Java并发编程之ConcurrentHashMap原理分析
前言
集合是编程中最常用的数据结构。而谈到并发,几乎总是离不开集合这类高级数据结构的支持。比如两个线程需要同时访问一个中间临界区(Queue),比如常会用缓存作为外部文件的副本(HashMap)。
在tiger之前,我们使用得最多的数据结构之一就是HashMap和Hashtable。大家都知道,HashMap中未进行同步考虑,而Hashtable则使用了synchronized,(HashMap是线程非安全的,HashTable是线程安全的)带来的直接影响就是可选择,我们可以在单线程时使用HashMap提高效率,而多线程时用Hashtable来保证安全。
ConcurrentHashMap原理分析
当我们享受着jdk带来的便利时同样承受它带来的不幸恶果。通过分析Hashtable就知道,synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,安全的背后是巨大的浪费,慧眼独具的Doug Lee立马拿出了解决方案—-ConcurrentHashMap。
如图:
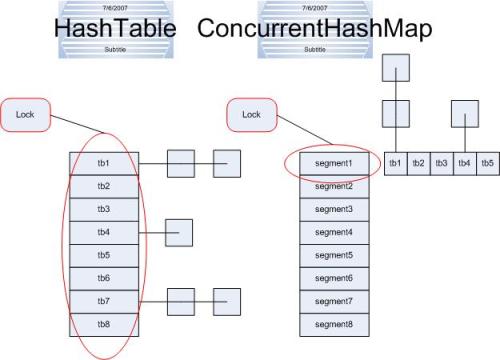
左边便是Hashtable的实现方式—锁整个hash表;而右边则是ConcurrentHashMap的实现方式—锁桶(或段)。
官方文档中是这样说的:
ConcurrentHashMap支持获取的完全并发和更新的所期望可调整并发的哈希表。此类遵守与 Hashtable 相同的功能规范,并且包括对应于 Hashtable 的每个方法的方法版本。不过,尽管所有操作都是线程安全的,但获取操作不 必锁定,并且不 支持以某种防止所有访问的方式锁定整个表。此类可以通过程序完全与 Hashtable 进行互操作,这取决于其线程安全,而与其同步细节无关。ConcurrentHashMap将hash表分为16个桶(默认值),诸如get,put,remove等常用操作只锁当前需要用到的桶。试想,原来只能一个线程进入,现在却能同时16个写线程进入(写线程才需要锁定,而读线程几乎不受限制,之后会提到),并发性的提升是显而易见的。
更令人惊讶的是ConcurrentHashMap的读取并发,因为在读取的大多数时候都没有用到锁定,所以读取操作几乎是完全的并发操作,而写操作锁定的粒度又非常细,比起之前又更加快速(这一点在桶更多时表现得更明显些)。
ConcurrentHashMap只有在求size等操作时才需要锁定整个表。而在迭代时,ConcurrentHashMap使用了不同于传统集合的快速失败迭代器的另一种迭代方式,我们称为弱一致迭代器。在这种迭代方式中,当iterator被创建后集合再发生改变就不再是抛出ConcurrentModificationException,取而代之的是在改变时new新的数据从而不影响原有的数据,iterator完成后再将头指针替换为新的数据,这样iterator线程可以使用原来老的数据,而写线程也可以并发的完成改变,更重要的,这保证了多个线程并发执行的连续性和扩展性,是性能提升的关键。
接下来,让我们看看ConcurrentHashMap中的几个重要方法,心里知道了实现机制后,使用起来就更加有底气。
ConcurrentHashMap中主要实体类就是三个:
1、ConcurrentHashMap(整个Hash表);
2、Segment(桶);
3、HashEntry(节点)
对应上面的图可以看出之间的关系。
ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术。它使用了多个锁来控制对hash表的不同部分进行的修改。ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hash table,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。
有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁。这里“按顺序”是很重要的,否则极有可能出现死锁,在ConcurrentHashMap内部,段数组是final的,并且其成员变量实际上也是final的,但是,仅仅是将数组声明为final的并不保证数组成员也是final的,这需要实现上的保证。
ConcurrentHashMap完全允许多个读操作并发进行,读操作并不需要加锁。
get方法(请注意,这里分析的方法都是针对桶的,因为ConcurrentHashMap的最大改进就是将粒度细化到了桶上),首先判断了当前桶的数据个数是否为0,为0自然不可能get到什么,只有返回null,这样做避免了不必要的搜索,也用最小的代价避免出错。然后得到头节点(方法将在下面涉及)之后就是根据hash和key逐个判断是否是指定的值,如果是并且值非空就说明找到了,直接返回;程序非常简单,但有一个令人困惑的地方,这句return readValueUnderLock(e)到底是用来干什么的呢?研究它的代码,在锁定之后返回一个值。但这里已经有一句V v = e.value得到了节点的值,这句return readValueUnderLock(e)是否多此一举?事实上,这里完全是为了并发考虑的,这里当v为空时,可能是一个线程正在改变节点,而之前的get操作都未进行锁定,根据bernstein条件,读后写或写后读都会引起数据的不一致,所以这里要对这个e重新上锁再读一遍,以保证得到的是正确值,这里不得不佩服Doug Lee思维的严密性。整个get操作只有很少的情况会锁定,相对于之前的Hashtable,并发是不可避免的啊!
ConcurrentHashMap常用方法
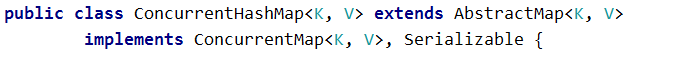
这个是源码中ConcurrentHashMap的继承和实现的关系
ConcurrentHashMap具体是怎么实现线程安全的呢,肯定不可能是每个方法加synchronized,那样就变成了HashTable。
从ConcurrentHashMap代码中可以看出,它引入了一个“分段锁”的概念,具体可以理解为把一个大的Map拆分成N个小的HashTable,根据key.hashCode()来决定把key放到哪个HashTable中。
在ConcurrentHashMap中,就是把Map分成了N个Segment,put和get的时候,都是现根据key.hashCode()算出放到哪个Segment中
注:ConcurrentMap
官方解释:内存一致性效果:当存在其他并发 collection 时,将对象放入 ConcurrentMap 之前的线程中的操作 happen-before 随后通过另一线程从 ConcurrentMap 中访问或移除该元素的操作。
其实ConcurrentMap可以看做是一个缓存的容器,其中包含remove、replace方法,当元素进行remove的时候,会通知阻塞的线程,类似于Guava中的CacheBuilder(http://blog.csdn.net/xlgen157387/article/details/47293517)
源码再往下来的话就是一些常量:
static final int DEFAULT_INITIAL_CAPACITY = 16; //桶的默认容量
static final float DEFAULT_LOAD_FACTOR = 0.75f; //加载因子
static final int DEFAULT_CONCURRENCY_LEVEL = 16; //新的空映射
static final int MAXIMUM_CAPACITY = 1 << 30; //位移的方式,就是2的30次方1073741824,代表桶的最大值
static final int MIN_SEGMENT_TABLE_CAPACITY = 2; //就是每个表分的最小份数是2
static final int MAX_SEGMENTS = 1 << 16;
static final int RETRIES_BEFORE_LOCK = 2;(1)删除操作:
public V remove(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).remove(key, hash, null);
}
根据代码可以知道,整个删除操作,是根据key然后进行hashCode计算来找到具体的hash段,定位到ConcurrentHashMap的某一段,然后委托给段的remove操作。当多个删除操作并发进行时,只要它们所在的段不相同,它们就可以同时进行。
再删除的时候,被删除的元素,会被放进一个待删除的表中,等待垃圾收集器集中清理。
然后就是一些常见的方法,详细可参见:http://tool.oschina.net/apidocs/apidoc?api=jdk-zh