Locality-constrained Linear Coding(LLC)总结
LLC(Locality-constrained Linear Coding forImage Classification)解析
1 LLC来源
jianchao yang的这篇Locality-constrained LinearCoding for Image Classification(介绍这篇文章的链接:http://blog.sina.com.cn/s/blog_631a4cc40100wdul.html)是在以下两篇文章的基础上做的,Liner Spatial PyramidMatching using Sparse Coding for Image Classification (CVPR'2009)和Nolinear DimensionalityReduction by Locally Linear Embedding(LLE)。
Liner Spatial Pyramid Matching using Sparse Coding for ImageClassification(CVPR'2009)工作代码可以在jianchao yang主页上下载。文章的创新点是编码方式的创新,提出了LLC。文章的核心公式:
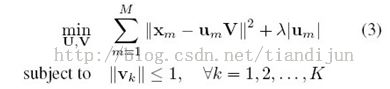
第一项约束重构误差,第二项是用1范数近似0范数约束稀疏性。之后就是一些基本的操作,max pooling和图像金字塔了。这个公式解决了两个问题,其一是多个码本重构特征减少了重构误差,其二用线性SVM减少训练时间。优化这个式子用的是Honglak Lee代码。
Nolinear Dimensionality Reduction by Locally Linear Embedding(LLE)是流行中非常经典的文章,现在的他引率已经达到4550次了,这是发在Science, 2000年的文章。作者Sam T. Roweis,文章中的思想比较简单,就是用近邻的几个点重构他,只考虑他们之间的相对关系。从而降维。
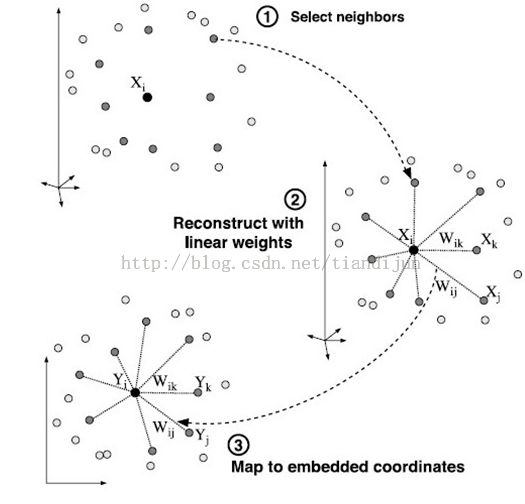
2 对比
LLC是在ScSPM和LCC基础上做了些改进。ScSPM用SC coding代替VQ coding之后,用linear SVM取得了不错的效果,由于发现SCcoding具有局部性,便有了LCC coding。这种编码方法进一步降低了编码计算复杂度,并且可以用linear SVM。
下面将这几种coding的目标函数做一下比较:
VQ coding:

这其实就是一个线性回归问题,用了最小二乘法来求解。relax对Ci的限制,再加上一个sparse regularization 项,便是SC coding:
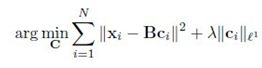
这个方程的最优化问题主要参考了文献Efficient sparse codingalgorithms的算法,具体算法有待深究。改变SC的约束项,便是LLC coding:

其中

注:lamda的作用是调节结果的稀疏性,lamda越大,结果越稀疏。
约束项相当于locality adaptor,这个虽然不是l0范数意义上的稀疏,却在重要系数的意义上确是稀疏的,通过设置阈值,把较小的系数设置为0。这样做与前两种coding algorithm比较有以下优点:
1)相对VQ来说,LLC reconstruction error 更小,因为一个descriptor用了多个base来表示
2)相对SC来说,LLC 不仅是稀疏的,而且具有局部平滑性,把距离较远的base的系数限制为0
3)LLC 具有解析解
3 文章剖析
(1)引入
Thispaper presents a simple but effective coding scheme called Locality-constrainedLinear Coding (LLC) in place of the VQ codingin traditional SPM.
(2)特征量化机制
LLCutilizes the locality constraints to project each descriptor into itslocal-coordinate system, and the projectedcoordinates are integrated bymax pooling to generate the final representation.添加的局部约束
Comparedwith the sparse coding strategy, the objective function used by LLC has ananalytical solution(解析解). In addition, the paper proposes afast approximated LLCmethod by first performing aK-nearest-neighbor searchand then solving aconstrained least square fitting problem
注:与sparse coding相比LLC有解析解,并且计算代价小,计算速度快,可用于实时任务
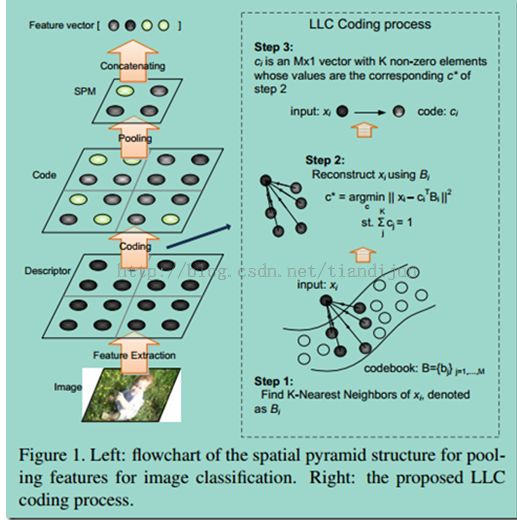
(3)流程
A typical flowchart of the SPM approach based on BoF isillustrated on the left of Figure 1.
1)First, feature points aredetected or densely located onthe input image, and descriptors such as “SIFT” or “color moment” are extractedfrom each feature point (highlighted in blue circle in Figure 1). This obtainsthe “Descriptor”layer.
2)Then, a codebook with Mentries is applied toquantize each descriptor andgenerate the “Code” layer,where each descriptor is converted into an RM code (highlighted in greencircle). Ifhardvector quantization (VQ) is used, each code hasonlyone non-zero element, while forsoft-VQ,a small group of elements can benon-zero.
3)Next in the “SPM” layer, multiple codes from inside eachsub-region are pooled togetherby averaging and normalizinginto a histogram.
4)Finally, thehistograms from allsub-regions are concatenated together togenerate the final representationof the image for classification.
1从输入图像中发掘兴趣点;
2对兴趣点应用特征描述子,得到特征向量;
3量化特征得到codebook;
4特征编码 —— 若是硬投票,每个特征对应一个code;若是软投票,每个特征对应一组code;若是SPM,特征对应的是sub-region中的code,并用averaging pooling 和 归一化成直方图,最后将这些子区域的直方图串连起来形成最终的图像表达,但是为了达到更好的性能,使用SPM的时候要用非线性核SVM,这样计算代价大,效果也一般般。ScSPM 使用sparse codeing 来实现非线性编码(替换了原始的kmeans)ScSPM 实验过程中发现,特征总是和它距离较近的code相关,用局部性约束来鼓励局部的code ——locality is more essentialthan sparsity。
(4)Locality-constrained LinearCoding




Notice:locality is more essential than sparsity, as locality must leadto sparsity but not necessary vice versa
LLC用局部约束来替代稀疏性约束,取得了一些很好的性质

其中,B是basis;c是coefficient;d是与基同维数的局部约束,d与c之间是元素级别的乘法;(4)式就是d的构造;theata用来调整权重,最后还要对d进行归一化。
(5)Properties of LLC
To achieve goodclassification performance, the coding scheme should generate similar codes forsimilar descriptors.
1更好的重建——或更小的量化误差;
2局部平滑稀疏——与sparse coding相比较,SC包含L1范式的规则项不是平滑的;而且由于SC的基是过完备的,相似的特征可能会选择不同的基地来表达,这会带来一定的误差;
3解析解——SC的求解繁琐;
(6)Approximated LLC for Fast Encoding
LLC拥有解析解,但我们可以选择特征附近的K个code来构造其局部坐标系统,加速计算;
而且,这样LLC可以拥有一个巨大的codebook,但每个feature相关的code就那么几个;

(7)Codebook Optimization
According to ourexperimental results in Subsection 5.4, the codebook generated by K-Means can producesatisfactory accuracy. In this work, we use theLLC coding criteria to train the codebook, which further improves theperformance.


(8)分析
1 codebook的学习方法,k-means和作者提供的性能差别不大,但识别率会随着codebook的增大而提高;
2 局部code数目的影响,也就是K的影响 —— K越小识别率越高~~(但不能小于5);
3 wetested the performance under different constraints other than theshift-invariant constraint ——the shift-invariant constraint leads to the bestperformance.(没弄懂???)
4 分析及其纠错
(1) 稀疏优化目标函数
这篇文章是在Linear Spatial Pyramid Matching usingSparse Coding for Image Classification基础上的改进。稀疏表示的目标式为:

而在LLC当中把后面的正则项的一范数改为二范数:

其中,di代表的重构的特征xi和每个码字(code)的距离。
物理意义:特征离码字的距离越远重构的系数越小,极端情况就是用他近邻的码本来重构他。而且这个式子有解析解。
LLC有以下三个性质:
1)跟原始的向量量化比较用多个码字重构能够有更小的重构误差;
2)能达到局部平滑稀疏性;
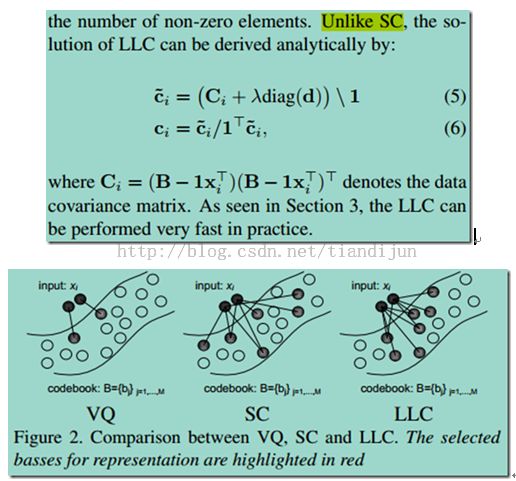
3)跟sparse比较能够有解析解,文中提到的解析解为:

将公式推导了一下,文章中的解是存在问题的。以下解应该是正确的:

注:
1) 为了快速计算LLC是选择最近邻的5个点重构的;
2) 码本的训练也可以用k-means直接聚类,跟他提出的codebook optimization的结果差不多的。
3) 为了矩阵求逆的方便在要求矩阵的对角线加上一些比较小的数,这种方法叫做regularlization,也叫脊回归。
参考:http://blog.sciencenet.cn/blog-722391-568956.html
http://blog.sciencenet.cn/blog-722391-570686.html
http://blog.csdn.net/love_yanhaina/article/details/8823572
http://www.haogongju.net/art/2842710