js入门——Dom基础
DOM=DocumentObject Model,文档对象模型。
Dom有三个不同的部分。
1、核心DOM 也是最基础的文档结构的标准模型
2、XMLDOM 针对XML文档的标准模型
3、HTML DOM 针对HTML文档的标准模型
对于一个新生程序员来说。HTML是什么,其实并不重要。但是都知道。html文件,可以用浏览器打开。
HTML和XML,基本相同。只不过是,HTML中节点 标记,是预先定义好的。而XML中的节点,由文档的作者定义。所以XML是可扩展的。
HTML: 超文本标记语言。主要功能是能被浏览器解析 显示出来。HTML可以看作是一种特殊的标记语言。
XML:可扩展标记语言。
而DOM作为以上的标准。当然会对其上面进行规划:
根据DOM,文档每个成分都是一个节点。对于上面的文档。其实就是一颗树。
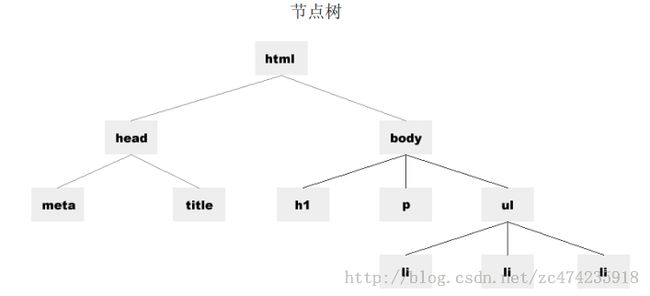
通过一个例子来了解一下:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta http-equiv="Content-Type" content="text/html; charset=gb2312" /> <title>DOM</title> <script src="base.js"></script> <script src="index.js"></script> <link rel="stylesheet" type="text/css" href="index.css" /> </head> <body> <h1>标题H1</h1> <p>p标签</p> <ul> <li>栏目一</li> <li>栏目二</li> <li>栏目三</li> </ul> <div id='box' name='boxs'>测试div</div> </body> </html>
什么是节点?
文档中的所有标记,都称之为节点。
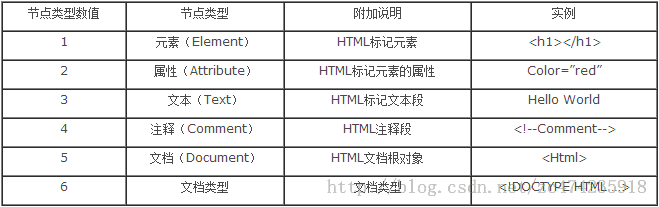
DOM节点树中的节点分为:
元素节点、文本节点、属性节点。
元素节点:标记名称 如 html body div等
文本节点:标记的内容 如 "测试div" "p标签" 等等
属性节点:用于修饰 标记名称的。也算是 标记的属性。 如 :id='boxs'
对元素元素的查询:
元素的查询,有好多种方式。
根据标记名称(getElementsByTagName)、id名(getElementById)、name名(getElementsByName)。都可以进行查找
innerHTML:获取元素节点中的文本节点
元素属性节点的修改。查到元素之后,也可以进行 属性的修改 attribute
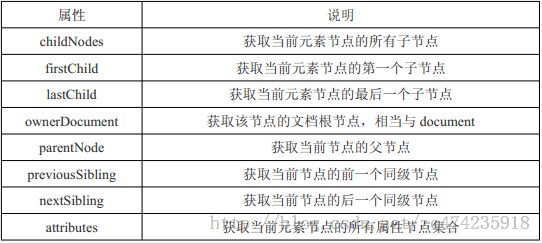
查找元素的时候,如果查到的元素 不止一个,那么返回的为一个节点数组。因此在使用的时候一定不能缺少数组标号。通过childNode属性来获取所有子节点
对与节点来说,也是一种树形结构。当查询到一个元素节点后,这个元素节点中 也包括很多小节点。
![]()
如上所示的节点,由 属性节点 和 文本节点构成。使用childNodes.length 获取元素节点中的所有子节点
使用的时候,与数组类似 childNodes[i] 对第i个子节点进行操作
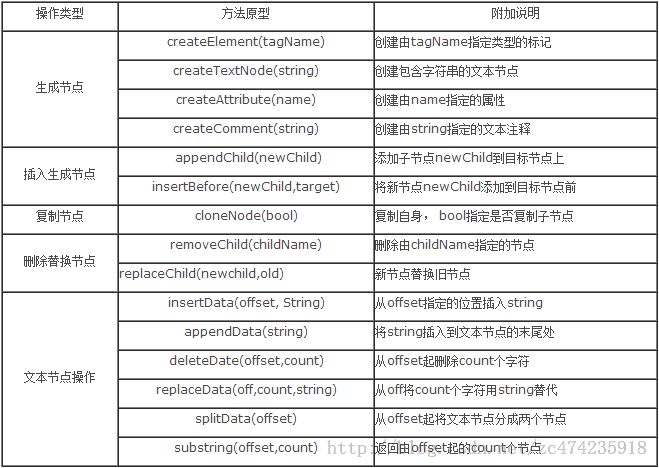
对子节点的操作
DOM基础很多,记是肯定记不住的。浏览一遍,了解一下,在下次使用的时候,知道有那么一回事。知道在哪里查资料就行了。
当然,也可以根据IDE的智能提示来做。