Cocos2d-x学习(二十三):Base64解码
使用过Tiled的朋友应该都有所了解,Tiled生成的tmx格式的文件其实就是xml,唯一特殊的地方就是tmx文件中都会有一个或者多个"data"的节点,用来存放Tiled的块数据!类似于这样的格式
<map version="1.0" orientation="orthogonal" width="40" height="40" tilewidth="32" tileheight="32"> <tileset firstgid="1" source="desert.tsx"/> <layer name="Ground" width="40" height="40"> <data encoding="base64" compression="zlib"> eJztmNkKwjAQRaN9cAPrAq5Yq3Xf6v9/nSM2VIbQJjEZR+nDwQZScrwztoORECLySBcIgZ7nc2y4KfyWDLx+Jb9nViNgDEwY+KioAXUgQN4+zpoCMwPmQAtoAx2CLFbA2oDEo9+hwG8DnIDtF/2K8ks086Tw2zH0uyMv7HcRr/6/EvvhnsPrsrxwX7rwU/0ODig/eV3mh3N1ld8eraWPaX6+64s9McesfrqcHfg1MpoifxcVEWjukyw+9AtFPl/I71pER3Of6j4bv7HI54s+MChhqLlPdZ/P3qMmFuo5h5NnTOhjM5tReN2yT51n5/v7J3F0vi46fk+ne7aX0i9l6If7mpufTX3f5wsqv9TAD2fJLT9VrTn7UeZnM5tR+v0LMQOHXwFnxe2/warGFRWf8QDjOLfP </data> </layer> </map>
很明显,data数据已经被加密了,根据data的属性,可以得知是在压缩后进行了Base64编码!
1.什么是Base64:
我自己的总结就是 源字符串的二进制格式(之前一个字符由8位二进制位表示),拆分成6位二进制位,前面两位补0,组成新的8位二进制位的字符(这样可以保证新的字符只占8位中的低6位),也就是说用2^6=64个字符来表示原字符的一部分,暂时忘掉字符与ascii码之间的关系,Base64定义了一套字符表(即26个大写字母,26个小写字母,10个阿拉伯数字,已经‘+’'/'两个符号组成64个字符),详情请点击
2.解码:
(1)字符表
我使用了一个std::map<unsigned char, unsigned int>来保存Base64的字符表,键为64个Base64字符,值为相对索引
(26个大写字母,26个小写字母,10个阿拉伯数字,已经‘+’'/'两个符号的索引为从0到63)
(2)4的倍数
根据Base64的定义可以得知,Base64编码后的每4个字节对应原码的每3个字节,所以Base64编码后的字符的个数必须是4的倍数 (图片来源于wiki)

问题来了,如果原码是2个字符,应该对应的Base64编码是 2*4/3个,这样并不合理,需要我们在结尾处做特殊处理才能得到正确的结果,于是Base64定义为如果原码个数%3=1,则补2个'=';如果原码个数%3=2,则补1个‘=’。于是就有了Base64编码后面有0,1,2个=符号的可能,而在解码的时候会将'='解码为0.
(3)四变三
根据Base64的定义可知,每个字符的高2位都是0,只有填充的意义,而每个字符的低6位需要两两组合运算得到源码,将Base64编码后字符4个分成1组(可以解码出3个原码),我用A,B,C,D表示Base64编码后的字符,a,b,c表示1,2,3,4解码后的原码,根据规则可以得出:
a = (A << 2) + (B >> 4)
b = (B << 4) + (C >> 2)
c = (C << 6) + D
具体代码实现(Qt版本)
for (; i<(size-4); i+=4)
{
unsigned char c1 = simplifiedText[i].toAscii();
unsigned char c2 = simplifiedText[i+1].toAscii();
unsigned char c3 = simplifiedText[i+2].toAscii();
unsigned char c4 = simplifiedText[i+3].toAscii();
if (!IsBase64Character(c1) || !IsBase64Character(c2) ||
!IsBase64Character(c3) || !IsBase64Character(c4))
{
return Base64ParseError_Illegal_CH;
}
unsigned char ch1 = mAlphabetMap[c1];
unsigned char ch2 = mAlphabetMap[c2];
unsigned char ch3 = mAlphabetMap[c3];
unsigned char ch4 = mAlphabetMap[c4];
desText.append((unsigned char)((ch1 << 2) + (ch2 >> 4)));
desText.append((unsigned char)((ch2 << 4) + (ch3 >> 2)));
desText.append((unsigned char)((ch3 << 6) + ch4));
}
这里的范围只用到了size-4,是考虑到末尾4位的不确定性
unsigned char ch3 = 0;
unsigned char ch4 = 0;
if (c3 == '=' && c4 != '=')
{
return Base64ParseError_Illegal_CH;
}
else if (c3 != '=' && c4 != '=')
{
ch3 = mAlphabetMap[c3];
ch4 = mAlphabetMap[c4];
}
else if (c3 != '=' && c4 == '=')
{
ch3 = mAlphabetMap[c3];
ch4 = 0;
}
3.测试解码
我选择了wiki上的一段文本,测试如图
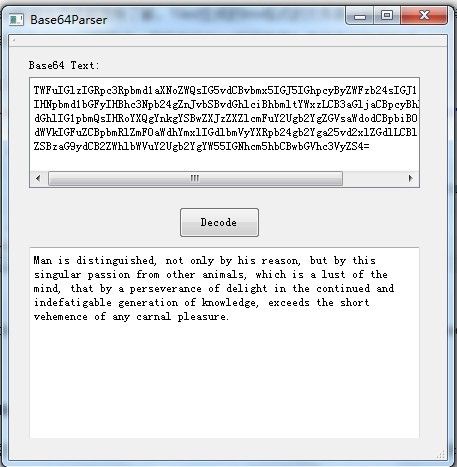
(PS:还有一个检查字符是否为Base64的方法,只要在map中检测键值就可以了,这也是我选择map的原因。)
这个目前对于Tiled的研究还没有太大帮助,因为数据在进行Base64编码之前先进行了zip的压缩。