基于S3C2440的嵌入式Linux驱动——SPI子系统解读(四)
本系列文章对Linux设备模型中的SPI子系统进行讲解。SPI子系统的讲解将分为4个部分。
第一部分,将对SPI子系统整体进行描述,同时给出SPI的相关数据结构,最后描述SPI总线的注册。基于S3C2440的嵌入式Linux驱动——SPI子系统解读(一)
第二部分,该文将对SPI的主控制器(master)驱动进行描述。 基于S3C2440的嵌入式Linux驱动——SPI子系统解读(二)
第三部分,该文将对SPI设备驱动,也称protocol 驱动,进行讲解。基于S3C2440的嵌入式Linux驱动——SPI子系统解读(三)
第四部分,即本篇文章,通过SPI设备驱动留给用户层的API,我们将从上到下描述数据是如何通过SPI的protocol 驱动,由bitbang 中转,最后由master驱动将
数据传输出去。
本文属于第四部分。
7. write,read和ioctl综述
在spi设备驱动层提供了两种数据传输方式。一种是半双工方式,write方法提供了半双工读访问,read方法提供了半双工写访问。另一种就是全双工方式,ioctl调用将同时完成数据的传送与发送。
在后面的描述中,我们将对write和ioctl方法做出详细的描述,而read方法和write极其相似,将不多做介绍。
接下来首先看看write方法是如何实现的。
8. write方法
8.1 spidev_write
在用户空间执行open打开设备文件以后,就可以执行write系统调用,该系统调用将会执行我们提供的write方法。代码如下:
下列代码位于drivers/spi/spidev.c中。
/* Write-only message with current device setup */
static ssize_t
spidev_write(struct file *filp, const char __user *buf,
size_t count, loff_t *f_pos)
{
struct spidev_data *spidev;
ssize_t status = 0;
unsigned long missing;
/* chipselect only toggles at start or end of operation */
if (count > bufsiz) /*数据大于4096字节*/
return -EMSGSIZE;
spidev = filp->private_data;
mutex_lock(&spidev->buf_lock);
/*将用户层的数据拷贝至buffer中,buffer在open方法中分配*/
missing = copy_from_user(spidev->buffer, buf, count);
if (missing == 0) {
status = spidev_sync_write(spidev, count);
} else
status = -EFAULT;
mutex_unlock(&spidev->buf_lock);
return status;
}在这里,做的事情很少,主要就是从用户空间将需要发送的数据复制过来。然后调用spidev_sync_write。
8.2 spidev_sync_write
下列代码位于drivers/spi/spidev.c中。
static inline ssize_t
spidev_sync_write(struct spidev_data *spidev, size_t len)
{
struct spi_transfer t = {
.tx_buf = spidev->buffer,
.len = len,
};
struct spi_message m;
spi_message_init(&m);
spi_message_add_tail(&t, &m);
return spidev_sync(spidev, &m);
}
static inline void spi_message_init(struct spi_message *m)
{
memset(m, 0, sizeof *m);
INIT_LIST_HEAD(&m->transfers); /*初始化链表头*/
}
spi_message_add_tail(struct spi_transfer *t, struct spi_message *m)
{
list_add_tail(&t->transfer_list, &m->transfers);/*添加transfer_list*/
}
在这里,创建了transfer和message。spi_transfer包含了要发送数据的信息。然后初始化了message中的transfer链表头,并将spi_transfer添加到了transfer链表中。也就是以spi_message的transfers为链表头的链表中,包含了transfer,而transfer正好包含了需要发送的数据。由此可见message其实是对transfer的封装。最后,调用了spidev_sync,并将创建的spi_message作为参数传入。
8.3 spidev_sync
下列代码位于drivers/spi/spidev.c中。
static ssize_t
spidev_sync(struct spidev_data *spidev, struct spi_message *message)
{
DECLARE_COMPLETION_ONSTACK(done); /*创建completion*/
int status;
message->complete = spidev_complete;/*定义complete方法*/
message->context = &done; /*complete方法的参数*/
spin_lock_irq(&spidev->spi_lock);
if (spidev->spi == NULL)
status = -ESHUTDOWN;
else
status = spi_async(spidev->spi, message);/*异步,用complete来完成同步*/
spin_unlock_irq(&spidev->spi_lock);
if (status == 0) {
wait_for_completion(&done); /*在bitbang_work中调用complete方法来唤醒*/
status = message->status;
if (status == 0)
status = message->actual_length; /*返回发送的字节数*/
}
return status;
}在这里,初始化了completion,这个东东将实现write系统调用的同步。在后面我们将会看到如何实现的。
随后调用了spi_async,从名字上可以看出该函数是异步的,也就是说该函数返回后,数据并没有被发送出去。因此使用了wait_for_completion来等待数据的发送完成,达到同步的目的。
8.4 spi_async
下列代码位于drivers/spi/spi.h中。
/**
* spi_async - asynchronous SPI transfer
* @spi: device with which data will be exchanged
* @message: describes the data transfers, including completion callback
* Context: any (irqs may be blocked, etc)
*
* This call may be used in_irq and other contexts which can't sleep,
* as well as from task contexts which can sleep.
*
* The completion callback is invoked in a context which can't sleep.
* Before that invocation, the value of message->status is undefined.
* When the callback is issued, message->status holds either zero (to
* indicate complete success) or a negative error code. After that
* callback returns, the driver which issued the transfer request may
* deallocate the associated memory; it's no longer in use by any SPI
* core or controller driver code.
*
* Note that although all messages to a spi_device are handled in
* FIFO order, messages may go to different devices in other orders.
* Some device might be higher priority, or have various "hard" access
* time requirements, for example.
*
* On detection of any fault during the transfer, processing of
* the entire message is aborted, and the device is deselected.
* Until returning from the associated message completion callback,
* no other spi_message queued to that device will be processed.
* (This rule applies equally to all the synchronous transfer calls,
* which are wrappers around this core asynchronous primitive.)
*/
static inline int
spi_async(struct spi_device *spi, struct spi_message *message)
{
message->spi = spi; /*指出执行transfer的SPI接口*/
return spi->master->transfer(spi, message); /*即调用spi_bitbang_transfer*/
}
这个函数仅仅保存了spi_device信息后,然后调用了master的transfer方法,该方法在spi_bitbang_start中定义为spi_bitbang_transfer。
8.5 spi_bitbang_transfer
下列代码位于drivers/spi/spi_bitbang.c中。
/**
* spi_bitbang_transfer - default submit to transfer queue
*/
int spi_bitbang_transfer(struct spi_device *spi, struct spi_message *m)
{
struct spi_bitbang *bitbang;
unsigned long flags;
int status = 0;
m->actual_length = 0;
m->status = -EINPROGRESS;
bitbang = spi_master_get_devdata(spi->master);
spin_lock_irqsave(&bitbang->lock, flags);
if (!spi->max_speed_hz)
status = -ENETDOWN;
else {
/*下面的工作队列和queue在spi_bitbang_start函数中初始化*/
list_add_tail(&m->queue, &bitbang->queue); /*将message添加到bitbang的queue链表中*/
queue_work(bitbang->workqueue, &bitbang->work); /*提交工作到工作队列*/
}
spin_unlock_irqrestore(&bitbang->lock, flags);
return status;
}
这里将message添加到了bitbang的queue链表中。然后提交了一个工作到工作队列,随后函数返回到spi_async,又返回到spidev_sync中。为方便将spidev_sync的部分代码列出:
status = spi_async(spidev->spi, message);/*异步,用complete来完成同步*/
spin_unlock_irq(&spidev->spi_lock);
if (status == 0) {
wait_for_completion(&done); /*在bitbang_work中调用complete方法来唤醒*/
status = message->status;
if (status == 0)
status = message->actual_length; /*返回发送的字节数*/
}
return status;
当spi_async函数返回后,需要发送的数据已经通过工作的形式添加到了工作队列,在稍后的工作执行时,将完成数据的发送。随后调用了wait_for_completion等待数据的发送完成。到此,可以看出completion的使用是用来完成同步I/O的
8.6 bitbang_work
在上一节最后添加了工作bitbang->work到工作队列中,在过一段时候后,内核将以进程执行该work。而work即为在spi_bitbang_start中定义的bitbang_work函数。我们来看下这个函数。
下列代码位于drivers/spi/spi_bitbang.c中。
/*
* SECOND PART ... simple transfer queue runner.
*
* This costs a task context per controller, running the queue by
* performing each transfer in sequence. Smarter hardware can queue
* several DMA transfers at once, and process several controller queues
* in parallel; this driver doesn't match such hardware very well.
*
* Drivers can provide word-at-a-time i/o primitives, or provide
* transfer-at-a-time ones to leverage dma or fifo hardware.
*/
static void bitbang_work(struct work_struct *work)
{
struct spi_bitbang *bitbang =
container_of(work, struct spi_bitbang, work); /*获取spi_bitbang*/
unsigned long flags;
spin_lock_irqsave(&bitbang->lock, flags); /*自旋锁加锁*/
bitbang->busy = 1; /*bitbang忙碌*/
while (!list_empty(&bitbang->queue)) { /*有spi_message*/
struct spi_message *m;
struct spi_device *spi;
unsigned nsecs;
struct spi_transfer *t = NULL;
unsigned tmp;
unsigned cs_change;
int status;
int (*setup_transfer)(struct spi_device *,
struct spi_transfer *);
m = container_of(bitbang->queue.next, struct spi_message,/*获取spi_message*/
queue);
list_del_init(&m->queue); /*以获取spi_message,删除该spi_message*/
spin_unlock_irqrestore(&bitbang->lock, flags);/*释放自旋锁*/
/* FIXME this is made-up ... the correct value is known to
* word-at-a-time bitbang code, and presumably chipselect()
* should enforce these requirements too?
*/
nsecs = 100;
spi = m->spi;
tmp = 0;
cs_change = 1;
status = 0;
setup_transfer = NULL;
/*遍历,获取所有的spi_transfer*/
list_for_each_entry (t, &m->transfers, transfer_list) {
/* override or restore speed and wordsize */
if (t->speed_hz || t->bits_per_word) { /*如果这两个参数有任何一个已经设置了,本例中没有定义*/
setup_transfer = bitbang->setup_transfer;
if (!setup_transfer) {
status = -ENOPROTOOPT;
break;
}
}
if (setup_transfer) { /*本例中为NULL*/
status = setup_transfer(spi, t);
if (status < 0)
break;
}
/* set up default clock polarity, and activate chip;
* this implicitly updates clock and spi modes as
* previously recorded for this device via setup().
* (and also deselects any other chip that might be
* selected ...)
*/
if (cs_change) { /*初值为1*/
bitbang->chipselect(spi, BITBANG_CS_ACTIVE);/*即调用s3c24xx_spi_chipsel,激活CS信号,写寄存器,设置SPI模式*/
ndelay(nsecs); /*延迟100纳秒*/
}
cs_change = t->cs_change; /*保存cs_change*/
if (!t->tx_buf && !t->rx_buf && t->len) { /*检查参数*/
status = -EINVAL;
break;
}
/* transfer data. the lower level code handles any
* new dma mappings it needs. our caller always gave
* us dma-safe buffers.
*/
if (t->len) {
/* REVISIT dma API still needs a designated
* DMA_ADDR_INVALID; ~0 might be better.
*/
if (!m->is_dma_mapped)
t->rx_dma = t->tx_dma = 0; /*不使用DMA*/
status = bitbang->txrx_bufs(spi, t); /*即调用s3c24xx_spi_txrx,开始发送数据,status为已发送数据的大小*/
}
if (status > 0)
m->actual_length += status; /*保存已发送字节*/
if (status != t->len) { /*要求发送和已发送的大小不同*/
/* always report some kind of error */
if (status >= 0)
status = -EREMOTEIO;
break;
}
status = 0;
/* protocol tweaks before next transfer */
if (t->delay_usecs)
udelay(t->delay_usecs); /*延迟*/
if (!cs_change)/*判断是否需要禁止CS,为1表示要求在两次数据传输之间禁止CS*/
continue;
if (t->transfer_list.next == &m->transfers) /*没有transfer*/
break;
/* sometimes a short mid-message deselect of the chip
* may be needed to terminate a mode or command
*/
ndelay(nsecs); /*延迟*/
bitbang->chipselect(spi, BITBANG_CS_INACTIVE); /*禁止CS*/
ndelay(nsecs);
} /*遍历spi_transfer结束*/
m->status = status;
m->complete(m->context); /*调用complete,一个message处理完毕*/
/* restore speed and wordsize */
if (setup_transfer)
setup_transfer(spi, NULL);
/* normally deactivate chipselect ... unless no error and
* cs_change has hinted that the next message will probably
* be for this chip too.
*/
if (!(status == 0 && cs_change)) {
ndelay(nsecs);
bitbang->chipselect(spi, BITBANG_CS_INACTIVE); /*禁止CS*/
ndelay(nsecs);
}
spin_lock_irqsave(&bitbang->lock, flags);
}
bitbang->busy = 0;
spin_unlock_irqrestore(&bitbang->lock, flags);
}本函数中,调用了两个方法bibang->chipselect和bitbang->txrx_bufs,这两个方法实际调用了s3c24xx_spi_chipsel和s3c24xx_spi_txrx函数,这两个函数都是master驱动层提供的函数。
s3c24xx_spi_chipsel已经在4.2.2节中给出,该函
数设置控制寄存器并激活CS信号。s3c24xx_spi_txrx函数的实参t,即为spi_transfer,函数完成该spi_transfer中数据的发送,并返回已发送的字节数。然后,判断是否需要禁止CS。接着遍历到下一个spi_transfer,再次发送数据。当所
有spi_transfer发送完成以后,将调用complete方法,从而让在spidev_sync函数中等待completion的函数返回。下面,先来来看下数据是怎么发送出去的,也就是s3c24xx_spi_txrx函数。最后,看看complete方法。
8.7 s3c24xx_spi_txrx 和s3c24xx_spi_irq
下列代码位于deivers/spi/s3c24xx.c。
static inline unsigned int hw_txbyte(struct s3c24xx_spi *hw, int count)
{
return hw->tx ? hw->tx[count] : 0; /*发送缓冲区指针是否为空,空则发送0*/
}
static int s3c24xx_spi_txrx(struct spi_device *spi, struct spi_transfer *t)/*bitbang.txrx_bufs方法*/
{
struct s3c24xx_spi *hw = to_hw(spi);
dev_dbg(&spi->dev, "txrx: tx %p, rx %p, len %d\n",
t->tx_buf, t->rx_buf, t->len);
/*保存transfer相关数据到s3c24xx_sp结构中*/
hw->tx = t->tx_buf;
hw->rx = t->rx_buf;
hw->len = t->len;
hw->count = 0;
init_completion(&hw->done); /*初始化completion*/
/* send the first byte */ /*发送第一个数据,tx[0]*/
writeb(hw_txbyte(hw, 0), hw->regs + S3C2410_SPTDAT);
wait_for_completion(&hw->done);/*等待completion*/
return hw->count; /*返回发送的字节数*/
}
static irqreturn_t s3c24xx_spi_irq(int irq, void *dev)
{
struct s3c24xx_spi *hw = dev;
unsigned int spsta = readb(hw->regs + S3C2410_SPSTA);/*获取状态寄存器*/
unsigned int count = hw->count;
if (spsta & S3C2410_SPSTA_DCOL) { /*发生错误*/
dev_dbg(hw->dev, "data-collision\n");
complete(&hw->done); /*唤醒等待complete的进程*/
goto irq_done;
}
if (!(spsta & S3C2410_SPSTA_READY)) {/*未就绪*/
dev_dbg(hw->dev, "spi not ready for tx?\n");
complete(&hw->done); /*唤醒等待complete的进程*/
goto irq_done;
}
hw->count++;/*增加计数*/
if (hw->rx)
hw->rx[count] = readb(hw->regs + S3C2410_SPRDAT);/*读取数据*/
count++; /*增加计数*/
if (count < hw->len) /*未发送完毕,则继续发送*/
writeb(hw_txbyte(hw, count), hw->regs + S3C2410_SPTDAT);
else
complete(&hw->done); /*发送完毕,唤醒等待complete的进程*/
irq_done:
return IRQ_HANDLED;
} 在s3c24xx_spi_txrx函数中,首先发送了待发送数据中的第一个字节,随后就调用wait_for_completion来等待剩余的数据发送完成。
NOTE:这里的completion是master驱动层的,spi设备驱动也有一个completion,用于IO同步,不要混淆。
当第一个数据发送完成以后,SPI中断产生,开始执行中断服务程序。在中断服务程序中,将判断是否需要读取数据,如果是则从寄存器中读取数据。
NOTE:如果是使用read系统调用,那么在此发送的数据将是0。
随后发送下一个数据,直到数据发送完成。发送完成后调用complete,使在s3c24xx_spi_txrx的wait_for_completion得以返回。接着,s3c24xx_spi_txrx就将返回已发送的字节数。
NOTE:其实该中断服务子程序实现了全双工数据的传输,只不过特定于具体的系统调用,从而分为了半双工读和写。
8.8 complete方法
在8.6节的bitbang_work中,当一个message的所有数据发送完成以后,将会调用complete函数。该函数如下:
/*
* We can't use the standard synchronous wrappers for file I/O; we
* need to protect against async removal of the underlying spi_device.
*/
static void spidev_complete(void *arg)
{
complete(arg);
}
该函数将使在spidev_sync函数中的wait_for_completion得以返回,从而完成了同步IO。
至此,整个write系统调用的流程均以讲解完毕,在这其中也对在master和protocol中未曾给出的函数做出了一一讲解,最后,对第8章进行小结。
8.9 小结

从示意图中,我们可以很清除看到函数的调用过程:先调用spi设备驱动层,随后调用bitbang中间层,最后调用了master驱动层来完成数据的传输。
9. read方法
read方法和write方法基本差不多,关键的区别在于其发送的数据为0,而在s3c24xx_spi_txrx中断服务程序中将读取数据寄存器。下面仅仅给出函数调用示意图。
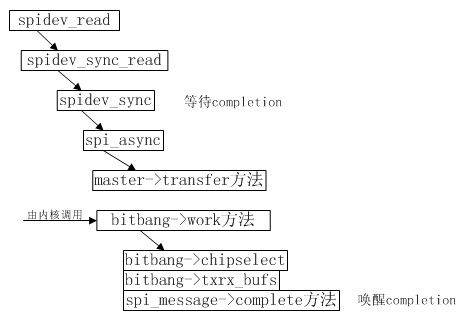
在这里给出spidev_read和spidev_sync_read,方便读者进行对比。
/* Read-only message with current device setup */
static ssize_t
spidev_read(struct file *filp, char __user *buf, size_t count, loff_t *f_pos)
{
struct spidev_data *spidev;
ssize_t status = 0;
/* chipselect only toggles at start or end of operation */
if (count > bufsiz) /*如果读取的字节数大于缓冲区的大小,则报错*/
return -EMSGSIZE;
spidev = filp->private_data; /*获取spidev*/
mutex_lock(&spidev->buf_lock); /*加锁,对buffer进行互斥房屋内*/
status = spidev_sync_read(spidev, count);
if (status > 0) {
unsigned long missing;
missing = copy_to_user(buf, spidev->buffer, status);
if (missing == status)
status = -EFAULT;
else
status = status - missing;
}
mutex_unlock(&spidev->buf_lock);
return status;
}
static inline ssize_t
spidev_sync_read(struct spidev_data *spidev, size_t len)
{
struct spi_transfer t = {
.rx_buf = spidev->buffer,
.len = len,
};
struct spi_message m;
spi_message_init(&m); /*初始化message*/
spi_message_add_tail(&t, &m); /*添加transfer*/
return spidev_sync(spidev, &m);
}
10. ioctl方法
这一章节中,我们将看一下SPI子系统是如何使用ioctl系统调用来实现全双工读写。
10.1 spi_ioc_transfer
在使用ioctl时,用户空间要使用一个数据结构来封装需要传输的数据,该结构为spi_ioc_transfe。而在write系统调用时,只是简单的从用户空间复制数据过来。该结构中的很多字段将被复制到spi_transfer结构中相应的字段。也就是说一个spi_ioc_transfer表示一个spi_transfer,用户空间可以定义多个spi_ioc_transfe,最后以数组形式传递给ioctl。
下面同时给出ioctl中cmd的值。其中SPI_IOC_MASSAGE用于实现全双工IO,而其他的用于设置或者读取某个特定值。
下列数据结构位于:include/linux/spi/spidev.h。
/**
* struct spi_ioc_transfer - describes a single SPI transfer
* @tx_buf: Holds pointer to userspace buffer with transmit data, or null.
* If no data is provided, zeroes are shifted out.
* @rx_buf: Holds pointer to userspace buffer for receive data, or null.
* @len: Length of tx and rx buffers, in bytes.
* @speed_hz: Temporary override of the device's bitrate.
* @bits_per_word: Temporary override of the device's wordsize.
* @delay_usecs: If nonzero, how long to delay after the last bit transfer
* before optionally deselecting the device before the next transfer.
* @cs_change: True to deselect device before starting the next transfer.
*
* This structure is mapped directly to the kernel spi_transfer structure;
* the fields have the same meanings, except of course that the pointers
* are in a different address space (and may be of different sizes in some
* cases, such as 32-bit i386 userspace over a 64-bit x86_64 kernel).
* Zero-initialize the structure, including currently unused fields, to
* accomodate potential future updates.
*
* SPI_IOC_MESSAGE gives userspace the equivalent of kernel spi_sync().
* Pass it an array of related transfers, they'll execute together.
* Each transfer may be half duplex (either direction) or full duplex.
*
* struct spi_ioc_transfer mesg[4];
* ...
* status = ioctl(fd, SPI_IOC_MESSAGE(4), mesg);
*
* So for example one transfer might send a nine bit command (right aligned
* in a 16-bit word), the next could read a block of 8-bit data before
* terminating that command by temporarily deselecting the chip; the next
* could send a different nine bit command (re-selecting the chip), and the
* last transfer might write some register values.
*/
struct spi_ioc_transfer {
__u64 tx_buf;
__u64 rx_buf;
__u32 len;
__u32 speed_hz;
__u16 delay_usecs;
__u8 bits_per_word;
__u8 cs_change;
__u32 pad;
/* If the contents of 'struct spi_ioc_transfer' ever change
* incompatibly, then the ioctl number (currently 0) must change;
* ioctls with constant size fields get a bit more in the way of
* error checking than ones (like this) where that field varies.
*
* NOTE: struct layout is the same in 64bit and 32bit userspace.
*/
};
/* not all platforms use <asm-generic/ioctl.h> or _IOC_TYPECHECK() ... */
#define SPI_MSGSIZE(N) \ /*SPI_MSGSIZE不能大于4KB*/
((((N)*(sizeof (struct spi_ioc_transfer))) < (1 << _IOC_SIZEBITS)) \
? ((N)*(sizeof (struct spi_ioc_transfer))) : 0)
#define SPI_IOC_MESSAGE(N) _IOW(SPI_IOC_MAGIC, 0, char[SPI_MSGSIZE(N)])
/* Read / Write of SPI mode (SPI_MODE_0..SPI_MODE_3) */
#define SPI_IOC_RD_MODE _IOR(SPI_IOC_MAGIC, 1, __u8)
#define SPI_IOC_WR_MODE _IOW(SPI_IOC_MAGIC, 1, __u8)
/* Read / Write SPI bit justification */
#define SPI_IOC_RD_LSB_FIRST _IOR(SPI_IOC_MAGIC, 2, __u8)
#define SPI_IOC_WR_LSB_FIRST _IOW(SPI_IOC_MAGIC, 2, __u8)
/* Read / Write SPI device word length (1..N) */
#define SPI_IOC_RD_BITS_PER_WORD _IOR(SPI_IOC_MAGIC, 3, __u8)
#define SPI_IOC_WR_BITS_PER_WORD _IOW(SPI_IOC_MAGIC, 3, __u8)
/* Read / Write SPI device default max speed hz */
#define SPI_IOC_RD_MAX_SPEED_HZ _IOR(SPI_IOC_MAGIC, 4, __u32)
#define SPI_IOC_WR_MAX_SPEED_HZ _IOW(SPI_IOC_MAGIC, 4, __u32)
10.2 spidev_ioctl
在用户空间执行ioctl系统调用时,将会执行spidev_ioctl方法,我们来看下。
下列代码位于drivers/spi/spidev.c
static long
spidev_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
int err = 0;
int retval = 0;
struct spidev_data *spidev;
struct spi_device *spi;
u32 tmp;
unsigned n_ioc;
struct spi_ioc_transfer *ioc;
/* Check type and command number */
if (_IOC_TYPE(cmd) != SPI_IOC_MAGIC) /*如果幻数不想等,则报错*/
return -ENOTTY;
/* Check access direction once here; don't repeat below.
* IOC_DIR is from the user perspective, while access_ok is
* from the kernel perspective; so they look reversed.
*/
/*对用户空间的指针进行检查,分成读写两部分检查*/
if (_IOC_DIR(cmd) & _IOC_READ、
err = !access_ok(VERIFY_WRITE, /*access_ok成功返回1*/
(void __user *)arg, _IOC_SIZE(cmd));
if (err == 0 && _IOC_DIR(cmd) & _IOC_WRITE)
err = !access_ok(VERIFY_READ,
(void __user *)arg, _IOC_SIZE(cmd));
if (err)
return -EFAULT;
/* guard against device removal before, or while,
* we issue this ioctl.
*/
spidev = filp->private_data; /*获取spidev*/
spin_lock_irq(&spidev->spi_lock);
spi = spi_dev_get(spidev->spi); /*增加引用技术,并获取spi_device*/
spin_unlock_irq(&spidev->spi_lock);
if (spi == NULL)
return -ESHUTDOWN;
/* use the buffer lock here for triple duty:
* - prevent I/O (from us) so calling spi_setup() is safe;
* - prevent concurrent SPI_IOC_WR_* from morphing
* data fields while SPI_IOC_RD_* reads them;
* - SPI_IOC_MESSAGE needs the buffer locked "normally".
*/
mutex_lock(&spidev->buf_lock); /*加锁互斥体*/
switch (cmd) {
/* read requests */ /*读取请求*/
case SPI_IOC_RD_MODE:
retval = __put_user(spi->mode & SPI_MODE_MASK,
(__u8 __user *)arg);
break;
case SPI_IOC_RD_LSB_FIRST:
retval = __put_user((spi->mode & SPI_LSB_FIRST) ? 1 : 0,
(__u8 __user *)arg);
break;
case SPI_IOC_RD_BITS_PER_WORD:
retval = __put_user(spi->bits_per_word, (__u8 __user *)arg);
break;
case SPI_IOC_RD_MAX_SPEED_HZ:
retval = __put_user(spi->max_speed_hz, (__u32 __user *)arg);
break;
/* write requests */ /*写请求*/
case SPI_IOC_WR_MODE:
retval = __get_user(tmp, (u8 __user *)arg);
if (retval == 0) { /*__get_user调用成功*/
u8 save = spi->mode; /*保存原先的值*/
if (tmp & ~SPI_MODE_MASK) {
retval = -EINVAL;
break; /*模式有错误,则跳出switch*/
}
tmp |= spi->mode & ~SPI_MODE_MASK;/*这步貌似多此一举????*/
spi->mode = (u8)tmp;
retval = spi_setup(spi);/*调用master->setup方法,即s3c24xx_spi_setup*/
if (retval < 0)
spi->mode = save; /*调用不成功,恢复参数*/
else
dev_dbg(&spi->dev, "spi mode %02x\n", tmp);
}
break;
case SPI_IOC_WR_LSB_FIRST:
retval = __get_user(tmp, (__u8 __user *)arg);
if (retval == 0) {
u8 save = spi->mode;
if (tmp) /*参数为正整数,设置为LSB*/
spi->mode |= SPI_LSB_FIRST;
else /*参数为0,设置为非LSB*/
spi->mode &= ~SPI_LSB_FIRST;
retval = spi_setup(spi);/*调用master->setup方法,即s3c24xx_spi_setup?/
if (retval < 0)
spi->mode = save; /*调用不成功,恢复参数*/
else
dev_dbg(&spi->dev, "%csb first\n",
tmp ? 'l' : 'm');
}
break;
case SPI_IOC_WR_BITS_PER_WORD:
retval = __get_user(tmp, (__u8 __user *)arg);
if (retval == 0) {
u8 save = spi->bits_per_word;
spi->bits_per_word = tmp;
retval = spi_setup(spi); /*调用master->setup方法,即s3c24xx_spi_setup*/
if (retval < 0)
spi->bits_per_word = save;
else
dev_dbg(&spi->dev, "%d bits per word\n", tmp);
}
break;
case SPI_IOC_WR_MAX_SPEED_HZ:
retval = __get_user(tmp, (__u32 __user *)arg);
if (retval == 0) {
u32 save = spi->max_speed_hz;
spi->max_speed_hz = tmp;
retval = spi_setup(spi); /*调用master->setup方法,即s3c24xx_spi_setup*/
if (retval < 0)
spi->max_speed_hz = save;
else
dev_dbg(&spi->dev, "%d Hz (max)\n", tmp);
}
break;
default:
/* segmented and/or full-duplex I/O request */ /*全双工,接受发送数据*/
if (_IOC_NR(cmd) != _IOC_NR(SPI_IOC_MESSAGE(0))
|| _IOC_DIR(cmd) != _IOC_WRITE) {
retval = -ENOTTY;
break;
}
tmp = _IOC_SIZE(cmd); /*获取参数的大小,参数为spi_ioc_transfer数组*/
if ((tmp % sizeof(struct spi_ioc_transfer)) != 0) {/*检查tmp是否为后者的整数倍*/
retval = -EINVAL;
break;
}
n_ioc = tmp / sizeof(struct spi_ioc_transfer); /*计算共有几个spi_ioc_transfer*/
if (n_ioc == 0)
break;
/* copy into scratch area */
ioc = kmalloc(tmp, GFP_KERNEL);
if (!ioc) {
retval = -ENOMEM;
break;
}
/*从用户空间拷贝spi_ioc_transfer数组,不对用户空间指针进行检查*/
if (__copy_from_user(ioc, (void __user *)arg, tmp)) {
kfree(ioc);
retval = -EFAULT;
break;
}
/* translate to spi_message, execute */
retval = spidev_message(spidev, ioc, n_ioc);
kfree(ioc);
break;
}
mutex_unlock(&spidev->buf_lock);
spi_dev_put(spi); /*减少引用计数*/
return retval;
}
在函数中,首先对cmd进行了一些列的检查。随后使用switch语句来判读cmd,并执行相应的功能。cmd的第一部分为读请求,分别从寄存器读取4个参数。第二部分为写请求,分别用于修改4个参数并写入寄存器。剩余的第三部分就
是全双工读写请求,这是会先计算共有多少个spi_ioc_transfer,然后分配空间,从用户空间将spi_ioc_transfer数组拷贝过来,然后将该数组和数组个数作为参数调用spidev_message。
10.3 spidev_message
static int spidev_message(struct spidev_data *spidev,
struct spi_ioc_transfer *u_xfers, unsigned n_xfers)
{
struct spi_message msg;
struct spi_transfer *k_xfers;
struct spi_transfer *k_tmp;
struct spi_ioc_transfer *u_tmp;
unsigned n, total;
u8 *buf;
int status = -EFAULT;
spi_message_init(&msg); /*初始化message*/
k_xfers = kcalloc(n_xfers, sizeof(*k_tmp), GFP_KERNEL); /*分配内存,并清0*/
if (k_xfers == NULL)
return -ENOMEM;
/* Construct spi_message, copying any tx data to bounce buffer.
* We walk the array of user-provided transfers, using each one
* to initialize a kernel version of the same transfer.
*/
buf = spidev->buffer; /*所有的spi_transfer共享该buffer*/
total = 0;
/*遍历spi_ioc_transfer数组,拷贝相应的参数至spi_transfer数组*/
for (n = n_xfers, k_tmp = k_xfers, u_tmp = u_xfers;
n;
n--, k_tmp++, u_tmp++) {
k_tmp->len = u_tmp->len;
total += k_tmp->len;
if (total > bufsiz) { /*缓冲区长度为4096字节*/
status = -EMSGSIZE;
goto done;
}
if (u_tmp->rx_buf) { /*需要接受收据*/
k_tmp->rx_buf = buf;
if (!access_ok(VERIFY_WRITE, (u8 __user *) /*检查指针*/
(uintptr_t) u_tmp->rx_buf,
u_tmp->len))
goto done;
}
if (u_tmp->tx_buf) { /*需要发送数据*/
k_tmp->tx_buf = buf;
if (copy_from_user(buf, (const u8 __user *) /*将用户空间待发送的数据拷贝至buf中*/
(uintptr_t) u_tmp->tx_buf,
u_tmp->len))
goto done;
}
buf += k_tmp->len; /*修改buf指针,指向下一个transfer的缓冲区首地址*/
/*复制四个参数*/
k_tmp->cs_change = !!u_tmp->cs_change;
k_tmp->bits_per_word = u_tmp->bits_per_word;
k_tmp->delay_usecs = u_tmp->delay_usecs;
k_tmp->speed_hz = u_tmp->speed_hz;
#ifdef VERBOSE
dev_dbg(&spi->dev,
" xfer len %zd %s%s%s%dbits %u usec %uHz\n",
u_tmp->len,
u_tmp->rx_buf ? "rx " : "",
u_tmp->tx_buf ? "tx " : "",
u_tmp->cs_change ? "cs " : "",
u_tmp->bits_per_word ? : spi->bits_per_word,
u_tmp->delay_usecs,
u_tmp->speed_hz ? : spi->max_speed_hz);
#endif
spi_message_add_tail(k_tmp, &msg); /*添加spi_transfer到message的链表中*/
}
/*spidev_sync->spi_async->spi_bitbang_transfer->bitbang_work->s3c24xx_spi_txrx*/
status = spidev_sync(spidev, &msg);
if (status < 0)
goto done;
/* copy any rx data out of bounce buffer */
buf = spidev->buffer;
for (n = n_xfers, u_tmp = u_xfers; n; n--, u_tmp++) {
if (u_tmp->rx_buf) {
if (__copy_to_user((u8 __user *)
(uintptr_t) u_tmp->rx_buf, buf, /*从buf缓冲区复制数据到用户空间*/
u_tmp->len)) {
status = -EFAULT;
goto done;
}
}
buf += u_tmp->len;
}
status = total;
done:
kfree(k_xfers);
return status;
}
首先,根据
spi_ioc_transfe
r的个数,分配了同样个数的spi_transfer,把spi_ioc_transfer中的信息复制给spi_transfer,然后将spi_transfer添加到spi_message的链
表中。接着。执行了spidev_sync,这个东西似乎似曾相识,这个函数就是 8.3 小结的函数。之后的过程就和前面的write、read一样了。
其实,这个函数的作用就是把所需要完成的数据传输任务转换成spi_transfer,然后添加到message的连表中。
从spidev_sync返回以后,数据传输完毕,将读取到的数据,复制到用户空间。至此,整个ioctl系统调用的过程就结束了。
10.4 小结

事实上,全速工io和半双工io的执行过程基本一样,只不过ioctl需要一个专用的结构体来封装传输的任务,接着将该任务转换成对应的spi_transfer,最后交给spidev_sync。
11. 结束语
本系列文章先从最底层的master驱动开始讲解,接着描述了高层的spi设备驱动,然后,通过系统调用接口,从上至下的讲解了整个函数的调用过程。最终,
我们可以很清除看到半双工读和半双写的区别和相似之处,以及半双工IO和全双工IO的区别和相似之处。
最后,希望该系列文章能帮助你了解Linux的SPI子系统。
谢谢!