Optimizing Memcpy improves speed
http://www.embedded.com/design/embedded/4024961/Optimizing-Memcpy-improves-speed
Knowing a few details about your system-memory size, cache type, and bus width can pay big dividends in higher performance.
The memcpy() routine in every C library moves blocks of memory of arbitrary size. It's used quite a bit in some programs and so is a natural target for optimization. Cross-compiler vendors generally include a precompiled set of standard class libraries, including a basic implementation of memcpy(). Unfortunately, since this same code must run on hardware with a variety of processors and memory architectures, it can't be optimized for any specific architecture. An intimate knowledge of your target hardware and memory-transfer needs can help you write a much more efficient implementation of memcpy().
This article will show you how to find the best algorithm for optimizing the memcpy() library routine on your hardware. I'll discuss three popular algorithms for moving data within memory and some factors that should help you choose the best algorithm for your needs. Although I used an Intel XScale 80200 processor and evaluation board for this study, the results are general and can be applied to any hardware.
A variety of hardware and software factors might affect your decision about a memcpy() algorithm. These include the speed of your processor, the width of your memory bus, the availability and features of a data cache, and the size and alignment of the memory transfers your application will make. I'll show you how each of these factors affects the performance of the three algorithms. But let's first discuss the algorithms themselves.
Three basic memcpy() algorithms
The simplest memory-transfer algorithm just reads one byte at a time and writes that byte before reading the next. We'll call this algorithm byte-by-byte. Listing 1 shows the C code for this algorithm. As you can see, it has the advantage of implementation simplicity. Byte-by-byte, however, may not offer optimal performance, particularly if your memory bus is wider than 8 bits.
Listing 1: The byte-by-byte algorithm
void * memcpy(void * dst, void const * src, size_t len)
{
char * pDst = (char *) dst;
char const * pSrc = (char const *) src;
while (len--)
{
*pDst++ = *pSrc++;
}
return (dst);
}
An algorithm that offers better performance on wider memory buses, such as the one on the evaluation board I used, can be found in GNU's newlib source code. I've posted the code here. If the source and destination pointers are both aligned on 4-byte boundaries, my modified-GNU algorithm copies 32 bits at a time rather than 8 bits. Listing 2 shows an implementation of this algorithm.
Listing 2: The modified-GNU algorithm
void * memcpy(void * dst, void const * src, size_t len)
{
long * plDst = (long *) dst;
long const * plSrc = (long const *) src;
if (!(src & 0xFFFFFFFC) && !(dst & 0xFFFFFFFC))
{
while (len >= 4)
{
*plDst++ = *plSrc++;
len -= 4;
}
}
char * pcDst = (char *) plDst;
char const * pcDst = (char const *) plSrc;
while (len--)
{
*pcDst++ = *pcSrc++;
}
return (dst);
}
A variation of the modified-GNU algorithm uses computation to adjust for address misalignment. I'll call this algorithm the optimized algorithm. The optimized algorithm attempts to access memory efficiently, using 4-byte or larger reads-writes. It operates on the data internally to get the right bytes into the appropriate places. Figure 1 shows a typical step in this algorithm: memory is fetched on naturally aligned boundaries from the source of the block, the appropriate bytes are combined, then written out to the destination's natural alignment.

Figure 1: The optimized algorithm
Note that the optimized algorithm uses some XScale assembly language. You can download this algorithm here. The preload instruction is a hint to the ARM processor that data at a specified address may be needed soon. Processor-specific opcodes like these can help wring every bit of performance out of a critical routine. Knowing your target machine is a virtue when optimizing memcpy().
Having looked at all three of the algorithms in some detail, we can begin to compare their performance under various conditions.
Block size
What effect does data size have on the performance of our algorithms? To keep things simple, let's assume that there's no data cache (or that it's been disabled) and that all of the source and destination addresses are aligned on 4-byte boundaries.

Figure 2: Algorithm comparison for small data blocks (20 bytes)
As you can see in Figure 2, byte-by-byte does the best when the blocks are small, in this case 20 bytes. Byte-by-byte's main advantage is that it lacks overhead. It just moves bytes, without looking at addresses. The actual copy loop only runs for a small number of iterations (20 in this case), and then the routine is complete.
Note also that the performance of byte-by-byte improves dramatically as the processor clock speed increases. This implies that the routine is CPU-bound. Until we saturate the memory bus with reads and writes, the byte-by-byte algorithm will continue to execute more quickly.
For larger blocks, the situation is different. For example, simply increasing the size of the data blocks to 128 bytes makes byte-by-byte the clear loser at all processor speeds, as shown in Figure 3.

Figure 3: Algorithm comparison for large data blocks (128 bytes)
Here the modified-GNU algorithm has the best performance, as it makes more efficient use of the memory bus. The optimized algorithm has comparable performance, but the effects of its additional computation take their toll in overhead.
Data alignment
What happens if the source and destination are not both aligned on a 4-byte boundary? Figure 4 shows the results on a 128-byte block with unaligned addresses. It's obvious here that byte-by-byte is not affected by the misalignment of data blocks. It just moves a single byte of memory at a time and doesn't really care about addresses.
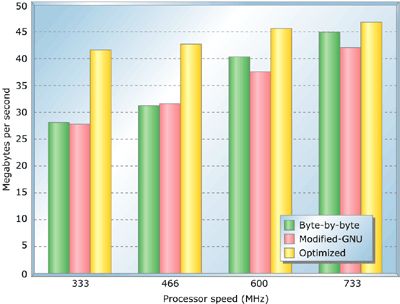
Figure 4: Algorithm comparison for unaligned data blocks (128 bytes)
The modified-GNU algorithm performs worse than byte-by-byte in this situation, largely because it defaults to byte-by-byte (after a fixed overhead).
The big overhead in the GNU algorithm comes from register save-restore in its prologue-epilogue. The algorithm saves off four registers, where the byte-by-byte routine saves none. So, as memory speed decreases in relation to processor speed, the GNU algorithm suffers accordingly. By the way, "optimized" memcpy saves off nine registers, which is part of the reason it becomes less compelling at high core and bus speeds. This overhead matters less when the stack is cached (probably the normal case).
The optimized algorithm handles unaligned addresses the best outperforming byte-by-byte. At slower clock speeds, the overhead of dealing with alignment is amortized by the cost of actually moving the memory four times as quickly. As CPU performance improves (with respect to the memory system), the elegance of an algorithm like optimized becomes less helpful.
Caching
Everything changes if your processor has a data cache. Let's try the same memcpy tests we've already run, but with the data already in cache. Figures 5 and 6 show the results. The memory is no longer the bottleneck, so algorithm efficiency becomes the limiting factor. If your data is likely to reside mainly in the cache, use something other than byte-by-byte.

Figure 5: Data cache effect on memcpy throughput (333MHz)

Figure 6: Data cache effect on memcpy throughput (733MHz)
Note that the bar charts in Figures 5 and 6 look about the same, although the y-axis scales differ. This y-axis difference supports the contention that we're limited by processing speed, not by memory. Also, the data for unaligned memcpy shows that the GNU memcpy performance degrades to that of byte-by-byte performance when addresses are not aligned. You may see severe degradation in memcpy performance if your data is not always aligned in memory.
Write policy
A write-through cache is one that updates both the cache and the memory behind it whenever the processor writes. This sort of cache tries to satisfy reads without going to memory.
A write-back cache, on the other hand, tries to satisfy both reads and writes without going to memory. Only when the cache needs storage will it evict some of its data to memory; this is called variously a write back, a cast out, or an eviction. Write-back caches tend to use less memory bandwidth than write-through caches.
The processor I used allows the cache to be configured using either policy. What effect does this have on memcpy? It depends. Figure 7 shows what happens when the cache is cold (no data in it). Figure 8 shows what happens if the cache contains only garbage data (data from other addresses).

Figure 7: Cache-policy effect (cold cache, 128 bytes, 333MHz)

Figure 8: Cache-policy effect (garbage cache, 128 bytes, 333MHz)
With a cold cache, optimized memcpy with write-back cache works best because the cache doesn't have to write to memory and so avoids any delays on the bus.
For a garbage-filled cache, write-through caches work slightly better, because the cache doesn't need to spend extra cycles evicting irrelevant data to memory. As usual, the more you know about your system"such as the likelihood of having certain data in the cache"the better you can judge the efficacy of one cache policy over another.

Figure 9: Performance of 4KB memcpy
Special situations
If you know all about the data you're copying as well as the environment in which memcpy runs, you may be able to create a specialized version that runs very fast. Figure 9 shows the performance gain we accrue by writing a memcpy that handles only 4KB-aligned pages when the cache is in write-through mode. This example shows that writing a very specific algorithm may double the speed of a memcpy-rich program. I've posted one of these algorithms here.
Optimize away
Some applications spend significant processor time transferring data within memory; by choosing the optimal algorithm, you could improve overall program performance significantly. The moral of the story: know your target hardware and the characteristics of your application. Armed with this knowledge, you can easily find the optimal algorithm.
Mike Morrow is a processor architect in the Intel XScale core group. He's been developing embedded software/hardware for about 15 years. Mike earned an MS in computer science from the University of Tennessee. He can be reached at [email protected].