Shell编程入门
或许﹐许多人都已经听过shell 或bash 这些名字﹐但不知道您是否知道它们究竟是什么东东呢﹖
先回到电脑基础常识上吧﹕所有的电脑都是由硬体和软体构成的﹐硬体就是大家能摸得着看得见的部份﹐例如﹕键盘﹑荧幕﹑CPU﹑记忆体﹑硬碟﹑等等。离开了硬体﹐所谓的电脑是不存在的﹐因为整个系统的输入和输出以及运算都离不开硬体。请问﹕如果没有键盘和荧幕您是怎样使用电脑的﹖ 但是﹐您透过键盘进行的输入﹐以及从荧幕看到的输出﹐真正发挥功能的﹐是软体的功劳。而直接负责和这些硬体进行沟通的软体﹐就是所谓的核心(kernel)﹐kernel 必须能够接管键盘的输入﹐然后交由CPU 进行处理﹐最后将执行结果输出到荧幕上。当然﹐除了键盘和荧幕外﹐所有的硬体都必须获得kernel 的支援才能使用。
那么﹐kernel 又如何知道我们键盘输入的东西是什么呢﹖ 那就是我们这里介绍的shell 所负责的事情了。因为电脑本身所处理的数据﹐都是二进位的机器码﹐和我们人类习惯使用的语言很不一样。比方说﹐输入pwd 命令﹐我们知道这是print working directory 的意思(非常简单的人类语音)﹐但作为kernel 来说﹐它并不知道pwd 是什么﹐kernel 只会看机器码﹐这时候﹐shell 就会帮我们将pwd 翻译为kernel 能理解的程式码。所以﹐我们在使用电脑的时候﹐基本上就是和shell 打交道﹐而不是直接和kernel 沟通﹐更不是直接控制硬体。
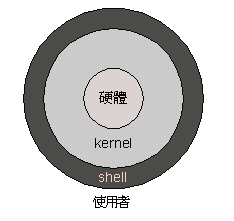
简单来看﹐我们就这样来看待它们的关系﹕光从字面来解析的话﹐shell 就是“壳”﹐kernel 就是“核”。好比一个果实一样﹐您第一眼看到的就是壳﹐把壳扒开才看的到里面的核。shell 就是使用者和kernel 之间的界面﹐将使用者下的命令翻译给kernel 处理﹐关系如下图﹕
我们在shell 输入一个命令﹐shell 会尝试搜索整个命令行﹐并对其中的一些特殊字符做出处理﹐如果遇到CR 字符( Enter ) 的时候﹐就尝试重组整行命令﹐并解释给kernel 执行。而一般的命令格式(syntax)大致如下﹕
| # command parameter1 patrameter2 ... |
各命令都有自己的选项(options, 通常用“ - ”符号带领)﹐可输入也可以不输入﹐如果没有额外指定﹐命令通常都有自己的预设选项﹔而参数(argument)则视各程式要求而定﹐有些很严格﹐有些也有预设的参数。例如"ls -l" 这个命令﹐选项是-l (long list)﹐而预设的参数则是当前目录。在命令行中,选项和参数都被称为参项(parameter)。
我们经常谈到的Linux﹐其实是指kernel这部份﹐而在kernel之外﹐则是各种各样的程式和工具﹐整合起来才成为一个完整的Linux发行套件。无论如何﹐Linux的kernel只有一个(尽管有许多不同的版本﹐都由Linus Tovalds负责维护)﹐但kernel之外的shell却有许多种﹐例如bourne Shell﹑C Shell﹑Korn Shell﹑Zsh Shell﹑等等﹐但我们最常接触到的名叫BASH (Bourne Again SHell)﹐为GNU所加强的一个burne shell版本﹐也是大多数Linux套件的预设shell 。不同的shell都各自有其不同的优缺点﹐有兴趣您可以自行找这方面的资料来看﹐我这里就不一一介绍了。
BASH 这个优秀的shell﹐之所以会被各大Linux 套件采用为预设的shell﹐除了它本身是open source 程式之外﹐它的强大功能应该是吸引大家目光的重要因素之一。BASH 的功能很多﹐实在很难全部介绍﹐下面只列举其中一少部份而已﹕
- 命令补全功能﹕
-
当您输入命令的时候﹐您可以输入目录或档案的开首字面﹐然后按'tab'键将您的命令路径补全。比方说﹐您要ls 一下/etc/sysconfig 这个目录的内容(假设您已经在/etc 目录下了)﹐您可以只输入ls sy 然后接连按两下tab 键﹐然后就会将/etc/ 目录下所有以sy 开头的档案和目录显示出来﹐您或许可以看到sysconfig﹑sysctl.conf ﹑syslog.conf 这三个结果﹔如果您只输入ls sys 再按两下tab 的话﹐结果是是一样的﹐因为在/etc/ 目录下面﹐所有以sy 开头的档案﹐第3 个字面都是s 而没有其它字面了﹔如果您输入ls sysc 再重复这个动作﹐那么显示结果就剩下sysconfig 和sysctl.conf 而已﹐因为以sysc 开头的只有这两个档﹐如果您再按ls sysco 接一个tab﹐那就会帮您将sysconfig 这个唯一以sysco 开头的档案补全。
如果您所输入的路径﹐是唯一的﹐那么只要按一下tab 就能补全﹐否则﹐会听到一下beat 声﹐这时您再补一下tab ﹐就会将所有以此路径开头的档案列出来﹔假如符号条件的档案太多﹐那系统会先将符号条件的档案数目告诉您﹐例如242 possibilities﹐然后您按y 才显示﹐如果按n 则让您增加命令的输入﹐然后您可以重复这些动作﹐直到您所输入的路径只剩唯一的对应﹐才可以用一个tab 补全。
同样的﹐这个功能也可以用在输入命令的时候﹐比方说﹐您要输入Xconfigurator 命令﹐那您只需输入Xc 然后按一下tab 就可以了﹗ 是否很方便呢﹖ ^_^
Tip﹕ 用tab来补全命令﹐不但方便迅速﹐而且也比较保险。因为﹐如果您前面的路径输入不正确﹐用tab是不能完成补全的﹐这可以避免您输入错误的路径而执行错误的程式。我强烈建议您执行每一个命令都常试用tab补全功能﹐以确保其正确性。(多敲这个tab键没什么坏处啦) - 命令记录表﹕
-
每次您输入一个命令﹐并按Enter执行之后﹐那您这个命令就被存放在命令记录表(command history)中﹐而每个命令都有一个记录号码﹐您可以用
history
命令来看看当前的命令历史表。这样﹐您只要用向上方向键﹐就可以依次呼叫出您最近所输入的命令﹐按下方向键则退回最新的命令﹐找到您想要重新输入的命令﹐然后再按Enter即可。
不过﹐也有一下更便利的办法﹕您可以输入! nnn (其中的nnn是history命令找到的命令记录号码)﹐就能执行指定的旧命令了﹔如果您输入!!再Enter的话﹐那就是重复上一个命令(和按向上方向键再Enter一样)﹔如果您输入!ls的话﹐则是最后一次的ls开头的命令﹐如果是!cd那就是上一个cd开头的命令﹐如此类推﹔如果您按着Ctrl和R两个键之后﹐然后输入您以前曾经输入过的命令﹐那它会和上面介绍的补全功能一样﹐将您以前输入过的命令补全起来。呵~~太厉害啦﹗
Bash会将您登录之后的所有命记录在记cache里面﹐然后﹐只要您成功退出这个shell之后﹐那这些记录就会存放到家目录的~/.bash_history这个档里面(小心看﹐它是以.开头的档案哦﹐也就是隐藏档是也﹐您要用ls -a才看得到。)不过﹐这个档只保持一定数量的命令记录而已﹐您可以透过$HISTFILESIZE这个变数(我们马上会介绍变数)﹐来获得或改变档案的记录数量。
- alias 功能﹕
-
在Linux 里面﹐您可以透过alias (别名) 的功能﹐来定义出一个命令的预设参数﹐甚至用另外一个名称来简化一个命令(及参数)。如果您输入alias 这个命令﹐您就会看到目前的alias 有哪些。您或许会看到其中有一个﹕ alias rm='rm -i' 这行﹐它的意思是﹕如果您执行rm 这个命令﹐那么系统实际执行的命令会带上-i 的参数﹐也就是以interactive模式进行﹐结果是在您进行删除档案的时候﹐会经过您的确认才真正删除。在某些没有这个alias 的系统中﹐那您执行rm 而不另行指定-i 的话﹐那就无声无息的将您能砍的档案给砍掉。小心哦﹐在Linux 上面﹐档案一旦删除就没办法救回了﹗ 所以﹐用心的系统﹐会帮您做这个alias。
在另外一种情形之下﹐当您发现某些长命令会经常使用到﹐但打字起来挺麻烦的﹐那您就可以用alias 来解决。比方说﹐您每次关机要输入的命令是shutdown -h now 这么一串﹐那您先输入which shd (目的是确定现有的命令名称)﹐如果您并没有发现这个命令出现在您的命令路径之中的话﹐那您可以输入alias shd='shutdown -h now'﹐然后再输入shd 就可以关机了﹗ 不过﹐现在不要执行它﹗ ﹗ 因为您这样真的会把机器关掉哦~~ 请您用alias 替换其它的长命令看看﹖
如果您要取消一个alias﹐可以使用unalias命令﹐如﹕unalias shd 。
一旦您满意您的新alias ﹐那您可以修改您的~/.bashrc 这个档﹐将它加在其它alias 命令之后﹔假如您想系统上所有使用者都能使获得这个alias ﹐那就将它放到/etc/bashrc 里面吧。(如果您目前还不会编辑档案﹐那就回到上一章补习vi 吧:-)
- 强大的script 能力
- 玩过DOS 的朋友﹐一定会知道batch 档案的功能﹐在BASH 本身可以帮您执行一系列根据条件判断的命令﹐其功能比DOS 的batch 强大多了。在本章的后面部份﹐会详细讨论shell script 的基本技巧。
环境变数
还记得上一章里面﹐我曾经提到过﹕当我们登入系统的时候﹐首先就获得一shell﹐而且它也占据一个行程﹐然后再输入的命令都属于这个shell 的子程式。如果您学习够细心﹐不难发现我们的shell 都在/etc/passwd 这个档里面设定的﹐也就是帐号设定的最后一栏﹐预设是/bin/bash 。
事实上﹐当我们获得一个shell之后﹐我们才真正能和系统沟通﹐例如输入您的命令﹑执行您的程式﹑等等。您也可以在获得一个shell之后﹐再进入另外一个shell (也就是启动一个子程式)﹐然后还可以再进入更深一层的shell (再进入子程式的子程式)﹐直到您输入exit才退回到上一个shell里面(退回上一级的父程式)。假如您已经阅读过上一章所说过的子程式概念﹐应该不难理解。不过﹐您的行为也不是无限制的﹐而且﹐有许多设定都必须事先得到定义。所以﹐当您获得shell的时候﹐同时也获得一些环境设定﹐或称为“环境变数( Environment variables) ”。
所谓的变数( variable ) ﹐就是用特定的名称(或标签)保存一定的设定值﹐然后供程式将来使用。例如﹐姓=chen ﹔名=kenny ﹐那么'姓'和'名'就是变数名称﹐而chen和kenny就是变数所保存的值。由shell所定义和管理的变数﹐我们称为环境变数﹐因为这些变数可以供shell所产生的所有子程式使用。环境变数名称一般都用大写字母表示﹐例如﹐我们常用的环境变数有这些﹕
| 变数名称 | 代表意思 |
| HISTCMD | 当前命令的记录号码。 |
| HISTFILE | 命令记录表之存放档案。 |
| HISTSIZE | 命令记录表体积。 |
| HOME | 预设登录家目录。 |
| IFS | 预设分隔符号。 |
| LINENO | 当前命令在shell script 中的行数。 |
| 邮件信箱的路径。 | |
| MAILCHECK | 检查邮件的秒数。 |
| OLDPWD | 上次进入的目录路径。 |
| OSTYPE | 作业系统类型。 |
| PATH | 预设命令搜索路径。 |
| PPID | 父程式之PID。 |
| PWD | 当前工作目录路径。 |
| SECONDS | 当前shell 之持续启动时间。 |
| SHELL | 当前shell 之执行路径。 |
| TMOUT | 自动登出之最高闲置时间。 |
| UID | 使用者之UID。 |
| $ | 当前shell 之PID。 |
| ﹖ | 最后一个命令之返回状态。 |
假如您想看看这些变数值是什么﹐只要在变数名称前面加上一个“ $ ”符号﹐然后用echo命令来查看就可以了﹕
| # echo $PWD /root # echo $$ 1206 # echo $? 0 |
第一个命令就是将当前目录的路径显示出来﹐和您执行pwd 命令的结果是一样的﹔第二个命令将当前这个shell 的PID 显示出来﹐也就是1206。如果您这时候输入kill -9 1206 的话﹐会将当前的shell 砍掉﹐那您就要重新登录才能获得另外一个shell﹐而它的PID 也是新的﹔第三行命令是上一个命令的返回状态﹕如果命令顺利执行﹐并没有错误﹐那通常是0﹔如果命令遇到错误﹐那返回状态则是非0 ﹐其值视程式设计者而定(我们在后面的shell script 的时候会介绍)。关于最后一个命令﹐不妨比较一下如下结果﹕
| # ls mbox mbox # echo $? 0 # ls no_mbox ls: no_mbox: No such file or directory # echo $? 1 |
您会发现﹕第一命令成功执行﹐所以其返回状态是0 ﹔而第二个命令执行失败﹐其返回状态是1 。假如程式设计者为不同的错误设定不同的返回状态等级﹐那您可以根据返回值推算出问题是哪种错误引起的。
Tips﹕ 如果您日后写程式或script﹐要养成一个习惯﹐为每一种命令结果设定返回状态。这非常重要﹐尤其在进行debug的时候。这个我们在后面学习script的时候再谈。
我们随时都可以用一个= (等号)来定义一个新的变数或改变一个原有变数。例如﹕
| # MYNAME=kenny # echo $MYNAME kenny |
假如您要取消一个定义好的变数﹐那么﹐您可以使用unset命令﹕
| # unset MYNAME |
不过﹐环境变数的特性之一﹐是单向输出的。也就是说﹕一个shell的特定变数﹐只能在这个shell里面使用。如果您要分享给同一个shell里面的其它程式﹑script﹑命令使用﹐或它们的子程式使用﹐那您必须用export命令将这个变数进行输出。但无论如何﹐如果您在一个子程式中定义了一个变数﹐那么这个变数的值﹐只影响这个子程式本身以及它自己的子程式﹐而永远不会影像到父程式或父程式产生的其它子程式。
比方说﹐您在一个程式中定义一个新的变数﹐或改变一个原有变数值﹐在程式结束的时候﹐那它所设定的变数均被取消﹔如果您想将变数值分享给该程式所产生的子程式﹐您必须用export 命令才能保留这个变数值﹐除非子程式另外重新定义。但无论如何﹐当前程式所定义的变数值﹐是无法传回父程式那边的。不妨做做如下的实验﹕
| # MYNAME=kenny # echo $MYNAME kenny # export MYNAME |
#设定一个变数。 # #当前的设定值。 #用export输出变数值。 |
| # /bin/bash | # 再开一个shell﹐也就是进入子程式中。 |
| # echo $MYNAME kenny |
# # 保留原有设定值。 |
| # export MYNAME=netman # echo $MYNAME netman |
# 重新定义设定值﹐同时也用export 输出。 # |
| # exit | # 退出子程式﹐返回父程式。 |
| # echo $MYNAME kenny |
# # 父程式的变数值并没有改变。 |
关于变数的另一个特性﹐是的变数值是可以继承的。也就是说﹐您可以将一个变数值来设定另外一个变数名称。比方说﹕
| # FIRST_NAME="Kenny" # echo $MYNAME |
# 定义一个变数。 # 再定义另一个变数﹐但它的值是第一个变数。 # |
另外﹐在定义变数的时候您还要注意一些规则﹕
- 定义变数时﹐“=”号两边没有空白键﹔
- 作为变数的名称﹐只能是字母和数字﹐但不能以数字开头﹔如果名称太长﹐可以用“_”分隔﹔
- 预先定义的变数均为大写﹐自定义变数可以混合大小写﹐以更好区别﹔
- 只有Shell 本身定义的变数才能称为环境变数;
- 如果变数中带有特殊字符﹐必须先行用“\”符号跳脱﹔
- 如果变数中带有空白﹐必须使用引号﹐或进行跳脱。
关于后两项﹐或许我们再找些例子来体会一下﹕
| # TOPIC='Q & A' |
# 用单引号保留特殊符号和空白 |
|
# Q1=What\'s\ your\ \"topic\"\? # echo $Q1 |
# 用\ 将特殊符号(含引号)和空白跳脱出来 # # 跳脱后﹐特殊符号和空白都保留下来。 |
|
# ANS="It is $TOPIC." # echo $ANS |
# 用双引号保留变数值($) # # 用双引号﹐显示出变数值。 |
|
# WRONG_ANS='It is "$TOPIC".' # echo $WRONG_ANS
|
# 用单引号保留特殊符号和空白(同第一行) # # $ 也当成一般符号保留﹐而非变数值。 |
|
# ALT_ANS='the $TOPIC'\ is\ "'$TOPIC'"\. # echo $ALT_ANS
|
# 同时混合单引号﹑双引号﹑和跳脱字符 \ # #单引号保留全部﹔双引号保留变数值﹔ |
我这里解释一下最后面的例子好了﹕ 'the $TOPIC is '"$TOPIC"\.。首先用单引号将'the $TOPIC is '这段文字括好﹐其中用3个空白键和一个$符号﹔然后用双引号保留$TOPIC的变数值﹔最后用\跳脱小数点。
在引用" " 和' ' 符号的时候﹐基本上﹐ ' ' 所包括的内容﹐会变成单一的字串﹐任何特殊字符都失去其特殊的功能﹐而变成一般字符而已﹐但其中不能再使用'符号﹐而在" " 中间﹐则没有' ' 那么严格﹐某些特殊字符﹐例如$ 号﹐仍然保留着它特殊的功能。您不妨实作一下﹐比较看看echo ' "$HOME" ' 和echo " '$HOME' " 的差别。
Tips﹕ 在shell命令行的跳脱字符“ \ ”其实我们会经常用到的。例如﹐您的一个命令太长﹐一直打下去可能超过一行﹐或是想要整洁的输入命令行﹐您或许想按Enter键敲到下一行继续输入。但是﹐当您敲Enter键的时候﹐事实上是输入一个CR (Carriage-Return)字符﹐一但shell读到CR字符﹐就会尝试执行这个命令。这时﹐您就可以在输入Enter之前先输入\符号﹐就能将CR字符也跳脱出来﹐这样shell就不会马上执行命令了。这样的命令行﹐我们在script中经常看到﹐但您必须知道那代表什么意思。
如果﹐您想对一些变数值进行过滤﹐例如﹕MY_FILE=' ~/tmp/test.sh' ﹐而您想将变数值换成test.sh (也就是将前面的路径去掉)﹐那您可以将$MY_FILE换成${MY_FILE##*/}。这是一个变数值字串过滤﹕##是用来比对变数前端部份﹐然后*/是比对的色样(也就是任何字母到/之间)﹐然后将最长的部份删除掉。您可以参考如下范例﹕
当FNAME="/home/kenny/tmp/test.1.sh" 的时候﹕
| 变数名称 | 代表意思 | 结果 |
| ${FNAME} | 显示变数值的全部。 | /home/kenny/tmp/test.1.sh |
| ${FNAME##/*/} | 比对变数值开端﹐如果以/*/ 开头的话﹐砍掉最长的部份。 | test.1.sh |
| ${FNAME#/*/} | 比对变数值开端﹐如果以/*/ 开头的话﹐砍掉最短的部份。 | kenny/tmp/test.1.sh |
| ${FNAME%.*} | 比对变数值末端﹐如果以.* 结尾的话﹐砍掉最短的部份。 | /home/kenny/tmp/test.1 |
| ${FNAME%%.*} | 比对变数值末端﹐如果以.* 结尾的话﹐砍掉最长的部份。 | /home/kenny/tmp/test |
| ${FNAME/sh/bash} | 如果在变数值中找到sh 的话﹐将第一个sh 换成bash。 | /home/kenny/tmp/test.1.bash |
| ${FNAME//sh/bash} | 如果在变数值中找到sh 的话﹐将全部sh 换成bash。 | /home/kenny/tmp/test.1.bash |
您除了能够对变数进行过滤之外﹐您也能对变数做出限制﹑和改变其变数值﹕
| 字串没设定 | 空字串 | 非空字串 | |
| 使用预设值 | |||
| var=${str-expr} | var=expr | var= | var=$str |
| var=${str:-expr} | var=expr | var=expr | var=$str |
| 使用其它值 | |||
| var=${str+expr} | var=expr | var=expr | var=expr |
| var=${str:+expr} | var=expr | var= | var=expr |
| 设定预设值 | |||
| var=${str=expr} | str=expr var=expr |
str 不变 var= |
str 不变 var=$str |
| var=${str:=expr} | str=expr var=expr |
str=expr var=expr |
str 不变 var=$str |
| 输出错误 | |||
| var=${str?expr} | expr 输出至stderr | var= | var=str |
| var=${str:?expr} | expr 输出至stderr | expr 输出至stderr | var=str |
一开始或许比较难理解上面的两个表格说明的意思﹐真的很混乱~~ 但只要多做一些练习﹐那您就知道怎么使用了。比方说﹕
| # expr=EXPR # unset str # var=${str=expr}; echo var=$var str=$str expr=$expr var=expr str=expr expr=EXPR # var=${str:=expr}; echo var=$var str=$str expr=$expr var=expr str=expr expr=EXPR # str= # var=${str=expr}; echo var=$var str=$str expr=$expr var= str= expr=EXPR # var=${str:=expr}; echo var=$var str=$str expr=$expr var=expr str=expr expr=EXPR # str=STR # var=${str=expr }; echo var=$var str=$str expr=$expr var=STR str=STR expr=EXPR # var=${str:=expr}; echo var=$var str=$str expr=$expr var= STR str=STR expr=EXPR # MYSTRING=test # echo ${MYSTRING?string not set\!} test # MYSTRING= #echo ${MYSTRING?string not set\!} # unset MYSTRING # echo ${MYSTRING?string not set\!} bash: MYSTRING: string not set! |
请记住这些变数的习性﹐日后您要写shell script的时候就不会将变数搞混乱了。假如您想看看当前shell的环境变数有哪些﹐您可以输入set命令﹔如果只想检查export出来的变数﹐可以输入export或env (前者是shell预设的输出变数)。
Bash 设定
到这里﹐您或许会问﹕shell 的环境变数在哪里定义呢﹖ 可以调整吗﹖
嗯﹐第一个问题我不大了解﹐我猜那是shell 设计者预设定义好的﹐我们一登录获得shell 之后就有了。不过﹐第二个问题﹐我却可以肯定答复您﹕您可以随时调整您的环境变数。您可以在进入shell 之后用在命令行里面重新定义﹐也可以透过一些shell 设定档来设定。
先让我们看看﹐当您在进行登录的时候﹐系统会检查哪些档案吧﹕
- /etc/profile﹕首先﹐系统会检查这个档﹐以定义如下这些变数﹕PATH﹑USER﹑LOGNAME﹑MAIL﹑HOSTNAME﹑HISTSIZE﹑INPUTRC。如果您会shell script (我们后面再讨论)﹐那您应该看得出这些变数是如何定义的。另外﹐还指定了umask和ulimit的设定﹕umask大家应该知道了﹐而ulmimit呢﹖ 它是用来限制一个shell做能建立的行程数目﹐以避免系统资源被无限制的消耗。最后﹐它还会检查并执行/etc/profile.d/*.sh那些script﹐有兴趣您可以追踪看看。
- ~/.bash_profile﹕这里会定义好USERNAME﹑BASH_ENV﹑PATH。其中的PATH除了现有的$PATH之外﹐还会再加入使用者相关的路径﹐您会发现root和普通帐号的路径是不一样的﹔而BASH_ENV呢﹐仔细点看﹐是下一个要检查的档案﹕
- ~/.bashrc﹕在这个档里面﹐您可以发现一些alias设定(哦~~原来在这里﹗)。然后﹐您会发现有一行﹕ . /etc/bashrc。在shell script中﹐用一个小数点然后然后一个空白键再指向另外一个script﹐意思是同时执行那个script并采用那里的变数设定。
- /etc/bashrc﹕基本上﹐这里的设定﹐是所有使用者在获得shell的时候都会采用的。这里指定了一些terminal设定﹐以及shell提示字符等等。
- ~/.bash_login﹕如果~/.bash_profile不存在﹐则使用这个档。
- ~/.profile﹕如果~/.bash_profile和~/.bash_login都不存在﹐则使用这个档。
- ~/.bash_logout﹕这个档通常只有一个命令﹕ clear ﹐也就是把荧幕显示的内容清掉。如果您想要在登出shell的时候﹐会执行一些动作﹐例如﹕清空临时档(假如您有使用到临时档)﹑还原某些设定﹑或是执行某些备份之类的。
您可以透过修改上面提到的档案﹐来调整您进入shell之后的变数值。一般使用者可以修改其家目录( ~/ )中的档案﹐以进行个人化的设定﹔而作为root﹐您可以修改/etc/下面的档案﹐设定大家共用的变数值。至于bash的变数值如何设定﹖ 有哪些变数﹖ 各变数的功能如何﹖ 您打可以执行man bash参考手册资料。
Tips﹕ 一旦您修改了/etc/profile或~/.bash_profile档案﹐其新设定要在下次登录的时候才生效。如果您不想退出﹐又想使用新设定﹐那可以用 source 命令来抓取﹕
| source ~/.bash_profile |
命令重导向
好了﹐相信您已经对您的shell有一定的了解了。然后﹐让我们看看shell上面的一些命令功能吧﹐这些技巧都是作为一个系统管理员基本要素。其中之一就是﹕ 命令重导向 (command redirection)和命令管线(command pipe) 。
在深入讲解这两个技巧之前﹐先让我们了解一下shell 命令的基本概念﹕
| 名称 | 代号 | 代表意思 | 设备 |
| STDIN | 0 | 标准输入 | 键盘 |
| STDOUT | 1 | 标准输出 | 荧幕 |
| STDERR | 2 | 标准错误 | 荧幕 |
表格中分别是我们在shell 中一个命令的标准I/O (输出与输入)。当我们执行一个命令的时候﹐先读入输入(STDIN)﹐然后进行处理﹐最后将结果进行输出(STDOUT)﹔如果处理过程中遇到错误﹐那么命令也会显示错误(STDERR)。我们可以很容易发现﹕一般的标准输入﹐都是从我们的键盘读取﹔而标准输出和标准错误﹐都从我们的银幕显示。
同时﹐在系统上﹐我们通常用号码来代表各不同的I/O﹕STDIN 是0﹑STDOUT 是1﹑STDERR 是2。
当您了解各个I/O 的意思和所代表号码之后﹐让我们看比较如下命令的结果﹕
| # ls mbox mbox # ls mbox 1> file.stdout # |
请小心看第二个命令﹕在命令的后面多了一个1 ﹐而紧接着(没有空白﹗)是一个大于符号( > )﹐然后是另外一个档案名称。但是﹐荧幕上却没有显示命令的执行结果﹐也就是说﹕ STDOUT不见了﹗ 那到底发生什么事情了呢﹖
呵﹐相信您不会这么快忘记了STDOUT 的代号是1 吧﹗ 没错了﹐因为我们这里将1 用一个> 符号重导到一个档案中了。结果过是﹕我们将标准输出从荧幕改变到档案中﹐所以我们在银幕就看不到STDOUT﹐而原先的STDOUT 结果则保存在大于符号右边的档中了。不信﹐您看看这个档案的内容就知道了﹕
| # cat file.stdout mbox |
当我们用一个>将命令的STDOUT导向到一个档案的时候﹐如果档案不存在﹐则会建立一个新档﹔如果档案已经存在﹐那么﹐这个档案的内容就换成STDOUT的结果。有时候﹐您或许想保留原有档案的内容﹐而将结果增加在档案末端而已。那您可以多加一个>﹐也就是使用>>就是了。您可以自己玩玩看哦~~﹐通常﹐我们要将一些命令或错误记录下来﹐都用这个方法。
Tips﹕ 如果您不希望>意外的盖掉一个原有档﹐那您可以执行这个命令﹕
| set -o noclobber |
不过﹐仍可以用>|来强迫写入。
上前面的例子中﹐我们指定了I/O 1 (STDOUT) 进行重导向﹐这也是预设值﹐如果您没有指定代号﹐那么就是进行STDOUT 的重导向﹐所以1> 和> 是一样的﹔1 >> 和>> 也是一样的。但如果您使用了数字﹐那么数字和> 之间一定不能有空白存在。
好了﹐下面再比较两个命令﹕
| # ls no_mbox ls: no_mbox: No such file or directory # ls no_mbox 2>> file.stderr |
嗯﹐相信不用我多解释了吧﹖ (如果档案不存在﹐>> 和> 都会建立新的。)
事实上﹐在我们的日常管理中﹐重导向的应用是非常普遍的。我只举下面这个例子就好了﹕
当我们进行核心编译的时候(我们下一章再介绍)﹐荧幕会飞快的显示出成千上万行信息﹔其中有大部份是STDOUT﹐但也有些是STDERR。除非您的眼睛真的那么厉害﹐否则您很难分辩出哪些是正常信息﹐哪些是错误信息。当您要编译失败﹐尝试找错误的时候﹐如果已经将STDERR 重导出来﹐就非常方便了﹕
| # make dep clean bzImage modules 1>/dev/null 2>/tmp/kernel.err & |
这里﹐我一共有三个打算﹕(1) 将标准输出送到一个叫null 的设备上﹐如果您记性够好﹐我在前面的文章中曾比喻它为黑洞﹕所有东西进去之后都会消失掉。凭我个人的习惯﹐我会觉得编译核心时跑出来的信息﹐如果您不感兴趣的话﹐那都是垃圾﹐所以我将STDOUT 给重导到null 去﹐眼不见为干净﹔ (2) 然后﹐我将STDERR 重导到/tmp/kernel.err 这个档去﹐等命令结束后﹐我就可以到那里看看究竟有部份有问题。有些问题可能不是很重要﹐有些则可能需要重新再编核心﹐看您经验啦。(3) 最后﹐我将命令送到background 中执行(呵~~ 相信您还没忘记吧﹗)。因为﹐编译核心都比较花时间﹐所以我将之送到背景去﹐这样我可以继续做其它事情。
Tips﹕ 这时﹐因为系统太忙了﹐可能反应速度上会比较慢些﹐如果您真的很在意﹐不妨考虑把make的nice level提高。(忘记怎么做了﹖那翻看前一章吧)
前面的例子﹐我们是分开将STDOUT 和STDERR 重导到不同的档案去﹐那么﹐我们能否把两者都重导到同一个档呢﹖ 当然是可以的﹐请比较下面三行﹕
| # make dep clean bzImage modules >/tmp/kernel.result 2>/tmp/kernel.result # make dep clean bzImage modules >/tmp/kernel.result 2>&1 # make dep clean bzImage modules &>/tmp/kernel. resultt |
我这里告诉您﹕第一行的命令不怎么正确﹐因为这样会造成这两个输出同时在'抢'一个档案﹐写入的顺序很难控制。而第2 行和第3 行的结果都是一样的﹐看您喜欢用哪个格式了。不过﹐要小心的是﹕& 符号后面不能有空白键﹐否则会当成将命令送到背景执行﹐而不是将STDOUT 和STDERR 整合。
好了﹐前面我们都在谈STDOUT 和STDERR 的重导向﹐那么﹐我们是否能重导STDIN 呢﹖
当然可以啦~~~
有些命令﹐当我们执行之后﹐它会停在那里等待键盘的STDIN输入﹐直到遇到EOF (Ctrl+D)标签才会真正结束命令。比方说﹐在同一个系统上﹐如果有多位使用者同时登入的话﹐您可以用write命令向特的使用者送出短讯。而短讯的内容就是键盘敲入的文字﹐这时候命令会进入输入模式﹐您每输入一行并按Enter之后﹐那么讯息就会在另外一端﹐直到您按Ctrl+D键才离开并结束命令。
| # write user1 Hello! It is me... ^_^ How ru! (Ctrl+D) |
这样通常都需要花一些时间输入﹐假如对方在写什么东西和查看某些资料的时候﹐就很混乱。这时候﹐您或许可以先将短讯的内容写在一个档案里面﹐例如greeting.msg﹐然后这样输入就可以了﹕
| write user1 < greeting.msg |
就这样﹐这里我们用小于符号( < )来重导STDIN 。简单吧﹖ ^_^
不过﹐我们用cat 命令建立简单的档案的时候﹐却是使用> 符号的﹕
| cat > file.tmp
等您按Ctrl+D 之后﹐从键盘输入的STDIN﹐就保存在file.tmp 中了。请想想看为什么会如此﹖ (我在LPI 的考试中碰到过这道题目哦~~~) |
pipe
查字典﹐pipe 这个英文是水管﹑管道﹑管线的意思。那么﹐它和命令又有什么牵连呢﹖ 简单的说﹐一个命令管线﹐就是将一个命令的STDOUT 作为另一个命令的STDIN 。
其实﹐这样的例子我们前面已经碰到多次了﹐例如上一章介绍tr 命令的时候﹕
| # cat /path/to/old_file | tr -d '\r' > /path/to/new_file |
上面这个命令行﹐事实上有两个命令﹕cat 和tr ﹐在这两个命令之间﹐我们用一个“ | ”符号作为这两个命令的管线﹐也就是将cat 命令的STDOUT 作为tr 命令的STDIN ﹔然后﹐tr 命令的STDOUT 用> 重导到另外一个档案去。
上面只是一个非常简单的例子而已﹐事实上﹐我们可以用多个管线连接多个程式﹐最终获得我们确切想要的结果。比方说﹕我想知道目前有多少人登录在系统上面﹕
| # w | tail +3 | wc -l |
我们不妨解读一下这个命令行﹕(1) w 命令会显示出当前登录者的资源使用情况﹐并且每一个登录者占一行﹔(2) 再用tail 命令抓取第3 行开始的字行﹔( 3) 然后用wc -l 计算出行数。这样﹐就可以知道当前的登录人数了。
许多朋友目前都采用拨接ADSL 上网﹐每次连线的IP 都未必一样﹐只要透过简单的命令管线﹐您就可以将当前的IP 抓出来了﹕
- 我们不妨观察ifconfig ppp0 这个命令的输出结果﹕
# ifconfig ppp0 ppp0 Link encap:Point-to-Point Protocol inet addr:211.74.48.254 PtP:211.74.48.1 Mask:255.255.255.255 UP POINTOPOINT RUNNING NOARP MULTICAST MTU:1492 Metric:1 RX packets:5 errors:0 dropped:0 overruns:0 frame:0 TX packets:3 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:3
- 不难发现IP 位址所在的句子中有着其它句子所没有的字眼﹕inet addr 。然后﹐我们就可用grep 把这行抓出来﹕
# ifconfig ppp0 | grep "inet addr" inet addr:211.74.48.254 PtP:211.74.48.1 Mask:255.255.255.255
- 再来﹐我们先用相同的分隔符号将句子分成数列﹐然后抓出IP 位址所在的那列。
嗯﹐这里﹐我们可以用“ : ”来分出4 列﹔也可以用空白键来分出5 列(空因为句子开首就是一个空白键)。如果用空白键来分的话﹐由于有些间隔有多个空白键的原因﹐那么﹐我们可以用tr 命令﹐将多个空白键集合成一个空白键﹕
(注意﹕在' ' 之间是一个空白键﹗)# ifconfig ppp0 | grep "inet addr" | tr -s ' ' ' ' inet addr:211.74.48.254 PtP:211.74.48.1 Mask:255.255.255.255
- 然后用cut 命令抓出IP 所在的列﹐细心数一数﹐应该是第3 列﹕
# ifconfig ppp0 | grep "inet addr" | tr -s ' ' ' ' | cut -d ' ' -f3 addr:211.74.48.254
- 然后我们用“ : ”再分两列﹐抓第2 列就是IP 了﹕
# ifconfig ppp0 | grep "inet addr" | tr -s ' ' ' ' \ | cut -d ' ' -f3 | cut -d ':' -f2 211.74.48.254
这里﹐我们一共用5 个pipe 将4 个命令连接起来﹐就抓出机器当前的IP 位址了。是否很好用呢﹖
在同一个命令行里面出现多个命令的情形﹐除了“ | ”之外﹐或许您会看到" ` ` " 符号﹐也就是和~ 键同一个键的符号(不用按Shift )。它必须是一对使用的﹐其中可以包括单一命令﹐或命令管线。那它的效果和命令管线又有什么分别呢﹖
我们使用pipe 将一个命令的STDOUT 传给下一个命令的STDIN﹐但使用`` 的时候﹐它所产生的STDOUT 或STDERR 仅作为命令行中的一个参数而已。嗯﹐不如看看下面命令好了﹕
| # TODAY=`date +%D` # echo Today is $TODAY. Today is 08/17/01. |
从结果我们可以看出﹐我们用`` 将date 这个命令括起来(可含参数)﹐那么它的执行结果可以作为TODAY 的变数值。我们甚至还可以将一串命令管线直接用在命令行上面﹕
| # echo My IP is `ifconfig ppp0 | grep "inet addr" \ | tr -s ' ' ' ' | cut -d ' ' -f3 | cut -d ':' -f2` My IP is 211.74.48.254. |
注意﹕第一行的CR 被\ 跳脱了﹐所以这个命令行'看起来'有两行。我之所以弄这么复杂﹐是告诉您这对`` 符号可以适用的范围。
Tips﹕ 在变数中使用``可以将命令的执行结果当成变数值的部份。事实上﹐除了用``之外﹐您也可以用这样的格式﹕ VAR_NAME=$(command) ﹐那是和VAR_NAME=`command`的结果是一样的。
除了这对`` 和| 之外﹐还有另外一个符号“ ; ”来分隔命令的。不过﹐这个比较简单﹕就是当第一命令结束之后﹐再执行第二个命令﹐如此类推﹕
| # ./configure; make; make install |
呵~~ 如果您对您的安装程式有绝对信心﹐用上面一行命令就够了﹗
Shell Script
当我们对shell 变数和命令行有一定认识之后﹐那么﹐我们就可以尝试写自己的shell script 啰~~ 这可是非常好玩而又有成就感的事情呢﹗ ^_^
在linux 里面的shell script 可真是无处不在﹕我们开机执行的run level 基本上都是一些script ﹔登录之后的环境设定﹐也是些script ﹔甚至工作排程和记录维护也都是script 。您不妨随便到/etc/rc.d/init.d 里面抓两个程式回来看看﹐不难发现它们都有一个共同的之处﹕第一行一定是如下这样的﹕
#!/bin/sh 或﹕ #!/bin/bash |
其实﹐这里的#! 后面要定义的就是命令的解释器(command interpreter)﹐如果是/bin/bash 的话﹐那下面的句子就都用bash 来解释﹔如果是/usr/bin/perl 的话﹐那就用perl 来解释。不同的解释器所使用的句子语法都不一样﹐非常严格﹐就算同是用shell 来解释﹐不同的shell 之间的格式也不仅相同。所以﹐如果您看到script 的解释器是/bin/sh 的话﹐那就要小心了﹕如果您仔细看这个档案﹐事实上它仅是一个link 而已﹐有些系统或许会将它link 到其它shell 去。假如您的script 句子使用的语法是bash 的话﹐而这个sh 却link 到csh ﹐那执行起来可能会有问题。所以﹐最好还是直接指定shell 的路径比较安全一些﹕在这里的范例都使用/bin/bash 来作为script 的解释器。
在真正开始写script 之前﹐先让我们认识script 的一些基本概念﹕
简单来说﹐shell script 里面就是一连串命令行而已﹐再加上条件判断﹑流程控制﹑回圈﹑等技巧﹐聪明地执行正确的命令和使用正确的参数选项。和我们在shell 里面输入命令一样﹐shell script 也有这样的特性﹕
- 当读到一个CR 字符的时候﹐就尝试执行该行命令﹔
- 它会忽略空白行﹔句子前面的空白和tab 也不理会﹔
- CR 字符也同样可以用“ \ ”符号跳脱﹔
- 另外﹐“ # ”符号是注解符号﹐从这个符号至句子末端的内容全被忽略﹐程式本身不会读入这部份﹐但我们经常用来给使用者阅读﹐因而名为注解﹔
- 等等。
一个良好的script 作者﹐在程式开头的时候﹐都会用注解说明script 的名称﹑用途﹑作者﹑日期﹑版本﹑等信息。如果您有这个机会写自己的script﹐也应该有这个良好习惯。
shell script档的命名没一定规则﹐可以使用任何档案名称(参考档案系统)﹐但如果您喜欢的话﹐可以用.sh来做它的副档名﹐不过这不是硬性规定的。不过﹐要执行一个shell script﹐使用者必须对它有执行权限( x )﹐用文件编辑器新建立的档案都是没有x permission的﹐请用chmod命令加上。执行的时候﹐除非该script已经至于PATH环境变数之内的路径内﹐否则您必须指定路径。例如﹐您写了一个叫test.sh的shell script﹐放在家目录内﹐假设这也是您的当前工作目录﹐您必须加上路径才能执行﹕./test.sh或~/test.sh 。所以﹐建议您在script测试无误之后﹐放在~/bin目录里面﹐那就可以在任何地方执行自己的script了﹐当然﹐您要确定~/bin已经出现在您的PATH变数里面。
script之所以聪明﹐在于它能够对一些条件进行测试( test )。您可以直接用test命令﹐也可以用if叙述﹐例如﹕test -f ~/test.sh 。它的意思是测试一下~/test.sh这个档案是否存在﹐这个-f通常用在档案上面的测试﹐除了它﹐还有很多﹕
| 标签 | 代表意思 |
| -G | 存在﹐并且由GID 所执行的行程所拥有。 |
| -L | 存在﹐并且是symbolic link 。 |
| -O | 存在﹐并且由UID 所执行的行程所拥有。 |
| -S | 存在﹐并且是一个socke 。 |
| -b | 存在﹐并且是block 档案﹐例如磁碟等。 |
| -c | 存在﹐并且是character 档案﹐例如终端或磁带机。 |
| -d | 存在﹐并且是一个目录。 |
| -e | 存在。 |
| -f | 存在﹐并且是一个档案。 |
| -g | 存在﹐并且有SGID 属性。 |
| -k | 存在﹐并且有sticky bit 属性。 |
| -p | 存在﹐并且是用于行程间传送资讯的name pipe 或是FIFO。 |
| -r | 存在﹐并且是可读的。 |
| -s | 存在﹐并且体积大于0 (非空档)。 |
| -u | 存在﹐并且有SUID 属性。 |
| -w | 存在﹐并且可写入。 |
| -x | 存在﹐并且可执行。 |
事实上﹐关于这些测试项目还有很多很多﹐您可以man bash 然后参考CONDITIONAL EXPRESSIONS 那部份。另外﹐我们还可以同时对两个档案进行测试﹐例如﹕test file1 -nt file2 就是测试file1 是否比file2 要新。这种测试使用的标签是﹕
| 标签 | 代表意思 |
| -nt | Newer Than﹕第一个档案比第二个档案要新。 |
| -ot | Older Than﹕第一个档案比第二个档案要旧。 |
| -ef | Equal File﹕第一个档案和第二个档案其实都是同一个档案(如link)。 |
我们这里所说的这些测试﹐不单只用来测试档案﹐而且还常会用来比对' 字串(string) '或数字(整数)。那什么是字串呢﹖ 字面来介绍就是一串文字嘛。在一个测试中﹐~/test.sh本身是一个档案﹔但'~/test.sh' ﹐则是在引号里面(单引号或双引号)﹐那就是字串了。
在数字和字串上面的比对(或测试)﹐所使用的标签大约有﹕
| 标签 | 代表意思 |
| = | 等于 |
| != | 不等于 |
| < | 小于 |
| > | 大于 |
| -eq | 等于 |
| -ne | 不等于 |
| -lt | 小于 |
| -gt | 大于 |
| -le | 小于或等于 |
| -ge | 大于或等于 |
| -a | 双方都成立 |
| -o | 单方成立 |
| -z | 空字串 |
| -n | 非空字串 |
在上面提到的比对中﹐虽然有些意思一样﹐但使用场合却不尽相同。例如= 和-eq 都是'等于'的意思﹐但= 只能比对字串﹐而-eq 则可以用来比对字串﹐也能用来比对表示色样(我们在regular expression 会碰到)。
我们之所以要进行测试或比对﹐主要是用来做判断的﹕假如测试或比对成立﹐那就返回一个' 真实(true)'否则返回' 虚假(false) '。也就是说﹕如果条件成立那么就会如何如何﹔如果条件不成立又会如何如何﹐从而让script有所'智慧'。基本上﹐我们的程式之所以那么聪明﹐都是从这些简单到复杂的判断开始的。
比方说﹐上面的-a (AND) 和-o (OR) 是用来测试两个条件﹕A 和B 。如果使用test A -a B ﹐那么A 和B 都必须成立那条件才成立﹔如果使用test A -o B ﹐那么只要A 或B 成立那条件就成立。至于其它的比对和测试﹐应该更好理解吧﹖
另外﹐还有一个特殊符号﹕“ ! ”您可不能不会运用。它是'否'的意思﹐例如﹕"! -f"是非档案﹔ "-ne"和"! -eq"都是'不等于'的意思。
我们在命令行上面已经知道如何定义和改变一个变数﹐那在shell script 里面就更是司空见惯了。而且﹐越会利用变数﹐您的script 能力就越高。在shell script 中所定义的变数有更严格的定义﹕
| 标签 | 代表意思 |
| -a | 定义为阵列(array) 变数 |
| -f | 仅定义功(function) 能名称。 |
| -i | 定义为整数。 |
| -r | 定义为唯独变数。 |
| -x | 透过环境输出变数。 |
我们除了用“ = ”来定义变数之外﹐还可以用declare命令来明确定义变数。例如﹕
| # A=3 B="-2" # RESULT=$A*$B # echo $RESULT 3*-2 # declare -i A=3 B="-2" # declare -i RESULT=$A*$B # echo $RESULT -6 |
您这里会发现﹕如果没有使用declare 命令将变数定义为整数的话﹐那么A 和B 的变数值都只是字串而已。
您现在已经知道什么是变数﹑如何定义变数﹑什么是字串﹑如何比对和测试字串和档案﹐这些都是script 的基本技巧。写一些简单的script 应该不成问题了﹐例如在家目录写一个test.sh ﹐其内容如下﹕
1 #!/bin/bash 2 # Purpose: a simple test shell script. 3 # Author: netman <[email protected]> 4 # Date: 2001/08/17 5 # Version: 0.01 6 7 CHK_FILE=~/tmp/test.sh 8 9 if [ ! -e $CHK_FILE ] 10 then 11 echo "$0: Error: '$CHK_FILE' is not found." ; exit 1 12 13 elif [ -d $CHK_FILE ]; then 14 echo -n "$CHK_FILE is a directory, and you can " 15 test -x $CHK_FILE || echo -n "NOT " 16 echo "search it." 17 exit 2 18 19 elif [ -f $CHK_FILE ]; then 20 echo "$CHK_FILE is a regular file." 21 test -r $CHK_FILE && echo "You can read it." 22 test -x $CHK_FILE && echo "You can execute it." 23 test -w $CHK_FILE && echo "You can write to it." 24 test -s $CHK_FILE || echo "However, it is empty." 25 exit 0 26 27 else 28 echo "$CHK_FILE is a special file." 29 exit 3 30 31 fi |
先让我们看第一行﹕#!/bin/bash﹐就是定义出bash 是这个script 的command interpreter 。
然后是一些注解﹐说明了这个script 的用途﹑作者﹑日期﹑版本﹐等资讯。
在注解之后﹐第7 行才是script 的真正开始﹕首先定义出一个变数CHK_FILE ﹐目前内容是家目录中tmp 子目录的test.sh 档案。
Tips﹕ 事实上﹐这个定义比较有局限﹐如果您想改良这个设计﹐可以将这行(第7行)换成下面数行﹕
if [ -z $1 ] then echo "Syntax Erro! Usage: $0 <file_path>" ; exit 5 else CHK_FILE=$1 fi |
第一行是开始一个if 的判断命令﹐它一定要用一个fi 命令来结束(您可以在最后一行找到它)﹔然后在if 和fi 之间必须有一个then 命令。这是典型的if-then-fi 逻辑判断﹕如果某某条件成立﹐然后如何如何﹔还有if-then-else-fi 判断﹕如果某某条件成立﹐然后如何如何﹐否则如何如何﹔另外﹐也有if-then-elif-then-else-fi 判断﹕如果某某成立﹐然后如何如何﹔否则﹐再如果某某成立﹐然后如何如何﹔如果还是不成立﹐那就如何如何。
上面那几行﹐主要目的是将CHK_FILE这个变数值定义为$1。嗯﹖ 您或许会问$1是什么啊﹖ 那是当您执行这个script的时候所输入的第一个参数 ﹔而$0则是script 命令行本身。所以﹐这里是先判断一下$1是否为空的( -z )﹐然则(then)﹐告诉您语法错误﹐并告诉您正确的格式﹐同时退出﹐并返回一个状态值(后面再谈)﹔否则( else)﹐就将CHK_FILE定义为$1。
接下来第9 行﹐您可以将"if [ ! -e $CHK_FILE ]" 换成"if test ! -e $CHK_FILE " ﹐意思都是一个测试。但如果用[ ] 的话有一个地方要注意﹕"[ " 的右边必须保留一个空白﹔" ]" 的左边必须保留一个空白。
在目前这个script 中﹐判断逻辑如下﹕
- 先检查$CHK_FILE (也就是~/tmp/test.sh这个档)是否不存在( ! -e )﹐如果( if )条件成立﹐那就参考then里面的命令﹔否则参考下面elif或else。
- 如果上一步骤成立﹐也就是~/tmp/test.sh不存在﹐然则用echo命令告诉您不能读取这个档﹐并同时返回父程式一个返回状态 (还记得我们在前面提到过的$?变数吗﹖)﹐这里为1。在script中﹐任何时候执行exit的话﹐就会离开script﹐不管后面是否还有其它命令行或判断。因为我将这里echo和exit写在同一行﹐所以用一个" ; "符号分隔开来﹐否则﹐您可以将exit写在下一行。
- 接下来( 13 行)是一个elif ﹐就是else if 的意思﹐也就是说﹕如果上一个if 不成立﹐然后在这里再做另外一个if 测试。这里是继续检查这个档是否为一个目录( -d )﹐然则﹐告您它是一个目录﹐并同时尝试告诉您是否能对这个目录进行搜索。
然后看看下一行( 15 行)动内容﹐请留意上一个echo 和这个echo﹐都带有一个-n 的参数﹐意思是在显示信息的时候不进行断行( newline )的动作﹐所以﹐和下面那行合在一起(共3 行script )才是真实显示的内容。这里再进行一个测试﹕看看您对这个目录是否具有-x 权限﹐否则会在"and you can" 和"search it." 之间加上一个"NOT"﹐如果有权限就不出现这个NOT 。
这里﹐我们没有用if-then来判断﹐而是直接用“ || ” ( OR )来做判断﹕非此即彼。这在一些简单的判断中非常好用﹐尤其对懒人来说﹐因为不用打太多的字﹔但功能就比较有限﹕判断之后只能执行一个命令而已。除了||之外﹐您也可以用“ && ”( AND )做判断﹐套句Jack的名言﹕You jump I jump。所以﹐这句也可以换成﹕
test ! -x $CHK_FILE && echo -n "NOT " (粗体字是修改部份)。最后﹐根据目前这个elif 条件所进行的所有命令都执行完毕﹐并退出这个script﹐同时设定返回状态为2 。
- 再下来( 19 行)是另一个elif ﹐也就是说﹕如果连上一个elif 也不成立的话﹐那这里继续检查这个档是否是一个常规档案( -f )﹐然则﹐告诉您是一个常规档案﹐然后﹐接连进行三个测试﹐分别测试您是否具有-r﹑-x﹑-w 的权限﹐有的话﹐分别告诉您相关的可行性。最后还检查这个档案的长度是否超过0 ( -s )﹐否则告诉您它是一个空档。完成这些判断之后﹐就退出script﹐并返回一个为0 的状态。
- 然后( 27 行)是一个else﹐意思是如果上面的所有if 和elif 都不成立﹐那就看这里的。也就是说﹕这个档案是存在的﹐但不是目录﹐也不是常规档案﹐那它就是一个特殊档。然后退出script﹐并设定返回状态为3。
在这个范例中﹐script 一共有0﹑1﹑2﹑3 这四个返回状态﹐根据这个返回值( $? )﹐我们就可以得知检查的档案究竟是一个常规档﹑还是不存在﹑还是目录﹑还是特殊档。
- 最后﹐再没有其它动作了﹐就结束这个if 判断。
目前这个script 仅提供一些script 概念给您而已﹐例如﹕定义和使用变数﹑if-then-else-fi 判断式﹑条件测试﹑逻辑关系﹑退出状态﹑等等。同时﹐这个范例也提供了一些基本的script 书写惯例﹕用不同的缩排来书写不同的判断或回圈。例如这里一共有两个if-then-else-fi 判断﹐第一个if﹑then﹑else﹑fi 都没有缩排﹐然后﹐紧接这些命令后面的叙述就进行缩排﹔当碰到第二层的if-then-else-fi 的时候﹐也如此类推。事实上﹐并非一定如此写法﹐但日后如果您的程式越写越长﹐您自然会这样安排的啦~~
刚才我们认识了一个if-then-else-fi 的判断﹐事实上﹐在script 的应用上﹐还有其它的许多判断技巧﹐在我们开发更强大和复杂的script 之前﹐不妨先认识一下﹕
- case
-
格式﹕
case string in pattern ) commands ;; esac
它能根据不同的字串来做相应的动作﹐不如用例子来说好了﹕
1 #!/bin/bash 2 # Purpose: a simple test shell script. 3 # Author: netman <[email protected]> 4 # Date: 2001/08/20 5 # Version: 0.02 6 7 8 echo Please pick a number: 9 echo " "a, To show the local time. 10 echo " "b, To list current directory. 11 echo " "c, To see who is on the machine. 12 echo -n "Your choice: " 13 14 read choice 15 16 case $choice in 17 a | A) echo -n "The local time is " 18 date ;; 19 b | B) echo "The current directory is $PWD " ;; 20 c | C) echo "There are following users on the machine:" 21 who ;; 22 *) echo "Your choice is an invalid option." ;; 23 esac
这个script 是先请您选择a﹑b﹑c 字母﹐再用read 命令从键盘读入choice 的变数值﹐然后将这个变数应用在case 判断中﹕
- 如果是a 或A﹕执行date 命令﹔
- 如果是b 或B﹕用$PWD 这个环境变数显示当前目录﹔
- 如果是c 或C﹕则执行who 命令﹔
- 如果是其它( * ) ﹕则告诉您invalid 。
不知道您是否有注意到﹕每一个case 的选项﹐都用一个" ) " 作指引﹐然后﹐在这个case 最后一个命令完成以后﹐一定要用" ;; " 来结束。最后﹐还必须用case 的倒写esac 来关闭这个判断。
- for
-
格式﹕
for item in list do commands done
当您需要重复处理一些事物的时候﹐for 回圈就非常好用了。它通常用来重复处理一些列表( list ) 中的事物﹐比方说您有一个变数﹐里面包含着一串列表﹐那么回圈会一个接一个的进行处理﹐直到最后一个处理完毕之后才退出。不如又用一个范例来说明好了﹕
1 #!/bin/bash 2 # Purpose: a simple test shell script. 3 # Author: netman <[email protected]> 4 # Date: 2001/08/21 5 # Version: 0.03 6 7 8 if [ -z "$1" ] || [ -z "$2" ] ; then 9 echo "Syntax Error: Usage ${0##*/} <word to search> <target dir>" 10 exit 1 11 fi 12 if [ ! -d $2 ]; then 13 echo "${0##*/} : Error: $2 is not a directory." 14 exit 2 15 fi 16 TWORD="$1" 17 TDIR="$2" 18 TFILE=`grep -r "$TWORD" "$TDIR" | cut -d ':' -f1 | uniq` 19 20 if [ ! -z "$TFILE" ]; then 21 echo "You can find $TWORD in following file(s):" 22 for i in $TFILE ; do 23 echo $i 24 done 25 exit 0 26 else 27 echo "Could not find $TWORD in any file under $TDIR." 28 exit 3 29 fi
这个script 是在一个目录下面搜索档案﹐如果档案里面发现有指定的文字﹐就将档案的名称列出来。它必须要抓两个变数﹕TWORD 和TDIR ﹐这两个变数分别为script 的第1 个和第2 个参数。
一开始要检查命令行是否有两个变数﹐用-z $1 和-z $1 来测试﹐如果它们其一没有指定﹐就告诉您语法错误﹐同时退出(返回值为1 ) 。然后再检查$2 是否为目录﹐如果不是目录﹐就也提出警告﹐并退出(返回值为2 )。如果通过上面两道检查﹐然后用命令grep﹑cut﹑uniq﹐将档案抓出来。注意﹕这就是for 回圈需要检查的列表。
然后会检查列表是否有内容﹐如果有的话﹐那就用for 回圈来重复显示列表里面的所有项目﹔一次一个﹐直到列表最后一个项目也处理完毕。这就是一个for 回圈的基本运作方式了。如果列表没有被建立起来﹐那就告诉您找不到您指定的文字﹐并退出(返回值为3 )。
- while
-
格式﹕
while condition do commands done
这个回圈应该蛮容易理解的﹕当条件成立的时候﹐就一直重复﹐直到条件消失为止。我们不妨改良前面的case 那个script 看看﹕
1 #!/bin/bash 2 # Purpose: a simple test shell script. 3 # Author: netman <[email protected]> 4 # Date: 2001/08/21 5 # Version: 0.02.1 6 7 8 while [ "$choice" != "x" ]; do 9 echo 10 echo Please pick a number: 11 echo " "a, To show the local time. 12 echo " "b, To list current directory. 13 echo " "c, To see who is on the machine. 14 echo " "x, To exit. 15 echo -n "Your choice: " 16 17 read choice 18 echo 19 20 case $choice in 21 a) echo -n "The local time is " 22 date ;; 23 b) echo "The current directory is $PWD ";; 24 c) echo "There are following users on the machine:" 25 who ;; 26 x) echo "Bye bye..."; exit 0 ;; 27 *) echo "Your choice is an invalid option." ;; 28 esac 29 done
首先﹐我们用while 进行应该条件判断﹕如果$choice 的变数值不等于x 的话﹐那就重复回圈﹐直到遇到x (条件消失)为止。那么这个script 会一直提示您键入选项﹐然后进行处理﹐直到您按x 键才会结束。
- until
-
格式﹕
until condition do commands done
这个until 刚好和while 相反﹕如果条件不成立就一直重复回圈﹐直到条件成立为止。如果继续引用上例﹐只需将while 的条件设为相反就可以了﹕
修改前﹕ 8 while [ "$choice" != "x" ]; do 修改后﹕ 8 until [ "$choice" = "x" ]; do
没错﹕就是这么简单﹗
- sub function
-
格式﹕
function function_name { commands } 或﹕ function_name () { commands }
当您在一个script 中﹐写好了段可以用来处理特定条件的程式之后﹐或许后面会重复用到。当然﹐您可以重复写这些句子﹐但更便利的办法是﹕将这些重复性的句子做成sub function。如果您有模组的概念﹐那就是将一些能够共享的程式做成模组﹐然后提供给需要用到此功能的其它程式使用。说实在﹐看一个程式撰写人的模组化程度﹐也就能看得出这个人的程式功力。
我们不妨写一个script 来显示机器目前所使用的网路卡界面资讯﹐看看里面的sub function 是怎么运用的﹕
1 #!/bin/bash 2 # Purpose: a simple test shell script. 3 # Author: netman <[email protected]> 4 # Date: 2001/08/21 5 # Version: 0.04 6 7 8 # function 1: to get interface. 9 getif () { 10 until [ "$CHKIFOK" = "1" ] || [ "$GETNONE" = "1" ]; do 11 echo -n "The interface (ethX) for $CHKNET network [Enter for none]: " 12 read CHKIF 13 if [ -z "$CHKIF" ]; then 14 echo 15 echo "There is no interface for $CHKNET network." 16 echo 17 GETNONE=1 18 else 19 chkif # invoke the second function 20 fi 21 done 22 } 23 24 # function 2: to check interface. 25 chkif () { 26 TESTIF=`/sbin/ifconfig $CHKIF | grep "inet add"` 27 if [ -z "$TESTIF" ]; then 28 echo "" 29 echo "ERROR: Could not find interface '$CHKIF' on your machine!" 30 echo " Please make sure $CHKIF has been set up properly." 31 echo "" 32 return 1 33 else 34 CHKIFOK=1 35 getip # invoke the third function 36 return 0 37 fi 38 } 39 40 # function 3: to get ip. 41 getip () { 42 CHKIP=`ifconfig $CHKIF | grep "inet addr" | tr -s ' ' ' ' \ 43 | cut -d ' ' -f3 | cut -d ':' -f2` 44 CHKMASK=`ifconfig $CHKIF | grep "inet addr" | tr -s ' ' ' ' \ 45 | cut -d ' ' -f5 | cut -d ':' -f2` 46 echo 47 echo "The interface of $CHKNET network is $CHKIF using $CHKIP/$CHKMASK." 48 echo 49 return 0 50 } 51 52 # start of main body 53 for CHKNET in EXTERNAL INTERNAL DMZ ; do 54 getif # invoke the first function 55 unset GETNONE 56 unset CHKIFOK 57 done
在这个script 中﹐目前有三个sub function﹕
- getif ()﹕这里用until回圈从键盘那里读入指定的网路卡。如果直接按Enter表示没有界面﹐然则﹐回报一个信息﹐并将GETNONE变数设定为1 ﹐同时退出这个function﹔否则﹐执行下一个function 。
- chkif ()﹕当上一个function顺利读入网路卡名称之后﹐会检查这个界面是否存在。这里是用/sbin/ifconfig和grep来检查﹐如果命令结果抓不到IP位址﹐表示这张卡还没设定好﹐然则﹐回报一个错误信息﹐并退出function﹐返回状态为1 ﹔否则﹐执行下一个function﹐然后退出function﹐返回状态为0。
(注意﹕这里的function 有使用return 退出以及设定返回状态﹔但上一个function 没有使用retuen﹐是因为getif () 有使用until 回圈﹐如果那里用return 的话﹐就会打断until 回圈。)
- getip ()﹕当上一个function通过界面检测之后﹐就将界面的IP和netmask抓出来﹐同时告诉您相关的网路资讯﹐最后退出function﹐返回状态为0。
当所有sub function 都定义完毕之后﹐接下来就是main body 的开始。这里用一个for 回圈﹐分别对EXTERNAL﹑INTERNAL﹑和DMZ 网路进行检查﹐执行第一function 就开始一连串的动作了。因为sub function 里面的变数会重复使用﹐所以﹐在每次使用过其中的功能之后﹐要将某些影响下一个判断的变数清空﹐用unset 命令即可。
- getif ()﹕这里用until回圈从键盘那里读入指定的网路卡。如果直接按Enter表示没有界面﹐然则﹐回报一个信息﹐并将GETNONE变数设定为1 ﹐同时退出这个function﹔否则﹐执行下一个function 。
事实上﹐用在script 上面的回圈有非常多的变化﹐恐怕我也没此功力为大家一一介绍。还是留待您自己去慢慢摸索了。
Regular Expression
常规表示式(RE -- Regular Expression) 应该是所有学习程式的人员必须具备的基本功夫。虽然﹐我的程式能力很差﹐而且这里的文章也不是以程式为主﹐不过﹐在日后的管理生涯当中﹐如果会运用RE 的话﹐将令许多事情都时半功倍﹐同时也让您在管理过程中如虎添翼。下面﹐我们只接触最基本的RE 常识﹐至于进阶的技巧﹐将留给有兴趣的朋友自己发挥。
首先﹐不妨让我们认识最基本的RE 符号﹕
| 符号 | 代表意思 | 范例 |
| ^ | 句子前端 | "^dear" ﹕句子必须以dear 开头。 |
| $ | 句子末端 | "dear$"﹕句子必须以dear 结尾﹔"^$" ﹕空白行。 |
| \ | 跳脱字符 | "\\" ﹕\ 符号本身﹔"\." ﹕小数点﹔"\ " ﹕空白键。 |
| . | 任何单元字符 | ".ear" : 可以是dear, bear, tear﹐但不能是ear 。 |
| ? | 前一个RE 出现0 次或1 次 | "^[0-9]?$" ﹕ 空白行或只含1 个数字的字行。 |
| * | 前一个RE 可出现0 次或多次 | "^.*" ﹕所有字行﹔ "^[0-9][0-9]*$" ﹕ 含一或多个数字的字行。 |
| + | 前一个RE 可出现1 次或多次 | "^[0-9][0-9]+$" ﹕ 含两个或多个数字的字行。 |
| \{n\} | 接在前一字符的n 个相同范围字符 | "^[0-9]\{3\}[^0-9]" ﹕句子开头连续3 个数字﹐然后是一个非数字。 |
| \{n,\} | 接在前一字符的最少n 个相同范围的字符 | "^[0-9]\{3,\}" ﹕句子开头最少要有连续3 个数字。 |
| \{n,m\} | 接在前一字符的n 到m 个相同范围的字符 | "^[0-9]\{3,5\}" ﹕句子开头连续3 或5 个数字。 |
| [list] | 列表中任何单元字符 | "t[ear]." ﹕可以是tea, tar, try ﹐但不能是tim 。 |
| [range] | 范围中任何单元字符 | "t[er]." ﹕可以是tea, tim, try ﹐但不能是tar 。 |
| [^range] | 任何不在范围中的单一字符 | "t[^er]." ﹕可以是tar﹐但不能是tea, tim, try。 |
通常﹐我们用来处理RE的程式有grep﹑egrep﹑sed﹑awk﹑vi﹑等等﹐各程式的语法和功能都相差很多﹐需要详细研究过才能摸熟。在某些程式中﹐例如egrep和awk﹐还可以处理某些延伸字符﹐例如﹕" | "是两个RE的或一关系﹔" ( )"可用来组合多个RE ﹔等等。有兴趣的话﹐网路上都有许多资料可以找得到﹐例如网站龙门少尉的窝的「正规表示式的入门与应用」等系列文章。
sed & awk
许多人提到RE的时候﹐都少不了介绍一下sed和awk这对宝贝﹐它们都可以用来处理字串﹐但处理手法上却有所不同。有人说用sed对'字行'为单位的处理比较方便﹔而awk则在列表处理上面有独到的神通。是否如此﹐大家不妨自己玩玩看啰。
让我们先看看sed 这个程式﹐它的命令语法有点类型vi 里面的编辑功能﹕
- 以单一字母来做命令名称﹔
- 命令所需的参数置于命令之后﹔
- 您可以将行数或RE 置于命令之前﹐以特指命令要处理的对象。
关于sed 的常用命令﹐请参考下表﹕
| 命令 | 语法 | 说明 |
| a | a\ string | 在字行后面增加特定字串(新行)。 |
| c | c\ string | 将字行换成特定字串。 |
| d | d | 删除字行。 |
| i | i\ string | 在字行前面插入特定字串(新行)。 |
| p | p | 显示字行。除非用-n 指明﹐预设会在处理完毕之后显示子行。 |
| s | s/oldstring/newstring/flag | 用新的字串替换旧的字串。其中可用的旗标有﹕ g﹕替换行中的所有旧字串(预设只换第一个)﹔ p﹕显示﹔ w file ﹕写入特定档案。 |
例如﹐您要输入﹕
| sed 1,3d src.file |
所显示的结果﹐就会将src.file 的前面三行砍掉。如果您输入﹕
| sed '3,$d' src.file |
这样﹐所显示的结果﹐就会从第3 行到最后一行都砍掉﹐只剩下第1 和第2 行而已。上面的命令别忘了加引号﹐否则要\$ 来跳脱。不过﹐我强烈建议您用单引号将sed 的命令括起来。如果您要将空白行拿掉﹐用RE 来做非常简单﹕
| sed '/^$/d' src.file |
在sed 里面引用RE 的时候﹐ 通常都会用两个/ / 符号将RE 括起来﹐然后才是命令。如果您想要更换字串﹐那就要用s 命令了﹕
| sed 's/red/blue/g' src.file |
这样﹐所有的red 字串都会被换成blue ﹔如果没有加上g 旗标﹐那么只有每一行的第一个red 被替换而已。
除了d 和s 命令之外﹐我们还可以用a 命令在句子后面新增一行﹐内容为字串部份﹔或用i 命令在句子前面插入一行﹐内容为字串部份﹔也可以用c 命令将整行换成字串部份。不过﹐您在执行这几个命令的时候﹐必须要用' ' 将命令和参数括起来﹐然后用\ 符号在命令后面跳脱Enter 键﹐然后才能完成。嗯﹐说起来蛮难理解的﹐不如实作一下吧﹕
| sed ' $a \ New line appened at the end. ' src.file |
这样﹐就会在档案最后面增加一行句子了。再比方说﹐您要将第3 行换成另外的文字﹐可以这样玩﹕
| sed ' 3c \ The third line is replace with this line. ' src.file |
再比方说﹐您想将您存储邮件的档案~/mbox 用虚线分开每一封邮件﹐可以这样试试﹕
| sed ' /^From /i \ \ ------------------------- \ \ ' ~/mbox |
我想﹐您应该不会忘记我们在前面的文章中﹐用ifconfig | grep | tr | cut 这些命令管线来抓出网路卡的界面吧。事实上﹐我们用sed 命令也一样可以得到同样的结果﹕
| ifconfig eth0 | grep "inet addr" | sed -e 's/^.*addr://' | sed 's/ *Bcast.*$//' |
第一个sed 是将addr: 到句子前面的字串用s 命令替换为无字串(也就是在最后的// 中间没任何字符)﹔然后第二个sed 将Bcast 连同前面的空白﹐到句子末端也用s 替换为无字串(注意﹕/ *Bcast 的/ 和* 之间是空白键)﹔这样﹐剩下来的就是IP 位址了。
目前﹐我们所进行的命令输出﹐都是在荧幕上﹐既然您已经学会命令的重导向了﹐要将结果保存到其它档案去﹐应是易如反掌了吧。^_^
至于sed 的应用技巧﹐您可以到如下网站好好研究一下﹕
http://www.ptug.org/sed/sedfaq.htm
学习过sed 之后﹐让我们再看看awk 这个命令究竟有什么神通。就拿刚才所举的抓IP 的例子来说好了﹐换成awk 也行哦﹕
| ifconfig eth0 | grep "inet addr" | awk -F ' ' '{print $2}' | awk -F ':' '{print $2}' |
这里的awk 和cut 命令很相似﹕首先﹐用-F 定义出分隔符号(注意﹕第一个命令用空白做分隔符﹐所以-F 后面的两个' ' 之间是空白键)﹐然后再用print命令将相应的列抓出来。对awk 而言﹐变数$0 代表每一行被处理的句子﹐然后第一个栏位是$1﹑第二个栏位是$2﹑.... ﹐如此类推。
如果您以为awk 只能做这些事情﹐就实在是太小看它了﹗ 例如您有这样一个文字档(dog.txt)﹐里面只有这么一行文字﹕
The brown fox jumped on the lazy dog quickly.
|
然后我们用awk 来进行处理﹕
| # awk '{ $2="black"; $3="dog"; $8="fox"; print}' dog.txt The black dog jumped on the lazy fox quickly. |
从上面的例子中﹐我们发现awk 具有处理变数的能力﹐事实上﹐它也有自己内建的变数﹕
| 变数名称 | 代表意思 |
| FS | 栏位分隔符号(预设是空白键)。 |
| NF | 当前句子中的栏位数目。 |
| NR | 当前句子的行数。 |
| FILENAME | 当前处理的档案名称。 |
甚至﹐awk 还能进行数值上的比对﹕
| 变数名称 | 代表意思 |
| > | 大于。 |
| < | 小于。 |
| >= | 大于或等于。 |
| <= | 小于或等于。 |
| == | 等于。 |
| != | 不等于。 |
另外﹐如果严格来执行的话﹐awk命令一共分成三个部份﹕ BEGIN ﹑ main ﹑和END。在awk命令中﹐BEGIN的部份﹐是让程式开始时执行一些一次性的命令﹔而END部份则在程式退出的时候执行一些一次性的命令﹔而main呢﹐则以回圈的形式逐行处理输入。一般来说﹐我们无须定义BEGIN和END﹐直接定义main的部份就可以执行awk命令了。例如﹕
| # echo abcd | awk 'BEGIN { x=1;y=2;z=x+y } {print $x $y $z}' abc |
这个例子有点多余﹐仅作示范而已。因为﹐我们在BEGIN 定义了x﹑y﹑z 的值﹕( 1﹑2﹑3 )﹐然后我们再将$x﹑$y﹑$z (也就是$1﹑$2﹑$3 ) 的栏位列引出来。所以﹐执行结果是第四栏的d 就没有显示了。
再例如﹐您有一个档案(result.txt)﹐其内容如下﹕
FName LName English Chinese Math Kenny Chen 80 80 50 Eward Lee 70 90 90 Amigo Chu 50 80 80 John Smith 90 50 75 |
您可以用下面的命令﹐找出Chinese 及格的名单﹐而只显示其名(忽略其姓)﹕
# awk '{ if ($4 >= 60) print $1" : "$4}' result.txt | tail +2 Kenny : 80 Eward : 90 Amigo : 80 |
如果您不想显示作为标头的第一行句子﹐可以pipe 到tail 命令进行过滤。不如﹐让我们再玩些更复杂的﹐比方说计算所有名单的平均成绩算﹐并且以最后一列显示出来﹐可以这样设计﹕
# awk '{ total = $3 + $4 + $5 number = NF - 2 average = total/number if (NR < 2) printf("%s\t%s\n", $0, "AVERAGE"); if (NR >= 2) printf("%s\t%3.2f\n", $0, average) }' result.txt FName LName English Chinese Math AVERAGE Kenny Chen 80 80 50 70.00 Eward Lee 70 90 90 83.33 Amigo Chu 50 80 80 70.00 John Smith 90 50 75 71.67
|
这个命令看起来有点复杂﹐需要说明一下﹕
- 首先﹐我们用一对{ } 将awk 的命令括起来﹐然后在其外面再加一对' ' ﹐这样您可以在单引号之间敲Enter 将长命令分成多行输入。
- 然后定义了total 的变数为第3﹑4﹑5 栏的总和(也就是English + Chinese + Math)﹐以及变数number 为栏位数目减掉2 (也就是NF - FName - LName )。
- 然后﹐平均值就是total 除以number 。
- 因为档案中的第一行是不能用来运算的﹐而且还必须再加上一个叫AVERAGE的栏位标头﹐所以这里首先用一个if来判断行号是否少于2 (不过﹐我在测试的时候﹐发现不能用= 1来设定﹐我也不知道为什么﹖)﹐然则﹐用printf命令(注意﹕在print后面有一个f字母) ﹐以指定格式进行显示。这里的格式是﹕首先是一个字串( %s )﹐也就是后面所对应的$0 (整行句子)以字串格式显示﹔然后是一个tab键( \t )﹔再下来又是一个字串﹐也就后面的"AVERAGE" (非变数值必须用" "括起来)﹔最后输入一个断行符号( \n ﹐newline的意思)。这里﹐您会发现﹐凡是用%表示的格式﹐必须依顺序对应到后面的显示栏位﹔而用\开头的﹐则是可以从键盘输入的符号。(或许﹐刚开始可能比较难看出个所以然﹐多比较一下﹐就不难发现它的规则啦。后面还有一个范例。)
- 接下来的﹐会先用if 判断行号是否大于或等于2 (您也可以用> 1 ﹐也就是从第二行开始)﹐然则﹐再用printf 命令﹐按%s\t%3.2f\ n 的格式来显示。其中的%s﹑\t﹑\n 相信您都知道了﹐只有%3.2f 没见过而已。它定义出浮点数字( floating point )的显示格式是﹕小数点左边3 位数和小数点右边两位数。所以这行的格式是﹕先用字串显示整行﹑然后一个tab 键﹑然后以3.2 小数点格式显示前面定义好的average 变数﹑最后是一个断行符号﹕
%s \t %3.2f \n | | | | Kenny Chen 80 80 50 70.00 | | | | $0 average
- 然后是'{ }' 这些括号及引号的关闭﹐最后是要处理的档案名称。
而每一行的输出结果﹐就会在字行后面按指定的格式加上tab 键和平均值了。是否很神奇呢﹖ ﹗ 呵呵﹐这只是awk 的牛刀少试而已﹐若要完全发挥awk 的强大火力﹐恐怕已经不是我所能介绍的了。
转载地址:http://blog.csdn.net/tianmo2010/article/details/6684181