Lucene核心类
索引
IndexWriter
是索引过程的核心组件,这个类用于创建一个新的索引并且把文档加到已有的索引中去。可以把IndexWriter当作这样的一个对象:它可以为你提供对索引的写入操作,但不能读取或搜索索引。
Directory
描述了索引存放的位置。它是一个抽象类,具体的子类提供了特定的存储索引的方法(Lucence中包含了两个子类)。IndexWritter使用了Directory的一个具体实现FSDirectory,它在文件系统中的目录创建索引文件。另一个子类是RAWDirectory,它是把索引数据保存在了内存中。
Analyzer
在文本被索引之前,需要经过分析器(Analyer)的处理。应用程序在IndexWritter的构造函数中指定程序所需要使用的分析器,它负责从将被索引的文本文件中提取语汇单元(tokens),并剔除剩下的无用信息。如果被索引的文件不是纯文本,那么就需要先将其转换为文本。
Document
是承载数据的实体,代表一个被索引的基本单元。一个文档代表一些域(Filed)的集合,你可以把Document对象当成一个虚拟的文档——比如一个web,一个email消息或一个文本文件等。然后从中取回大量的数据。一个文档的域代表文档或和文档相关的元数据。文档数据的数据源对于Lucene来说都是无关紧要的。像作者、标题、主题等元数据都作为文档不同的域被单独存储并索引。
Lunuce只能处理文本,因为Lucene的内核本身只处理String 和 Reader两个对象
Field
索引中的每个一个Document对象包含一个或多个不同命名的域(Field),这些域包含在Field类中。每个域都对应于一段数据,这些数据在搜索过程中可能被查询或者在索引中被检索。
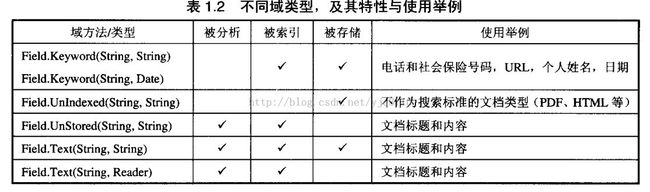
4个不同类型的Filed:
Keyword域:不需要被分析,但是会被逐字地索引并存储。适用于原始值:路径、作者、时间。。
UnIndexed域:不需要被分析、被索引,但需要存储在索引文件中。该类适合于需要和搜索结果一起被显示出来,但用户不会将它的值直接用于搜索的情形(如URL、数据库主键),由于这种域的原始值被存储在索引中,若引起索引体积过大时,该类型不适合存储大文本。
UnStored域:与 UnIndexed相反,需要被分析并索引,但不会存储在索引文件中。该类型用于索引那些不需要以其原始形式进行索引的大文本,比如 :网页正文、或其他类型的文本。
Text域:需要被分析且索引。这意味着该类型的域能够被搜索,但是要注意域的大小。如果被索引的数据是一个字符串,它将会被索引起来;但是如果数据来自Reader对象,那么它就不会被存储在索引文件中。该类型常常会导致混乱,所以在使用Text类型域时要特别小心。
搜索
IndexSearcher
Term
Query
TermQuery
Hits