简要分析C中结构的位域成员
C/C++提供了一个内嵌的特征来访问字节中的为,即位域。位域很有用,因为:
1)如果存储空间受限,可以在一个字节中存储多个布尔变量(真/假)。
2)某些设备传输被编码为一个字节中的为的状态信息。
3) 某些加密程序需要访问字节中的位。
C/C++使用基于结构的方法来访问位。事实上,位域是结构成员的特殊类型,它以位(bit)为单位定义域的长度。
位域定义的一般形式如下(C++风格)
struct struct-type-name
{
type name1:length;
type name2:length;
....
type nameN:length;
} variable_list;
type是位域的类型,应该是_Bool(C99)、char、int和枚举等整型类型。
length是位域的长度,要求是非负整型常量或表达式,并且值不能大于type所对应的位宽度。例如,char bit_field:9是无法通过编译的。
另外,长度为1的位域应该声明为unsigned,因为单个位不能有符号。
给位域赋值与给其他任何类型的结构成员赋值一样。
位域并不一定要命名,这样可以跳过无用位,方便的使用希望的位。
位域变量的使用有一些限制:
1).不能使用位域变量的地址。
2).位域变量不能构成数组。
3).位域变量不能声明为静态的。
特别的,位域的使用与机器的比特序有关。
关于比特序和字节序之间的区别和联系,可以参考下文:
http://www.linuxjournal.com/article/6788
我的blog上有该文的翻译版,不过本人乃业余翻译者,不对翻译内容和质量作任何承诺和保证。
http://blog.csdn.net/lovekatherine/archive/2007/04/14/1564731.aspx
后文重点分析位域与比特序的关系,以下面的小程序为例。
 #include
<
stdio.h
>
#include
<
stdio.h
>
#include
<
string
.h
>
typedef
struct
_bitdomain
 {
{
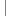
unsigned char a:3;
unsigned char b:5;
 }
X;
}
X;
void
display (
char
dst)
{
int i;
unsigned int m=128;
while(m)
 {
{
printf("%u",(unsigned char)dst/m);
dst%=m;
m/=2;
 }
}
printf(", ");
}
int
main ()
{
X x;
memset ( &x,0x0,sizeof(x));
*( unsigned char *) &x=0xb4;
printf("sizf of struct X :%d ", sizeof(x) );
int size=sizeof(x);
char * ch=(char*) &x;
int i;
for(i=0;i<size;i++)
{
display( ch[i]);
}
printf(" ");
printf("x.a=%u ",(unsigned char )x.a);
printf("x.b=%u ",(unsigned char )x.b);
return 1;
}
运行环境:i386+ubuntu7.04+gcc4.1.2
程序的输出结果为:
x=10110100,
x.a=100 (0x44),
x.b=10110(0xb),
下面分析程序的输出:
首先,结构X的大小为1字节。
其次,i386架构下的字节序和比特序为小端,即高位字节(比特)存放在内存的高地址。
可知x=0xb4在内存中的布局如下:
bit 7 6 5 4 3 2 1 0
value 1 0 1 1 0 1 0 0
又根据Kevin定理#2: “在 C 中一个包含位域的结构中,如果位域 A 在位域 B 之前定义,那么位域 A 所占据的内存空间永远低于 B 所占用的内存空间。”
可知x.a 对应位2~位0 ,x.b对应位7~位3,因此,按照高地址对应高位的关系,有
x.a=100, x.b=10110
对上述程序进行局部修改,看看在位域长度超出8(1byte)时会是什么情形。
#include
<
stdio.h
>
#include
<
string
.h
>
typedef
struct
_bitdomain
{
unsigned short y:12;
unsigned short z:4;
}
X;
void
display (
char
dst)
{
int i;
unsigned int m=128;
while(m)
{
printf("%u",(unsigned char)dst/m);
dst%=m;
m/=2;
}
printf(", ");
}
int
main ()
{
X x;
memset ( &x,0x0,sizeof(x));
*( unsigned short *) &x=0x32b4;
printf("sizf of struct X :%d ", sizeof(x) );
int size=sizeof(x);
char * ch=(char*) &x;
int i;
for(i=0;i<size;i++)
{
display( ch[i]);
}
printf(" ");
printf("x.y=%x ",(unsigned short)x.y);
printf("x.z=%x ",(unsigned short)x.z);
return 1;
}
程序的输出结果为:
x=(0x32b4)
x.y=0x2b4
x.z=0x3
(其中y、z分别定义为 unsigned short y:12和unsigned short z:4)
和前例一样,仍然从x的内存布局入手。
(不失一般性,假设x的地址为0X1000)
addr 0x1000 0x1001
bit 7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0
vlaue 1 0 1 1 0 1 0 0 0 0 1 1 0 0 1 0
同样依据Kevin定理#2,可知x.y对应地址0x1000的8bit和0x1001的位0~位3,x.z对应地址0x1001的位4~位7。
因此,按照高地址对应高比特和高字节的关系,可得出: ` x.y=001010110100=0x2b4,x.z=0011=0x3
1)如果存储空间受限,可以在一个字节中存储多个布尔变量(真/假)。
2)某些设备传输被编码为一个字节中的为的状态信息。
3) 某些加密程序需要访问字节中的位。
C/C++使用基于结构的方法来访问位。事实上,位域是结构成员的特殊类型,它以位(bit)为单位定义域的长度。
位域定义的一般形式如下(C++风格)
struct struct-type-name
{
type name1:length;
type name2:length;
....
type nameN:length;
} variable_list;
type是位域的类型,应该是_Bool(C99)、char、int和枚举等整型类型。
length是位域的长度,要求是非负整型常量或表达式,并且值不能大于type所对应的位宽度。例如,char bit_field:9是无法通过编译的。
另外,长度为1的位域应该声明为unsigned,因为单个位不能有符号。
给位域赋值与给其他任何类型的结构成员赋值一样。
位域并不一定要命名,这样可以跳过无用位,方便的使用希望的位。
位域变量的使用有一些限制:
1).不能使用位域变量的地址。
2).位域变量不能构成数组。
3).位域变量不能声明为静态的。
特别的,位域的使用与机器的比特序有关。
关于比特序和字节序之间的区别和联系,可以参考下文:
http://www.linuxjournal.com/article/6788
我的blog上有该文的翻译版,不过本人乃业余翻译者,不对翻译内容和质量作任何承诺和保证。
http://blog.csdn.net/lovekatherine/archive/2007/04/14/1564731.aspx
后文重点分析位域与比特序的关系,以下面的小程序为例。
运行环境:i386+ubuntu7.04+gcc4.1.2
程序的输出结果为:
x=10110100,
x.a=100 (0x44),
x.b=10110(0xb),
下面分析程序的输出:
首先,结构X的大小为1字节。
其次,i386架构下的字节序和比特序为小端,即高位字节(比特)存放在内存的高地址。
可知x=0xb4在内存中的布局如下:
bit 7 6 5 4 3 2 1 0
value 1 0 1 1 0 1 0 0
又根据Kevin定理#2: “在 C 中一个包含位域的结构中,如果位域 A 在位域 B 之前定义,那么位域 A 所占据的内存空间永远低于 B 所占用的内存空间。”
可知x.a 对应位2~位0 ,x.b对应位7~位3,因此,按照高地址对应高位的关系,有
x.a=100, x.b=10110
对上述程序进行局部修改,看看在位域长度超出8(1byte)时会是什么情形。
程序的输出结果为:
x=(0x32b4)
x.y=0x2b4
x.z=0x3
(其中y、z分别定义为 unsigned short y:12和unsigned short z:4)
和前例一样,仍然从x的内存布局入手。
(不失一般性,假设x的地址为0X1000)
addr 0x1000 0x1001
bit 7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0
vlaue 1 0 1 1 0 1 0 0 0 0 1 1 0 0 1 0
同样依据Kevin定理#2,可知x.y对应地址0x1000的8bit和0x1001的位0~位3,x.z对应地址0x1001的位4~位7。
因此,按照高地址对应高比特和高字节的关系,可得出: ` x.y=001010110100=0x2b4,x.z=0011=0x3