Robust Visual Tracking via Convolutional Networks 阅读笔记
这篇作者是:Prof. Kaihua Zhang, Qingshan Liu, Yi Wu, and Ming-Hsuan Yang,全是大牛。前几天看到他们把新版本的CNT放出来了,于是抓紧时间阅读了一下,整体思想与上一篇文章差别不大,下面详细介绍一下这篇文章。
基本思想
作者想构造一个在线的两层卷积神经网络用于visual tracking。首先在第一帧图像中,作者从目标区域提取很多归一化的图像patch,然后使用k-means 算法得到代表性的patch作为滤波器。当然,这些滤波器patch还包含着一些目标周围区域的上下文信息,这些滤波器用来定义随后帧图像的特征图(feature maps)。这些map用来衡量每一个滤波器和目标上游有用的局部强度模式之间的相似度。因此能够编码目标的局部结构信息。此外,所有的maps可以组合起来生成一个基于中层特征的全局的表达,而且与基于part方法的表达的不同在于保留了目标的几何布局。最后自适应阈值的的soft shrinkage 方法用来实现对全局表达的去噪,形成一个稀疏的表达。这个表达的更新采用的是简单的有效的在线策略,能够有效的适应目标外观的变化。
整个model的框架如下:
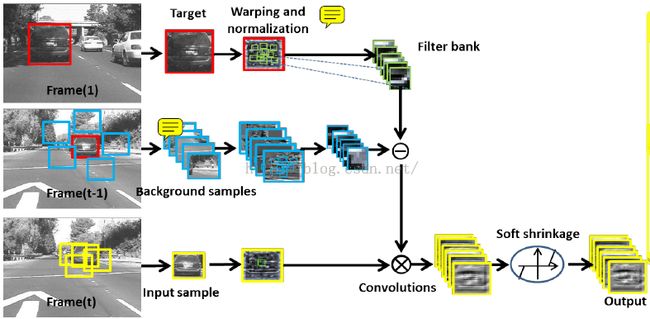
首先将图像样本分割成32*32大小的patch,利用kmeans 算法从这些切割的区域中聚类出一定树龄的归一化的图像patch,同时还要从目标周围区域提取出归一化的local patches。我们然后将他们作为滤波器对随后帧提取的归一化的样本进行卷积操作,从而生成一组特征图。最后这组特征图通过soft shrinkage 方法进行去噪,从而生成一个稀疏的表达。
这个流程下来,我们发现这个与标准的CNN是有很大区别的,作者也指出:没有包含pooling操作。
具体的实现如下
A首先是图像表达
step1;预处理。将输入图像灰度化,然后将其warp成固定的尺寸n*n尺寸大小。然后进行密集重采样得到很多图像patch y={Y1,....Yl},尺寸为w*w大小,那么总的图像patch的个数就是(n-w+1)*(n-w+1);所有的patch都通过去均值处理和l2归一化来消除光照和对比度的影响。
step2 针对第一层,
也就是简单细胞层。作者采用k means聚类的方法从y中选出一组patch F作为滤波器模板。给定第i个滤波器模板,![]() ,于是对输入图像I的相应map就可以表示为:
,于是对输入图像I的相应map就可以表示为:![]() 如下图所示:
如下图所示:
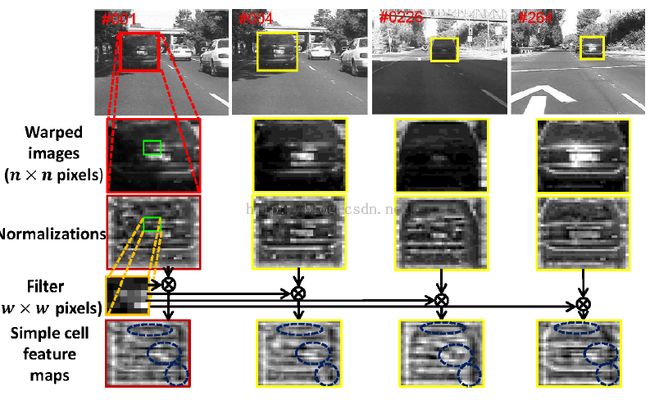
从这个图中我们可以看出,尽管目标的外观由于光照变化和尺度变化而发生了明显的改变,但是经过卷积滤波之后的输出,也就是简单细胞feature maps不仅能够保留目标的局部结构,而且还能维持目标的全局几何布局几乎不变。同时由于目标周围的上下文背景可以为区分目标和背景提供很多有用的信息,因此同样需要对背景进行采样并且进行k-means聚类,获得一组模板:![]() ,然后利用average pooling 获得一个平均背景
,然后利用average pooling 获得一个平均背景![]() ,然后与输入图像I做卷积之后,可以得到:
,然后与输入图像I做卷积之后,可以得到:
![]()
step 3 复杂层
这一层作者用一个3维的张量![]() 来表示简单细胞层获得的d个feature maps的集合。由于传统的CNN方法的复杂层具有shift-invariant,然而这对于tracking是不可接受的(会产生位置混淆的问题),于是作者在文章用的是shift-variant 的complex cell features来保证方法对于位置混下的鲁棒性。瓷王,这种特征还对于尺度变化特别鲁棒。通过将不同尺度上的目标warp成一个固定的尺度,目标上的每一个有用的part在warped图像中变化不是很明显,因此复杂细胞特征可以保留不同尺度上的有用的parts的几何布局。
来表示简单细胞层获得的d个feature maps的集合。由于传统的CNN方法的复杂层具有shift-invariant,然而这对于tracking是不可接受的(会产生位置混淆的问题),于是作者在文章用的是shift-variant 的complex cell features来保证方法对于位置混下的鲁棒性。瓷王,这种特征还对于尺度变化特别鲁棒。通过将不同尺度上的目标warp成一个固定的尺度,目标上的每一个有用的part在warped图像中变化不是很明显,因此复杂细胞特征可以保留不同尺度上的有用的parts的几何布局。
同时为了让这个张量C对于由目标外观变化引发的噪声的鲁棒性,我们利用一个稀疏的矢量c来近似vec(C),这个可以通过稀疏编码的方法实现:
![]() ----------------------------------2
----------------------------------2
然后利用soft shrinkage的方法就可以求解这个model的解:
![]() --------------------------3
--------------------------3
step 4 model update
这块涉及到对公式2中c的model update,不再赘述。
Proposed Tracking Algorithm
作者的框架还是基于partial filter的方法来做的。给定前t帧的观察数值![]() ,后验概率
,后验概率![]() 其中
其中![]() 。
。![]() 表示基于前一个状态下对当前状态的预测。
表示基于前一个状态下对当前状态的预测。![]() 是观察model表示当前状态下观察量o属于目标的概率。
是观察model表示当前状态下观察量o属于目标的概率。