CFS调度的总结 - (单rq vs 多rq)
近来和一个师兄谈到了CFS调度算法,我以前一直以为CFS的任务就绪队列是全局的,即有全局唯一的rq,但是师兄说是Per-CPU的,于是回来又仔细分析了下代码,发现果然是Per-CPU的。由这个简单的问题先来说说我为啥认为rq是全局唯一的,然后总结下CFS调度算法的一些关键点。
一、Per-CPU的rq和全局唯一的rq
在Linux-2.6内核时代,为了更好的支持多核,Linux调度器普遍采用了per-cpu的run queue,从而克服了多CPU系统中,全局唯一的run queue由于资源的竞争而成为了系统瓶颈的问题,因为在同一时刻,一个CPU访问run queue时,其他的CPU即使空闲也必须等待,大大降低了整体的CPU利用率和系统性能。当使用per-CPU的run queue之后,每个CPU不再使用大内核锁,从而大大提高了并行处理的调度能力。
有利必有弊,必须辩证的来分析自然界的现象。我开始认为全局的rq比per-cpu的优势在来源于分布式系统中的”排队论“,即典型的银行排队系统,在有一个取票口,多个服务口的情况下,系统才能具有最大的吞吐率(具体参见排队论的相关文章),同时,per-CPU还会产生一些可调度性的NP问题。除了这些理论的问题,查阅了相关的资料后,per-CPU的run queue还存在以下实际的问题:
采用per-cpu的run queue所带来的好处会被追求公平性的load balance代码所抵消。在目前的CFS调度器中,每颗CPU只维护本地run queue中所有进程的公平性,为了实现跨CPU的调度公平性,CFS必须定时进行 load balance,将一些进程从繁忙的CPU的run queue中移到其他空闲的run queue中。这个load balance的过程需要获得其他run queue的锁,这种操作降低了多运行队列带来的并行性,并且在复杂情况下,这种因 load balance而引入的footprint 将非常可观。
当然,load balance引入的加锁操作依然比全局锁的代价要低,这种代价差异随着CPU个数的增加而更加显著。但请您注意,假若系统中的CPU个数有限时,多run queue的优势便不明显了。而采用单一队列之后,每一个需要调度的新进程都可以在全局范围内查找最合适的CPU,而无需CFS那样等待load balance代码来决定,这减少了多CPU之间裁决的延迟,最终的结果是更小的调度延迟。
当然,load balance引入的加锁操作依然比全局锁的代价要低,这种代价差异随着CPU个数的增加而更加显著。但请您注意,假若系统中的CPU个数有限时,多run queue的优势便不明显了。而采用单一队列之后,每一个需要调度的新进程都可以在全局范围内查找最合适的CPU,而无需CFS那样等待load balance代码来决定,这减少了多CPU之间裁决的延迟,最终的结果是更小的调度延迟。
其次,为了维护多CPU上的公平性,CFS采用了负载平衡机制,这些复杂代码抵消了per cpu queue曾带来的好处。
下面的数据是新墨西哥大学的 Taylor Groves, Je Knockel, Eric Schulte对采用per-CPU的run queue和全局唯一的run queue做的一个响应时间的试验。
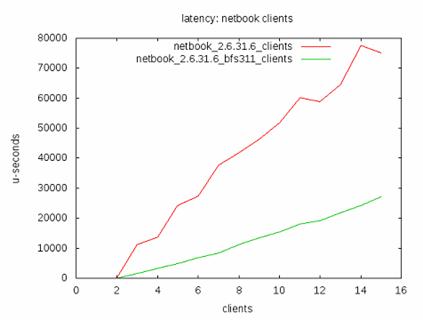
从上图可以看出采用全局唯一单队列的BFS调度算法的响应时间明显优于采用多per-CPU队列的CFS调度算法,说明CFS更适于交互式系统,即桌面系统。(当然,并不是说BFS就优于CFS,毕竟不同的应用场景各有优势,但是CFS考虑的确实太多了,想支持各种情况- CFS 的目标是支持从桌面到高端服务器的所有应用场景,这种大而全的设计思路导致其必须做一些实现上的折中)。
二、CFS关键点总结
1. 虚拟运行时间(vruntime)变化公式
- vruntime += delta * (1024/se.load.weight);
-
- /*delta:进程实际增加的运行时间,即从调度实体被选择获得cpu到调度实体放弃CPU这段时间*/
结论:在实际运行时间相同的情况下,调度实体权重越大,vruntime增加的越慢。
2. 进程的理想运行时间计算公式
- ideal_time = slice *(se.load.weight/cfs_rq.load.weight);
- /*slice为CFS运行队列中所有进程运行一遍所需要的时间*/
- /*slice的经验计算公式如下:*/
- if(cfs_rq->nr_running > 5)
- slice = 4 * cfs_rq->nr_running;
- else
- slice = 20; /*单位ms*/
3. CFS调度时机
在有了上面几个计算公式之后,就可以总结出CFS调度算法的几个调度时机:
(1) 调度实体的状态转换的时刻:进程终止、进程睡眠等,广义上还包括进程的创建(fork);
(2) 当前调度实体的时机运行时间大于理想运行时间(delta_exec > ideal_runtime),这一步在时钟中断 处理函数中完成;
(3) 调度实体主动放弃CPU,直接调度schedule函数,放弃CPU
(4) 调度实体从中断、异常及系统调用返回到用户态时,回去检查是否需要调度;