SQL LIKE语句多条件贪婪匹配算法
在CMS开发中,经常会有类似这样的需求:
提问——回答模式,最经典的例子就是百度提问。
提问者提出问题,由其他人回答,其他人可以是用户,也可以是服务商。
在这个模式中,如何充分利用历史数据是最关键的技术。很多时候,由于客户不擅长使用搜索功能,一上来就提问,而这些问题往往早已经有近乎完美的答案,但没有充分利用。这样一来,不仅加大了劳动量,又增加了数据冗余。
如果在提问的时候能充分调动历史数据,提交问题之前先看看历史问题能不能解决客户疑问,解决了,最好不过,解决不了,再提交。百度提问就是采用的这种方案:
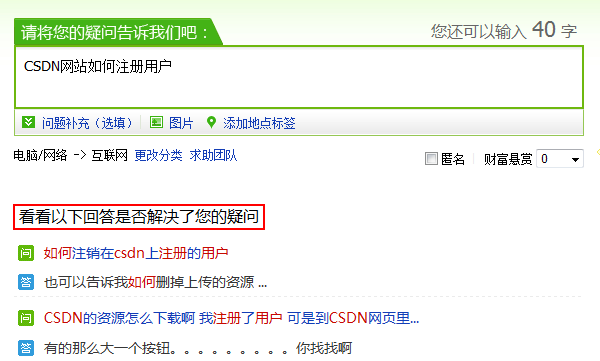
模式固然好,可怎么实现就有些困难了,毕竟这是百度作为搜索引擎的看家本领。
从上图可以看出“CSDN网站如何注册用户”这句话被拆成了N个词,然后分开去数据库中匹配,为什么?因为直接去匹配“CSDN网站如何注册用户”这句话,汉语博大精深,稍微变动一下:“如何在CSDN网站注册用户”,意思完全一样,但直接匹配绝对匹配不到!
因此,我们需要把一句话拆分成词组,这个在网上有现成的组件,比如“庖丁解牛”等,它们大多数是免费开源的。拆成词组之后,应该还要有一个关键词筛选词库,用这个词库确定出有效的词组,比如上图中,“CSDN”、“注册”、“用户”是有效的,而“网站”显然没有匹配,因为它在这句话中没有实际意义。
有点跑题了,拆词、选词不是本文的重点,但却是本文的前提。拿到关键词之后,怎么去数据库中匹配呢?
大家都知道T-SQL中的LIKE语句,通过类似LIKE “%abc%”这样的语法,可以进行模糊匹配,但是它仅仅能进行一次模糊匹配。举个例子:
假如我们确定了a,b,c三个关键词,要查找的记录当然是匹配的越多越好,于是可以这样写:LIKE “%a%b%c%”,这样匹配出的就是包含a,b,c三个关键词的记录,但是如果根本没有包含这三个关键词的记录,最多只有包含两个的,甚至是只包含一个,那么如何写LIKE语句呢?这样LIKE “%a%b%”?这样LIKE “%a%c%”?这样LIKE “%b%c%”?这样LIKE “%a%”?这样LIKE “%b%”?这样LIKE “%c%”?
显然,需要判断的情况太多,简单的LIKE语句已经无法满足需求。需要注意的是,千万不要试图选出范范的记录,返回到程序中去处理,在程序中处理虽然简单,但是范范的记录,在一个中型系统中,往往能达到千万级别,这么大的数据量,从数据库返回到程序,无疑会给服务器造成相当大的压力。
经过探索,本小菜总结了一个比较简单的方法,暂且称为“LIKE语句多条件贪婪匹配算法”。
算法思想:先用LIKE选出每一组符合一个条件的记录,只选择表的主键。然后把这些记录合并在一起,通过主键分组、统计数量,数量最多的,也就是匹配最多的,最后根据数量降序排序,越靠上的记录,匹配的越多。选出匹配的多的记录主键字段,再根据主键去表中选出内容即可。
为了方便大家使用,已经把算法封装成存储过程(直接把下边代码在查询分析器中执行即可)。
存储过程(函数)如下:
GO
CREATE function Get_StrArrayLength
(
@str varchar(1024), --要分割的字符串
@split varchar(10) --分隔符号
)
returns int
as
begin
declare @location int
declare @start int
declare @length int
set @str=ltrim(rtrim(@str))
set @location=charindex(@split,@str)
set @length=1
while @location<>0
begin
set @start=@location+1
set @location=charindex(@split,@str,@start)
set @length=@length+1
end
return @length
end
GO
CREATE function Get_StrArrayStrOfIndex
(
@str varchar(1024), --要分割的字符串
@split varchar(10), --分隔符号
@index int --取第几个元素
)
returns varchar(1024)
as
begin
declare @location int
declare @start int
declare @next int
declare @seed int
set @str=ltrim(rtrim(@str))
set @start=1
set @next=1
set @seed=len(@split)
set @location=charindex(@split,@str)
while @location<>0 and @index>@next
begin
set @start=@location+@seed
set @location=charindex(@split,@str,@start)
set @next=@next+1
end
if @location =0 select @location =len(@str)+1
--这儿存在两种情况:1、字符串不存在分隔符号 2、字符串中存在分隔符号,跳出while循环后,@location为0,那默认为字符串后边有一个分隔符号。
return substring(@str,@start,@location-@start)
end
GO
CREATE PROCEDURE proc_Common_SuperLike
--要查询的表的主键字段名称
@primaryKeyName varchar(999),
--要查询的表名
@talbeName varchar(999),
--要查询的表的字段名称,即内容所在的字段
@contentFieldName varchar(999),
--查询记录的个数(TOP *),匹配的个数越多,排名越靠前
@selectNumber varchar(999),
--匹配字符分隔标记
@splitString varchar(999),
--匹配字符组合字符串
@words varchar(999)
AS
declare @sqlFirst varchar(999)
declare @sqlCenter varchar(999)
declare @sqlLast varchar(999)
BEGIN
set @sqlCenter=''
declare @next int
set @next=1
while @next<=dbo.Get_StrArrayLength(@words,@splitString)
begin
--构造sql查询条件(中间部分)
set @sqlCenter = @sqlCenter+'SELECT '+@primaryKeyName+' FROM '+@talbeName+' WHERE '+@contentFieldName+' like ''%'+dbo.Get_StrArrayStrOfIndex(@words,@splitString,@next)+'%'' UNION ALL '
set @next=@next+1
end
--处理sql语句中间部分,去除最后无用语句
set @sqlCenter=left(@sqlCenter,(len(@sqlCenter)-10))
--构造sql语句开头部分
set @sqlFirst='SELECT TOP '+@selectNumber+' '+@primaryKeyName+',COUNT(*) AS showCout FROM ('
--构造sql语句结尾部分
set @sqlLast=') AS t_Temp GROUP BY '+@primaryKeyName+' ORDER BY showCout DESC'
--拼接出完整sql语句,并执行
execute(@sqlFirst+@sqlCenter+@sqlLast)
END
调用示例:
executeproc_Common_SuperLike 'id','t_test','content','20','|','i|o|c'
id表的主键字段名称。
t_test表名。
content匹配内容字段名称。
20选出20个记录(从顶至下匹配度越来越低)。
|关键字的分隔符号。
i|o|c一共有i,o,c三个关键字,通过|分隔。
注意这个存储过程选出来的是匹配度高的记录的主键,还需要根据主键去表中查一下,查询出需要的内容(问题名称)。
有问题欢迎和我交流,原创算法,可用于任何场合,注明出处即可。