1、简介
机器学习的目的就是根据一些训练样本,寻找一个最优的函数,使得函数对输入X的估计Y'与实际输出Y之间的期望风险(可以暂时理解为误差)最小化。期望风险最小化依赖于样本的输入X与其输出Y之间的函数映射关系,而这个映射关系,在机器学习系统中,一般指代先验概率和类条件概率。然而,这两者在实际的应用中,都是无法准确获取的,唯一能够利用的就只有训练样本的输入X及其对应的观测输出Y。而机器学习的目的又必须要求使得期望风险最小化,从而得到需要的目标函数。不难想象,可以利用样本的算术平均值来代替式理想的期望。利用已知的经验数据(训练样本)来计算得到的误差,被称之为经验风险。用对参数求经验风险来逐渐逼近理想的期望风险的最小值,就是我们常说的经验风险最小化(Empirical risk minimization,ERM)原则。
其可以概括为经验风险最小化是统计学习理论的一个原则,它可以用来给出学习算法的性能边界。
2、背景
考虑下面的情形,我们有两个空间对象X和Y,我们欲学习得到一个函数:h:X->Y(这个通常被叫作假设),即对于指定的![]() ,都能得到相应的输出
,都能得到相应的输出![]() 。
。
为了更好的理解它,我们假设在X和Y间有一个联合概率分布P(x,y),而训练集包含m个实例(x1, y1),......,(xm, ym)。请注意,联合概率分布的假设可以让我们模拟预测的不确定性,这是因为y不是x的确定性函数,而是一个符合条件分布P(y|x)的的随机变量。
我们还要假设我们拥有一个非负实值的损失函数![]() ,它可以衡量假设值
,它可以衡量假设值![]() 和真实值y之间的差异。与假设h(x)相关的风险被定义为损失函数的期望:
和真实值y之间的差异。与假设h(x)相关的风险被定义为损失函数的期望:
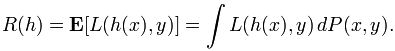
损失函数在理论上常用的是0-1损失函数,![]() ,在这里I(...)是指标符号,也可以表述为
,在这里I(...)是指标符号,也可以表述为 。
。
而我们的最终目的就是在一系列固定的函数H中发现一个假设h*,使其风险R(h)最小:
3、定义
在一般情况下,无法计算风险R(h)因为P(x, y)的分布是未知的学习算法(这种情况被称为不可知的学习)。不过,我们可以通过训练集的平均损失函数计算出一个近似值,并称其为经验风险,

经验风险最小化的原则,即是学习算法应该选择一个具有最小化经验风险的函数/假设:
![]()