杨建:网站加速--动态应用篇 (上)
转自 http://blog.sina.com.cn/s/blog_466c66400100hw0i.html
--提升性能的同时为你节约10倍以上成本
From: http://blog.sina.com.cn/iyangjian
一, 引子
二,总体结构图
三,系统结构综述
四,环境配置以及底层基础类库
五, Memcache & Mysql 常用场景案例
六,更多待续 ......
-----------------------------------------------------------------------------------------
一, 引子
张三丰当初传授传授张无忌太极剑法的时候,刚传授完,就问是否已经忘记。直到张无忌说招式已经忘光了,才算学会。当时很不理解,现在终于明白了,招随心出,不应受到固定招式的限制。总有人问我什么样的架构是不是就好,或者某个很有名的网站用什么架构,我们就要用吗?甚至觉得直接拿个别人的配置文件或参数,性能就会突飞猛进。那么请问你知道别人当时为什么那么做吗?做架构亦如学太极剑法,也请你学习别人的架构的时候,理解了就忘记掉,因为任何架构本身都有环境局限性,然后用心思考,分析,真正理解你所处的环境,从实际需求出发,你才能做出最适合你应用的架构。
很多人对写server很感兴趣,甚至一开始就直接考虑从底层协议进行优化,我说远还没到那个程度,请找出你真正的瓶颈。优化一定是从宏观到微观的,有时候一个系统结构,业务逻辑,或策略的优化,带来的效果甚至更为可观。对于每天请求处理量小于100亿的系统,我都不建议自己去写server。如果说写高性能server的技能是我手中的那把太极剑的话,那么发挥出太极剑法的威力并不依赖于那把剑,而是取决于对心法的理解。那把剑既然可以是专用server,当然也可以是开源的那几款经典server,取决于你对设计容量,以及硬件成本,维护成本,时间等多方面的预期。架构本身就是一个取舍的过程。
现在有这样的一个项目,就拿我上一篇文章里提到的自选股来举例吧,用户可以在各个市场里创建自己的多个投资组合,然后在组合里定制自己关注的股票。描述一下环境以及需求。
环境:注册用户小几千万,同时在线预计峰值不到10万。
需求:
1,3G,IM,Mail,Web 任何一个地方以及不同的主流浏览器更新数据,其他地方立即可见。
2,北京,天津,上海,深圳,任何一个IDC数据更新,其他三个IDC立即可见。
3,各IDC附近用户,获取股票列表的平均响应速度要控制在20ms以内。
4,IDC间专线中断服务不能受影响。
5,IDC内部的相同功能的服务器,允许宕掉一半,服务完全不受影响。
6,IDC允许宕掉一到两个,受灾IDC 95%的用户服务影响不超过5分钟。
7,另外,需要开发人员能够在这个系统上快速开发,要具备易用性,良好扩展性以及移植性。
基于以上的需求构建的实现,动态应用篇侧重点主要是如何快速响应,同步更新,如何容灾,消除安全隐患,让系统更稳定,如何容易迁移和扩展应用,如何让程序员容易使用这个平台。这个系统性能不是主要关注的问题(10万同时在线,确实比较微量,何况仅有的不多的压力,也通过后面介绍的各种缓存机制转移的差不多了),架构上采用当前主流经典架构(Nginx+PHP Fast-CGI+APC+Mysql+Memcache+LVS+Linux),各层次之间低偶合,每一层都具备单独优化的空间, 随着用户量的增加,我再逐步推出动态应用处理并发和压力方面的文章。
二,总体结构图
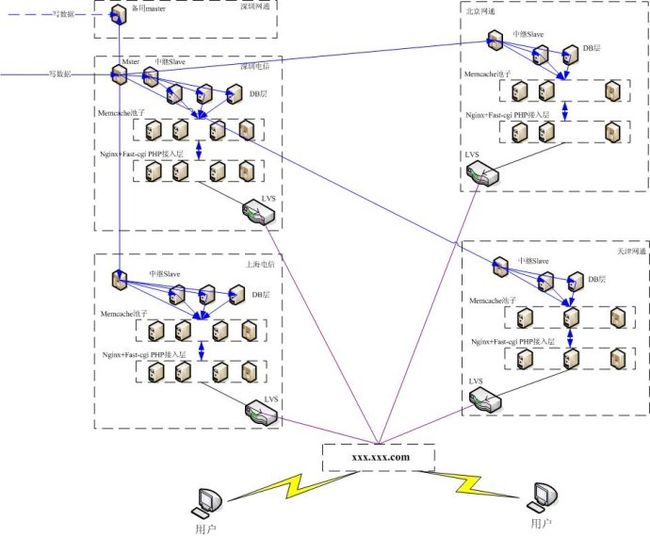
(实际结构中去掉了中继slave,改成所有slave直连master,这样结构更简单,易于管理和故障恢复。)
三,系统结构综述
此系统主要分为几个低偶合的层次组装而成,具备多IDC分布的特性。从底往上依次为DB层,MC池子层,Nginx+PHP Fast-CGI层,LVS层,然后通过DNS接入用户。每一层都具备良好的扩展性以及灾备能力。
DNS:
从大的结构上来说,此系统分布在4个主要IDC,网通电信各2。 机器数量按照网通:电信 1:2的比例配置,同一运营商下的两IDC机器数量等同。这样在宕掉一个IDC的情况下,可以通过切换DNS,临时访问相近的IDC,达到IDC间灾备。
LVS层:
每个IDC的接入层通过LVS作四层负载均衡。IDC内部任何接入机器宕掉,可以通过failover机制在一分钟内自动摘除。
Nginx+PHP Fast-CGI层:
通过fpm管理PHP Fast-CGI进程,Nginx通unix域协议与fpm通信。转发 *.php的请求以及响应。使用APC作为OP代码加速器,加速php响应。PHP直接与MC池子或Mysql层进行交互。
MC池子层:
每个IDC内部的多个MC机是作为一个整体来管理的,也就是说,假如你有100个数据,4个MC机,那么每个MC上只会存25个数据,而不会每个都存100个。好处是,获得了相当于以前4倍的内存池, 增大了缓存命中率。更额外的好处是,减少了,本IDC内部各MC间数据同步的时间开销,使得本IDC任何一服务器更新的数据,同IDC内其他服务器立即可见。也使得IDC之间MC的同步更为节约,每个IDC一个池子,每个池子只需要写一份数据。
MC池子增减机器的问题:如果是传统的hash算法根据key值,将数据平均的hash到4台机器上,那么按照新的hash规则,增加一台机器后,将会有近80%的缓存失效,造成大量数据迁移。所以我们改用Consistent Hashing,首先求出memcached服务器(节点)的哈希值,并将其配置到0~2的32次方的圆上。然后用同样的方法求出存储数据的键的哈希值,并映射到圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过2的32次方仍然找不到服务器,就会保存到第一台memcached服务器上。它能最大限度地抑制键的重新分布。而且,有的实现还采用了虚拟节点的思想,使得分布更加均匀。由服务器台数(m)和增加的服务器台数(n)计算增加服务器后的命中率计算公式如下:(1 - n/(n+m) ) * 100 ,按这个计算,增加一台机器后还将得到80%的命中率。更较幸运的是这个算法已经被php所支持,可以通过php.ini设置。
宕机重启后初始化的问题:如果初始化的数据只从一台DB上获得,那么在高峰期间必将压垮DB,所以,我们需要将这个压力,分散到本IDC的多台DB上。细节会在基础类库中进行讲述。
异地MC池子的数据同步:已经封装在基础类库中,更新MC时指定特定的参数,就会在其他异地MC池子上也进行更新。所以我们如果在北京添了一个数据,那么在深圳也会立刻看到。
DB层:
主从结构集群,主库可切换,从库互为备份。从DB宕掉一台,可以自动跳过,不影响服务,目前通过基础类库实现,以后会采用内部DNS。所有从库直接和主库相连,结构简单,方便管理。不过写的数据量相对比较小的,而且我们允许DB延迟(由MC来保证实时性,或者异地本来就可以接受短暂的延迟),这里将不是问题。
MC和DB写队列:
在专线中断时不影响写操作(读都是本地的,当然也不受影响),而且在更新数据时能够快速返回(因为不需要远程通信)。
具体来说就是将MC的异地写,以及DB的写操作封装成直接追加写本地队列文件。每个机器上有个守护进程,每0.1秒检查一次,有则rename,然后开始将队列数据逐条往深圳数据中心post,同时每成功一条记录当前offset,以便意外宕掉后接着上次的后面处理。(优化点的可以改为批量确认,冒进点的,可以使用内存盘优化写速度)。如果线路不通,或者数据中心写失败,post程序将sleep and retry,线路恢复则继续,不会丢数据。这里有个细节需要注意,就是往数据中心同步的时候,尽量发往同一台机器,也即绑定,以保证序列的顺序,这个保证可以通过对post守护进程的pid取mod来实现,如果绑定的机器出了故障,则应该选定另外一台机器绑定,一旦检测到以前的机器好了,则应该切回来,以保证应有的负载均衡。另外,最外层的接入端也同样需要注意这个问题,我们对lvs做了会话保持,以确保同一用户在相当长的一段时间内,会访问到同一台机器。对于仅仅使用DNS轮询,又没有使用长连接的服务,如果在短时间内做数据更新,肯定会出现乱序的问题。除非你各服务器时间都很精准,而且,每个记录写的时候打上精确到ms的时间戳。
然后,深圳数据中心接收到post的数据后,根据消息类型按一定规则的命名分别存放,这样即使增加一种新的消息,也可以方便的使用队列。比如收到MC的消息后,要写三份,分别发往三个IDC,各自不受影响。DB,可以根据不同的port实例子来创建队列,免得有一个port宕了,影响其他。具体实现细节可以自己调整,同样得有个程序定期(比如每0.1秒,0.01秒也无所谓,对cpu的消耗非常小)检查队列文件存在就rename,然后往master里写。
以上则能保证,DB的master宕掉,或者专线的中断情况下,用户服务基本不受影响,只是异地的同步会延迟一些。额外收获是将来做DB升级调整的时候,可以用队列分流,分别做不同的处理。
祛除安全隐患:
不管你的系统设计的多么完美,疏忽这一条足以致命。
以上设计看起来似乎已经没什么问题了,各种容灾,异常也基本考虑到了,不幸的是,这个平台并不是仅仅给设计者自己使用,如果有个新手使用了 file_get_contents($url); 如果url所依赖的服务器负载过重,那么整个系统都有被拖垮的危险。动态应用的一个铁律就是,凡是依赖本系统外部资源的地方必须加超时限制,尽可能的减少依赖。file_get_contents的超时不是很精确,推荐使用curl的库进行封装,可以设置connect超时,也可以设置整个函数的执行时间超时。我一般会设置my_curl();函数的最大默认执行时间为一秒,因为是从内网拉取数据,一秒还拉不到,肯定有问题。另外,别忘记了mysql读服务,当某一idc的一台slave连接数满了以后,如果没设置过mysql.connect_timeout=1;那这个IDC的服务会整个被拖垮,因为默认的是60秒。(mysql的写由队列保证,不存在此问题)。
另外,我们项目还有个特殊性,即,每次拉取用户股票信息时,需要从后台专线到深圳进行身份合法性验证,由于历史的原因,这个验证系统暂不具备多IDC分别的能力。假设北京的专线断了,虽然用户的数据是没问题,但是验证却通不过,会导致获取数据失败。同样这个验证是要加超时的,另外为了在专线断掉的情况下依然正常提供服务,就需要在得不到验证的情况下,要通过代理的手段到邻近的IDC去验证。同时,我们也支持另外一种验证方式,对于已经通过验证的用户,专线中断一小段时间,比如一小时,服务是可以不受影响。
总之就是尽量低偶合,少依赖,加超时。另外一个维护的安全,则由安全中心把关,我就不多说了。
四,环境配置以及底层基础类库
PHP网络版环境:每IDC之间差异化的Nginx环境变量配置,使得相同的应用程序在不同的IDC运行时,使用各自IDC内部的MC以及DB等资源。
PHP Shell版环境:
PHP Shell是指通过命令行方式执行的php脚本程序。
比如/path/php/bin/php test.php
或在php程序第一行加上
#!/path/php/bin/php
然后赋予php脚本可执行权限,使作为shell程序运行。
由于php作为shell运行时,无法继承nginx配置的环境变量。所以它必须依赖一个独立的配置文件。
由于图片里含有帐户等敏感信息,就不在此贴了。
底层基础类库:
底层基础类库,起到粘合剂的作用,将环境配置,服务器资源等全部结合起来,使得这些资源以及配置信息对上层开发人员透明,无须考虑。总的来说有以下一些功能。
1, 两环境融合,天衣无缝。 php 网络环境和shell使用同一基础类库,代码无任何一行差异。使得平时编写的php网络程序,以及类库积累,可以方便的直接用来做shell编程,进行复用。具体原理是,类库需要用到配置信息时,先通过if( isset ($_ENV["SERVER_SOFTWARE"]) )变量判断自己是否网络环境,如果是就直接使用配置项比如:_SERVER["DB_stock_host"] ,若不是,则先将配置文件数据项,section名和下面的字段相加转化成 _SERVER["DB_stock_host"] = “m3306_sz_gtimg_cn” ; 跟网络环境一致后,再继续后面操作。
[DB_stock]
host = m3306_sz_gtimg_cn
类库目前除支持模拟DNS外,还直接兼容真实域名以及IP地址,方便将来进行数据迁移。之所以没有直接使用 DNS是也有历史原因的。
2, 对DB资源的封装。
在没有内部DNS的情况下,将DB读写分离,帐户选择,连接的建立(包括 何时候真正建立连接,建立长连接,还是短连接,连接的绑定,以及生命周期),负载均衡以及failvoer等封装成对用户透明的如下简单用法:
//指定以读(r) 或 写(w) 的方式打开一个库。不指定的情况下,默认是”r”方式打开。
$db_r =new MYSQL(“testdb”,“r”);
<?
require_once (dirname(__FILE__).'/../mysql.php');
$db_w =new MYSQL("test","w");
$arr = array(
"id" => "8",
"name" => "yangjian8"
);
if( $db_w->insert("test",$arr) )
{
echo "query ok ...<br>";
}
else
{
echo "query failed ...<br>";
echo "errno=$db_w->errno<br> errmsg=$db_w->errmsg<br>";
}
echo "read ............<br>";
$db_r =new MYSQL("test","r");
$sql = "select * from test";
if( $result = $db_r->query($sql))
{
while ($row = mysql_fetch_array($result, MYSQL_BOTH))
{
printf ("id: %s name: %s<br>", $row[id], $row[name]);
}
$db_r->free(); //free result. if you not free it,it will auto free at the end of the php script.
}
else //if not success,you can print the error info.
{
echo "errno=$db_r->errno<br> errmsg=$db_r->errmsg<br>";
}
3, 对MC池子资源的封装。
简化MC池子使用方法,支持异地MC数据同步。
//if rset=1,the mc data will sync to other idcs, default 0.
function set($key, $value, $flag, $expire, $r_set=0)
<?php
require_once (dirname(__FILE__).'/../memcache.php');
$mc = new MC("test");
for($i=0;$i<2;$i++)
{
$mc->set("key".$i,"value".$i,0,100);
}
for($i=0;$i<2;$i++)
{
echo $mc->get("key".$i);
echo "<br>";
}
DB以及MC的异地写已经封装进去,对上层开发人员来说都是透明的。
注意:我在引用头文件时候,都会使用类似require_once (dirname(__FILE__).'/../mysql.php'); 的方法。我暂且管它叫动态绝对路径。它的好处是,
跟相对路径比:当一个头文件被多层引用时,目录结构又不一致,不会找不到。
也不会去搜索所有可能的目录,执行多余的fstat以及open操作。
跟绝对路径相比:如果我将整个项目,包括头文件全部平移到别的目录,不需要挨个修改文件。
当然,你也可以采用另外一个方法,将本项目相关的配置信息绝对路径放在一个统一的文件里,然后通过任何一种方法引用那个文件。