mysql hash 索引 vs B-TREE 索引 理解
hash 索引
当前 memory 引擎, innodb 引擎支持 hash 索引, 索引将存放内存中,(innodb 存放 buffer pool)
innodb 启动 innodb-adaptive-hash-index 参数就能够支持
假设利用 show engine innodb status \G 看到大量类似下图的等待值 (参见 RW-latch 由 brt0sea.c 产生)
建议你使用 skip-innodb_adaptive_hash_index 关闭 innodb hash 索引功能.

索引由 HASH 算法获得, 因此不一定是唯一 HASH 值,需要对索引进行全扫描
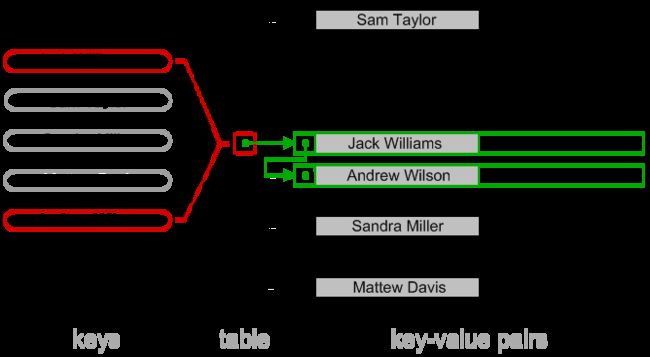
如上图描述,数据存放后, HASH 索引表中, 具有数据及 HASH 键专用存放的区间, 而每个 HASH 都与某个数据一一对应(注,再强调一次不一定唯一哟)
B-TREE 索引
常用 Innodb 与 MyISAM 引擎都支持
在 Innodb里,有两种形态,
一是primary key形态,其leaf node里存放的是数据,而且不仅存放了索引键的数据,还存放了其他字段的数据。
二是secondary index,其leaf node和普通的 B-TREE 差不多,只是还存放了指向主键的信息.
而在MyISAM里,
主键和其他的并没有太大区别。
不过和Innodb不太一样的地方是在MyISAM里,leaf node里存放的不是主键的信息,而是指向数据文件里的对应数据行的信息.

如图描述,如需要获得数据 G6 的信息,那么I/O 顺序为 INDEX PAGE1 -> INDEX PAGE2 -> G -> G6
按照上述顺序,只能够获得 G6 对应的索引信息【如块信息】而已,真正的数据并非存在该表中,利用之前获得的【块信息】可以直接从某个数据块中获得对应的数据信息, 而不需要进行全表扫描在多个数据块中搜索数据
速度比较
hash 索引定位快速一步定位数据
B-TREE 索引要从根页子叶才能够找到具体数据,可能存在对 I/O 才能够获得信息
用于条件判断比较
hash 索引只能够使用 = <> IN 等判断方法进行搜索, 对 order by 没有任何加速功能
B-TREE 索引可用于 =, >, >=, <, <=, BETWEE, 同样可以用于 like 操作
如
select * from t1 where name like 'Parti%'; (支持)
select * from t1 where name like 'Par%ti%'; (支持)
select * from t1 where name like '%Parti'; (不支持)
MySQL 5.6 新参数 --innodb-adaptive-hash-index 能够令 innodb 也具备 hash index 的特性
默认情况下 5.6 启用该功能,但不一定能够获得好处,因此 HASH 索引将会在 INNODB BUFFER 中占用一定的内存空间。
建议自行 BenchMark 一下启用及关闭时的性能再行决定。