARY" GEOMTAB_OUT_OF_ROW 0 GEOMTAB_PK "WITH FILLFACTOR = 75" GEOMTAB_STORAGE "" I_STORAGE "" NUM_DEFAULT_CURSORS -1 PERMISSION_CACHE_THRESHOLD 250 RAS_CLUSTER_ID 1 RAS_INDEX_ID "WITH FILLFACTOR = 75" RAS_STORAGE "" RASTER_STORAGE "BINARY" S_CLUSTER_ALL 1 S_CLUSTER_SP_FID 0 S_INDEX_ALL "WITH FILLFACTOR = 75" S_INDEX_SP_FID "WITH FILLFACTOR = 75" S_STORAGE "" UI_TEXT "User Interface text for DEFAULTS" UNICODE_STRING "TRUE" XML_COLUMN_STORAGE "DB_XML" XML_DOC_INDEX "WITH FILLFACTOR = 75" XML_DOC_OUT_OF_ROW 0 XML_DOC_STORAGE "" XML_DOC_UNCOMPRESSED_TYPE "BINARY" XML_IDX_CLUSTER_DOUBLE 0 XML_IDX_CLUSTER_ID 0 XML_IDX_CLUSTER_PK 1 XML_IDX_CLUSTER_STRING 0 XML_IDX_CLUSTER_TAG 0 XML_IDX_FULLTEXT_CAT "SDE_DEFAULT_CAT" XML_IDX_FULLTEXT_LANGUAGE "" XML_IDX_FULLTEXT_TIMESTAMP 1 XML_IDX_FULLTEXT_UPDATE_METHOD "CHANGE_TRACKING BACKGROUND" XML_IDX_INDEX_DOUBLE "WITH FILLFACTOR = 75" XML_IDX_INDEX_ID "WITH FILLFACTOR = 75" XML_IDX_INDEX_PK "WITH FILLFACTOR = 75" XML_IDX_INDEX_STRING "WITH FILLFACTOR = 75" XML_IDX_INDEX_TAG "WITH FILLFACTOR = 75" XML_IDX_OUT_OF_ROW 0 XML_IDX_STORAGE "" END其实核心的修改就是B_STORAGE "ON ps_objectid(objectid)"
也就是说,针对基表的操作,使用分区方案ps_objectid,而且是针对objectid字段来定义的,怎么定义,分区函数以及说明清楚了。
使用SDE命令将DBTUNE文件导入进去即可,那么使用ArcCatalog将相关数据选择PARTITION关键字导入即可。
以下进行相关验证
通过如下SQL语句,可以确定,ObjectID=X的相关值是存储在第几号物理分区
C:\Users\Administrator>sqlcmd -U sde -P sde -D sde
Sqlcmd: 警告:“-D”是过时的选项,已忽略。
1> select $partition.pf_objectid(1000)
2> go
-----------
2
(1 行受影响)
1> select $partition.pf_objectid(2000)
2> go
-----------
3
(1 行受影响)
1> select $partition.pf_objectid(500)
2> go
-----------
1
(1 行受影响)同样我们也可以针对某个物理分区来说的存储在这个物理分区的相关信息
1> select count(objectid) from sde.ZD1 where $partition.pf_objectid(OBJECTID)=1
2> go
-----------
999
(1 行受影响)
1> select TOP 10 objectid from sde.ZD1 where $partition.pf_objectid(OBJECTID)=1
2> go
objectid
-----------
1
2
3
4
5
6
7
8
9
10
(10 行受影响)
1> select TOP 10 objectid from sde.ZD1 where $partition.pf_objectid(OBJECTID)=2
2> go
objectid
-----------
1000
1001
1002
1003
1004
1005
1006
1007
1008
1009
(10 行受影响)
1> select TOP 10 objectid from sde.ZD1 where $partition.pf_objectid(OBJECTID)=3
2> go
objectid
-----------
2000
2001
2002
2003
2004
2005
2006
2007
2008
2009
(10 行受影响)如果我需要统计每个物理分区的信息个数也可以使用如下SQL语句
1> use sde
2> select $partition.pf_objectid(OBJECTID) as 分区编号,count(objectid) as 记录数 from sde.sde.ZD1 group by $partition.pf
_objectid(OBJECTID)
3> go
已将数据库上下文更改为 'sde'。
分区编号 记录数
----------- -----------
3 2556
1 999
2 1000
(3 行受影响)核对一下总数是一致的
1> select count(*) from sde.sde.ZD1
2> go
-----------
4555
(1 行受影响)
-------------------------------------------------------------------------------------------------------
版权所有,文章允许转载,但必须以链接方式注明源地址,否则追究法律责任!
------------------------------------------------------------------------------------------------------