MongoDB之增删改查(二)
我在上文介绍了MongoDB的增加、删除还有修改的基本操作,这里介绍下查询的一些方法。
find
最基本的就是find和findOne方法了。find会返回集合里面所有的文档,如果只想查看一个文档,可以用findOne。使用find的时候,shell自动最多显示20个匹配文档。

MongoDB使用find来进行查询.查询就是返回一个集合中文档的子集,子集合的范围从0个文档到整个集合。
find的第一个参数决定了要返回哪些文档.其形式也是一个文档,说明要查询的细节。空的查询文档{}会匹配集合的全部内容.要是不指定查询文档,默认是{}。如:db.person.find()返回集合person中的所有内容。向查询文档中添加键值对,就意味着添加了查询条件。对绝大多数类型来说,整数匹配整数,布尔类型匹配布尔类型,字符串匹配字符串。
返回指定项
有时候我们并不需要将文档中所有的键值都返回,这时我们就可以通过find或findOne的第二个参数来指定要返回的键。这样既节省了传输的数据量,又节省了客户端解码文档的时间和内存消耗。
如下例,只将id,age,sex属性返回:
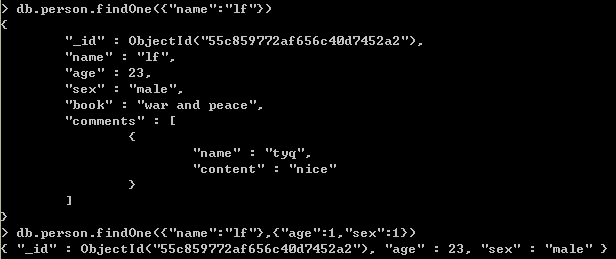
也可以利用第二个参数来剔除查询结果中的某个键值对,例如:
键name不会显示在返回结果中:
db.person.findOne({"name":"lf"},{"name":0})只将age和sex返回,id也不返回:
db.person.findOne({"name":"lf"},{"age":1,"sex":1,"_id":0})查询条件
MongoDB的语法不似SQL,它的条件判断全部是由代码来实现而不是符号。
| MongoDB | SQL |
|---|---|
| $lt | < |
| $lte | <= |
| $gt | > |
| $gte | >= |
| $ne | != |
| $in | between |
| $nin | not between |
| $or | 无 |
| $not | not |
| $size | 无 |
| $slice | 无 |
$gt###
如:
查询年龄>=18 <=30:
方法如下:
db.person.find({"age":{"$gte":18,"$lte":30}})再比如日期的查询,先向文档中添加键birthday,
db.person.update(
{"name":"lf"},
{
"$set":
{
"birthday":new Date("1992/7/22")
}
}
)
查询birthday日期是1990-1-1之后的人:
db.person.find({"birthday":{"$gt":new Date("1990/01/01")}})$ne
查出所有name不等于lf的文档,其中集合中不存在name的文档也会被查出来:
db.person.find({"name":{"$ne":"lf"}})$in
$in可以用来查询范围内的值,例如:查询出pageViews为10000,20000的数据:
db.person.find({pageViews:{"$in":[10000,20000]}})$in还可以用来指定不同类型的条件和值,如正在将用户的ID号迁移成用户名的过程中,要做到两者兼顾的查询:
db.person.find({"user_id":{"$in":[12345,"lf"]}})这样会匹配user_id为12345和lf的文档。
如果$in中只有一个值,就和直接匹配这个值的效果一样:
db.person.find({"pageViews":{"$in":[10000]}})
db.person.find({"pageViews":10000})
$nin
$nin可以返回与数组中所有条件不匹配的文档。
如:查出所有pageViews不等10000,20000的文档,注意 文档中不存在键pageViews的文档也会被查出来:
db.person.find({"pageViews":{"$nin":[10000,20000]}})$or
$or是用来返回或结果的,只要满足条件数组中任意一条,都将返回:
db.person.find(
{
"$or":
[
{"pageViews":{"$in":[10000,20000]}},
{"url":"http://blog.cdsn.net/mevicky "}
]
}
)
将查询出pageViews是10000,20000或url是http://blog.cdsn.net/mevicky的文档。
$not
$not可以用在任何条件之上:
db.users.find(
{"id_num":{"$not":{"mod":[1,5]}}}
)
$size
$size 可以用来查询指定长度的数组:
db.person.find({"emails":{"$size":2}})这里需要注意一点的是,$size方法不能和其他查询子句结合使用,
比如$gt,所以我们可以采用另外一种方式,就是给每个数组所在文档定义一个size键,
将原来的数组添加操作:
db.person.update({"$push":{"emails":"362512489@qq.com"}})改为:
db.person.update({"$push":{"emails":"362512489@qq.com "},"$inc":{"size":1}})这样就可以查询了:
db.person.find({"size":{"$gt":3}})$slice
$slice用来返回数组的子集合,
例如 :
返回emails数组的前两个元素
db.person.find({"userName":"lf"},{"emails":{"$slice":2}})返回emails数组的后两个元素
db.person.find({"userName":"lf"},{"emails":{"$slice":-2}})返回emails数组的第2个和第11个元素.如果数组不够11个,则返回第2个后面的所有元素
db.person.find({"userName":"lf"},{"emails":{"$slice":[1,10]}})正则查询
和关系型数据库一样,MongoDB也支持正则表达式查询,从而灵活有效的匹配字符串。
MongoDB的查询是不输于关系型数据库的,其查询条件的复杂用法远不是上文就全部涵盖得了的,想要掌握的全面透彻还得进一步研究。
内嵌文档查询
下面说说内嵌文档的查询,众所周知,NoSQL存储文档的工作模式代表了其数据模型可以非常的复杂和灵活,那么查询起来会不会有困难呢?
有两种方法查询内嵌文档:查询整个文档,或者只针对其键值对进行查询。
查询整个内嵌文档的方法和普通查询相同:
db.person.insert(
{
"name":
{
"first":"lf",
"last":"tyq"
},
"age":23
}
)
查找姓名为name的文档
db.person.find({"name":{"first":"lf","last":"tyq"}})但是
db.person.find({"name":{"first":"lf"}})这样不能查询出文档.

所以最好通过内嵌文档的特定的键值来进行查找。这样即便数据模型改变,也不会导致查询失效:
db.person.find({"name.first":"lf","name.last":"tyq"})
db.person.find({"name.first":"lf"})//这个也可以查出文档.
通过.操作符一步一步内嵌文档,是不是很方便呢?当文档结构变得更加复杂后,内嵌文档的匹配更加需要技巧:
db.person.insert(
{
"title":"blog",
"comments":
[
{
"author":"lf",
"score":3,
"comment":"nice"
},
{
"author":"tyq",
"score":6,
"comment":"good"
}
]
}
)
现在我们想要查询键author为tyq,score大于等于5的评论,不能使用:
db.person.find(
{"comments":{"author":"tyq","score":{"$gte":5}}}
)
点操作符同样得不到结果:
db.person.find(
{"comments.author":"tyq","comments.score":{"$gte":5}}
)
这是为什么呢?因为符合author条件的评论和符合score的评论可能不是同一条评论。
所以需要用到$elemMatch,来确定一组条件,而不用指定每个键:
db.person.find(
{
"comments":
{
"$elemMatch":
{
"author":"tyq",
"score":{"$gte":5}
}
}
}
)
$elemMatch将限定条件进行分组,仅当需要对一个内嵌文档的多个键操作时才会用到。
