我对语义网(Semantic Web)应用发展的一些看法
我对语义网(Semantic Web)应用发展的一些看法
前言:
前不久应朋友之邀,为其学生作了一次关于互联网应用发展和基础架构演变的技术讲座。为此我专门整理了一些关于当前网络应用——重点是语意网——的最新资讯,同时也结合自身工作中的思考,总结了一些语义网发展相关的个人看法,在这里很希望和大家讨论讨论。
关于网络应用所依赖基础架构演变的问题——重点是海量存储和计算的系统架构的趋势——我接下来也会找时间总结出来,希望抛砖引玉,与大家共同学习。
语义需求:
关心和观察互联网发展的朋友,都会了解到当前炒作正热的语义网概念。业界和学术界之所以热衷的追逐语义网,归根结底是因为对互联网对语义的需求越来越迫切。所谓需求推动技术,语义网技术的兴起无疑起源于目前万维网的不足。
万维网存在两个明显的不足:
-
1. 计算机不能理解目前网页内容的语义:因为万维网只是文档载体,它的目的只是供人来阅读。
-
2. 信息无序存在: 网上信息爆炸,但是想要的信息却往往难找,即使借助功能强大的搜索引擎,查准率也比较低——因为冗余信息过多,且各种信息之间关系天生缺乏组织,各自为证,所以在网上找所需信息的成本越来越高——据调查很多人每周花在搜索上的时间超过6个小时。
存在这些问题的原因在于万维网现在采用的超文本标记语言(Hyper Text Markup Language,简称HTML),网页上的内容设计成专供人类浏览的,而非供计算机理解和处理的,因此无法为网民提供自动处理或分析网上数据的功能。
此外,万维网是按“网页的地址”,而非“内容的语义”来定位信息资源的(缺少语义联接),网上所有信息都是由不同的网站发布的,相同主题的信息分散在全球众多不同的服务器上,又缺少有效工具能将不同来源的相关信息综合起来,因此形成了一个个信息孤岛(其中有大量重复),查找自己所需的信息就像大海捞针一样困难。
语义网概念
不需要教条的理解语已网!在我看来,其内涵一言以蔽之——计算机能识别意义的互联网。
注:wiki上的标准概念是——通过给万维网上的文档(如:HTML)添加能够被计算机 所理解的语 义(Meta data),从而使整个互联网成为一个”通用”的信息交换媒介。
语义网的实现方式
语义网的实现方式相比它的定义来说,要发散的多——它没有像3G技术那种统一的实现标准(这点到有点像4G标准,只说传输速度到1G,而没有确定的技术规范)。因此在实现道路上可谓仁者见仁,智者见智,出现了多种多样的语义识别方法,我以自己的理解进行简单的归纳(由于我也是该领域的新兵,错误之处难免,见谅)。
语义识别的几种方法:
-
语义标注 – 采用RDF,Microformats 等语法标注原数据——最正统的方法。这种方法可看成是给词打上对应的语义标签,其目的主要是为了解决数据的互通性,比如交友社区中的朋友关系如果使用语义标注,就可帮助全网(跨不同网站的)范围内的朋友搜索(具体可参见 http://www.ibm.com/developerworks/cn/xml/x-watch/part3/index.html )。让语义 Web 如此有意义和有用的关键设计特征之一就是跨 Web 数据集间互连数据的确立。就这点而言,目前最成功的项目我认为是 Open Linked Data,它已经整理了不少领域的数据信息可供识别。
-
建立语境 — 这种方法是通过有向网的方式描述我们身边的客观世界。网络上的节点表示物理实体、概念或状态,连接节点的“边”用于表示实体的关系。通过边的链接实体间的相关性得以表示,因此相关事实可以从直接相连的节点推导出来——而且目前语境的建立多采用面向对象中的属性继承方式,因此可以对继承的属性进行演绎如三段式推理,另外甚至可以建立状态和动作的描述(后面提到的freebase使用类似方法)。 有了这种网络描述的语境(和专家系统有点像),那么就能够判断文档内容是何含义了——最简单的方法是将文档的词汇抽取出来,在各种语境网格下演算其匹配程度,最后收敛到最匹配的语境就代表了该文章的含义。
-
聚合方法 - 相比建立语境技术,聚合所采用的是基于统计的词群聚类。一般使用监督模型训练好不同语义的词群,然后分析文章的词汇主要落在那个词群中,就说明它的语义属于那个词群对应的语义。 最后识别语义方式和语境下识别有相似之处,不同之处是:前者在语境图中进行匹配,后者则是通过匹配词群中匹配。
这几种方法各有利弊,简单的说:
-
1 语义标注方法需要人为去给词汇标注语义标签,工作量很大,而且希望以后所有网页,包括已有的网页都自觉标注很不现实;另外属性标注的正确性如何确保似乎也是一个问题。
-
2 建立语境同样需要人工建立,而且很多专业须有有专业背景的人来建立,想把世界上左右领域人工建立语境,不说不可能,但可能需要相当长一段时间而;另一个问题是语境建立的正确性也只能是一个含混的标准,可能需要后期的大量修正才能确保准确。
-
3 聚合方法是采用计算机自动完成,最省事的途径,不过它的缺点也显而易见——分类一般比较粗,且计算量较大(目前应用多在几百类这个级别上)。
解决信息孤岛问题方法:
建立全网数据库——说白了就是想办法将各个信息孤岛的数据进行统一的结构化,类似于一个妄想容纳世界所有数据,以及维护其组织关系的RMDB. 这里首先需要定义数据组织结构,也就是按照实体为单位建立schame,然后从全网上抽取出对应的字段,填充实体的内容。而抽取结构数据的做法,通常采用
-
1 从结构化网站爬下已经结构化好数据,如到wiki上找数据,或专业网站(比如汽车数据,自然到汽车网站)提取现成数据.
-
2 使用自然语言处理技术,从非结构化数据中提取需要的信息。
-
3 采用web2.0的方式,让网民生成数据。
语义网目前的应用探索
首先要要强调语义网的发展刚刚起步。学术界也好,企业也好,都处于懵懂时期,没并有出现非常清晰的应用模式,更不谈赢利模式了。虽然大家心里都隐约知道这玩意必然是趋势,是摇钱树,是恐龙蛋——但是谁也没法具体说出这个恐龙蛋最后孵出的是什么样的龙!
不过,既然是好东西,那当然不缺乏第一批吃螃蟹的先行者。目前世界上已经有一些公司开始尝试意开发一些以语义网技术为背景的互联网应用,这里我根据自己的认识挑几个典型的产品讲述一些目前语义网应用的发展趋势。
1 个性化服务
互联往从以门户为主的聚众时代,发展到现在以各种论坛、垂直门户为主的分众时代。那么下一步发展是什么呢? 所有“专家”都无一例外的预测是个性化时代。
所谓个性化,说简单了就是为每个用户提供针对性的内容和服务。那么个性化的基础就是知道用户的“DNA”—— 这里所谓的用户DNA就是我们常说的用户的profile,或者说的个性特征——,从而给根据用户特性为用户定制服务(比如按兴趣推荐内容的个性化媒体,或者按照潜在购买需求推荐的商品等等)。
而目前最大的难题是如何获得用户的DNA, 想要获得用户DNA就需要获得有效的用户输入,而这种用户输入的获取排出掉流氓软件的非法窃取外(比如偷取你的浏览记录),主要是通过用户主动提交。而从用户提交的各种文档(主要是网页,邮件,文章,其次是照片和视频等)分析出用户的DNA则需要借助语义网技术对文档内容进行计算机自动识别(用人工作识别也可以,就怕是你给不起劳务费,因为信息量太大了。呵呵),这个技术点正好就是语义网所需要解决的第一个难题——语义识别。但是需要说明的是——个性化服务并非只有语义网一条道可走!比如baidu等根据用户关键词来确认用户的profile,这种情况并不需要复杂的语义分析就能完成——baidu的个性化广告和baidu知道等从一定意义上已经实现了个性化服务,要是你不知道自己去尝试一下吧。呵呵。
注,至于照片和视频的语义识别相比文字的语义识别要难的多得多,因为文字,词汇好歹是人思想直接表述的最小单元,而图像和视频严格的说是自然界对客观现实的反应,而非人思想的表述,因此对其内容识别够玄。当前的做法多是通过它周边的描述性词汇来猜测它的语义,比如宝马图片的周围难免会出现宝马相关的词句。
TWINE
语义网目前实现个性化服务的最主要应用是推荐系统——尤其以内容推荐为主。较为成功的应用当属TWINE (http://www.twine.com )。twine首页上就开宗明义的提到它提供的主要服务是:
-
发现你的兴趣
-
收集共享书签,提供网络书签服务
-
按照兴趣提供个性化推荐服务。
其中最核心的服务就在于第三点:个性化推荐。而个性化推荐前提是收集用户信息.Twine 采取两种方式完成用户信息收集。第一种是通过用户网络书签(这点和delicious,xmarks等网站无异,它们也实现站点推荐,只是方式大约是用协同过滤CF方式,而非语义识别),第二种则是通过让用户主动上传个人数据。比如自己的文档,电子邮件和YouTube视频。 如果用户愿意的话,它还能自动保存用户所访问的网页,收到或发送的邮件等等。而当twine拥有了一些数据后,它会开始分析并进行分类——这正用到了语义分析技术。所以一言一蔽之Twine内部有一个语义分析为基础的智能标签引擎,可以分析用户输入的内容,自动进行内容分类。 显而易见当你知道了用户提交内容的分类后,就知道了用户的DNA。
Twine在掌握语义的基础上具体提供了如下几个不错的服务:
-
首先可作为一个用户的个人资料自动归档系统,能将你提交的信息自动分门别类的归档整理(就像自己的个性化图书管)—— 根本不需要传统方式那样需要用户自己建立目录,或者自己打标签那么废时废力,而且也不准确统一。
-
其次,它可实现根据用户喜好给用户推荐内容,比如用户可能感兴趣的网站和网页(商品目前好像还没兜售吧)。
-
再次,它还一步瞄准了网络的社会化方向,具体的将同类用户(提交同样类别内容的人)组成了小社区圈子,实现了SNS的功能。
-
最后,它它还提供了社区内信息共享功能,让用户可以通过标签进行内容共享(搜索)。
这些尝试目前在美国已经取得了不错的效果,但是是否能博取广大用户的青睐呢,这个还需要很长的路。它所面临的最主要问题还是用户输入“过于复杂”,因此更多是高端用户使用,而广大中低端用户则不会或者没有耐心去完成需要的输入。如何降低用户使用门槛的最简单办法是减少用户输入,但是其代价则是降低了个性化能力,因此进退两难亚;或者干脆不慌不忙的等待用户提高技能,而逐步博得大众喜爱。到底如何是好,我们拭目以待的观察twine的发展吧,他所面临的问题大概是所有个性化服务网站都难以避免的难题。
2 语义搜索
语义网的最主要的需求来源大概是因为“用户对信息检索不断提高的要求,和当前落后的搜索工具之间的矛盾" ——偷用一句我们的政治用语。从长期看法一定是这样的。 不过说实话,我看当前基于字符串匹配的web搜索引擎对于大多数人来说其实还是很够用的。但也要承认有些高端用户或者很低端的用户用现在的搜索引擎就有些吃力(这里所谓的高端或者低端并非用户社会地位,而是说互联网使用技能和耐心而言),比如很低端用户不会筛选关键词,因此往往面对数百页的搜索结果无所适从。对他们来说可能更希望采用问答的方式获得准确结果!而对于一些高端用户,比如一些分析师或者做写报告的主,则希望根据某个主数题获取网上各种维度的相关数据,这些多维数据可不可能在一个网页上全部出现(一个网站内也不会全面),因此需要搜索引擎可根据语义链接,检索全网上的相关数据为其所用。
低端客户要求的语义搜索有的地方称其为”语义分析能力的搜索引擎”(semantically enabled search engine),其主要特点是利用自然语言处理,模式识别等技术为用户提高搜索体验。它支持用户用提问等方式,检索需要的信息,但返回的结果仍然是限于一篇网页的内容。而高端用户则看中跨信息孤岛的全网信息索引,这点更像是检索语义数据库。
因此我下面提到的一些引用就是按此层次进行归纳,先来看看抑郁分析能力的搜索引擎。在该领域我将给出三个有趣的公司。
Powerset
这个最有名(因为被互联网界的大头微软1亿美元买走了),其技术核心是用自然语言技术尝试理解句子的含义并进行匹配。它的数据源目前主要来自wiki,也就是说你可用生活中的问题去进行搜索。powerset会分析你的问题,并在wiki中找到对应答案的句子给你。—— 另外为了给用户提供更好的概况总结,它也结合了一些freebase(后面会谈到它)的结构化数据予以展示。
Cognition
这个引擎和powerset很像,特长都是自然语言处理。初期congition似乎提供了任意内容的搜索,而此刻好像更加专注——只限于提供法律,健康,wiki等有限领域的语义搜索(最赚钱的几个先做)。
自己去做个实验吧,比如搜索 who write linux kernel? 分别在两个网站上进行搜索,看看他们的结果你是否满意呢?
http://www.powerset.com/
http://wikipedia.cognition.com
Evri
Evri并没有像上面两个网站那样提供自然语言搜索为主,而是个很不错的内容组织引擎。它的核心技术并不是一个单纯的搜索引擎,因为它对对搜索结果并非不做任何加工的返回给用户,而是添加了一个复杂的语义层以强调不同搜索内容之间的关系。它的技术优势在于对搜索结果的无序内容,进行挖掘和分类——补充一下,在一个页面内对搜索内容提供概括总结似乎是目前搜索结果展示的一个趋势——而其对语义分类中最突出的地方是,强调了和结果主题相关的人,事,地几个重要维度。比如去查obama,结果中则会给出和他的基本个人情况,以及何时和地参与的事件等分类信息。
http://www.evri.com
语义搜索思考
语义搜索和关键字搜索还有一个比较大不同在于,语义搜索一般需要提供语境(或者说是知识架构),也就如同我们理解别人言语就需要知道其说话的上下文一样。断章取义的理解孤立的词往往词不达意,比如大家最爱举的例子,如果仅仅查询apple这个词,你到底是给
apple手机的内容呢,还是给真正吃的大苹果咨询呢?因此用户必须给出语境信息!那么如何给呢?机械的方式可能让用户选择语境,比如让用户搜索apple时,选择是植物类或是手机类(具体方式一般都由UE提供给用户方便选择),然后做定夺。如果智能一些的方法就是分析用户的提问,从中确定语境。
举个网上看到的不大恰当的例子吧——一个女孩希望找个男朋友,所以就把“帅” ,“有很多钱”,“有大房子”,“强壮” 等关键词输入搜索引擎,结果找到的答案是“奥特曼在银行里下象棋”这个笑话。笑完之后,我们来分析一下:帅对应到了下象棋;有钱,大房子对应到了银行;强壮对应到了奥特曼,从这几点上看都有语义分析的痕迹(可不是简单的关键词匹配呀),但却发现根本不是想要的——想要的自然是玉树临风,英俊潇洒,且少年多金的男朋友。
这里的问题就是处在语境不清,如果智能的语义引擎,就应该根绝上述的词汇分析出其语境是找男朋友。再发散思维一下,如果我们知道用户是个情窦初开的少女,那么就可更准确的提供给她个性化的语义搜索啦。那样就更不会错啦。哈哈。
3 知识库
下面我们来看上文提到的所谓高端用户需要的语义链接如何实现和应用。实现全网数据的语义链接其实就类似实现一个大的关系数据库——两个特点:1 大到了全体互联网;2 结构化或者半结构化的数据组织,可以方便进行语义查询。
很多人称其为“全网知识库”或者语义知识库。这里最出色莫过于
Freebase
它可以算作是目前世界上最大的“语义数据库”。要建立这样一个泛化的(是相对那些在特定领域定义了一些领域类的语义数据库,比如教学领域、地理领域)语义数据库,首先需要定义一个合理的数据组织方法论!
Freebase的方法论是——基本的数据层次划分为:域,类型,属性和话题(或者叫条目)。
-
域——是一个表示范畴的信息类别,例如旅游,战争,电影,体育等;
-
类型——是为一组或者称为一类具有共同特征的事物给出的信息抽象,比如人,演员,汽车等,其实很多地方叫它实体,类似于面向对象中的一个对象。
-
属性——是类型里的一个特定信息元素,如电影演员类型就有三个属性,电影演员,配音演员及IMDB分类等——这点类似于对象中的属性。前面几点都很直观,朴素(需要做的就是定义实体的schema,也就是包含哪些属性,这个工作多是人工完成的,对于专业领域可能还需要专业人员完成才准确)。
-
条目——最精彩的地方是最有一个概念——条目,它可以理解为是类型的实例(感觉是用面向对象的概念描述了信息之间的组织关系!),因此是具有对应类型属性的实例值。而各话题并非孤立的,它们之间存在各种逻辑关联(人为建立的)——它是一个信息集散地,能连接倒其他的域或者话题,他们之间的连接纽带,就是类型。类型之间按照逻辑定义了类似于网状的关系结构,不断蔓延开来,将全网信息无所不在的联系起来。
想想它的规模,真有点疯狂。需要赞扬这种信息组织方法,它清晰,适应性高,可不断演进。但愿freebase能坚持下去!
补充一点, freebase获得数据的途径如同前面所提到的3种方式。它支持web2.0,允许用户输入,比如我输入我老家xi'an可查询到它的很多结构化信息,而且我可以自己添加新的信息,比如西安的小吃,名胜等等。扩充性很棒吧!
注:Freebase的具体盈利方式,主要是通过给其他网站提供数据服务。具体到freebase网站上去看吧!
Wolfram Alpha
有地方称其为”知识引擎“(为是绘图计算器、参考书图书馆、以及搜寻引擎的综合体),可见其在知识库基础上还添加了一些分析推理功能。这个引擎的由wolfram(史蒂芬·沃尔弗拉姆 )主持开发——这个人很牛,是个计算机科学家(我们都是工匠罢了,能称得上科学家又有几人呀),他试图通过把数量庞大的人类知识片段,与Mathematica用于计算、推理的众多simple program结合在一起,来完成对我们这个复杂世界的建模。可谓雄心勃勃呀!
目前Wolfram|Alpha 能帮助用户实现基于其输入的关键词或问题的统计学工作 ,除科学领域外,它还提供包括金融、技术、地理、天气、烹调、商业、旅行、人类、音乐等领域的知识和计算结果。
推理的前提是有足够的结构化数据,因此从这个方面来说它也需要首先建立庞大的全网知识库。虽然没有公布数据如何组织的,我想大概和freebase等都有类似之处吧。对于这个网站(www.wolframalpha.com),我建议大家去玩玩。你定会发现它许多惊人之处,纵然很多人认为其华而不实。
你可搜索下面的一些东东,结果一定挺不错
beijing
Sin(x)
China GDP
How many people in China
uncle's uncle's brother's son
未来什么样呢?
正如前文所说语义网的应用刚刚起步,虽然很多大师都拍着胸口预测她是大事所趋,是历史的必然选择,但谁也不能准确预测需要多久能达到此种传说中的境界。 不过辩证的看她,其实这种不确定性也正说明了语义网内涵的博大精深,可挖掘,可想象的空间太大太多,以至于目前没人能指明它的发展道路和应用方向。这就好比一张白纸,才可画出最美好的图画一般。
所以对她未来目标的描述,我一个工匠不敢自作主张,妄自猜测。但有一点似乎已经明确——那就是互联网发展趋势必将向两个纬度发展(允许我剽窃一个报告的图片):
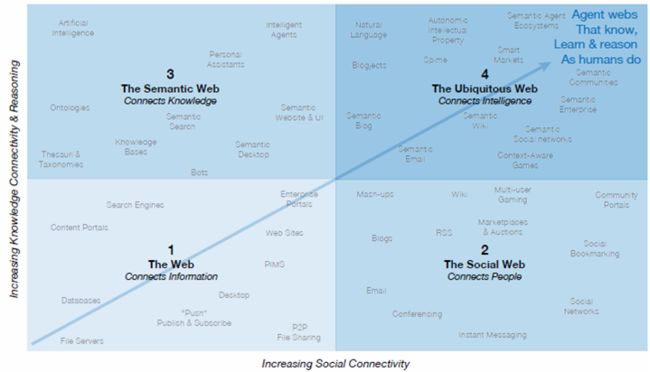
-
1 向社会化发展——连接人与人
-
2 向语义化发展——连接知识与知识
而最终的目标似乎是The Ubiquitous Web”(无处不在的网),具体如何定义,我也说不清楚,感觉似乎那时网络和人一样的智能,懂得思考,学习,而无所不知,无所不能。呵呵,我们仅仅向往一下就行,因为这种目标可类比共产主义,都是可以预见的近期渴望不可及的理想。但仍然但愿那一天早日来到!