高精度24bit 模数转化 AD7767芯片 使用总结
转载请标明是引用于 http://blog.csdn.net/chenyujing1234
欢迎大家提出意见,一起讨论!
PDF资料请大家网上搜索。
环境:
上位机 MIPS+WCE6.0
=========================================
1、芯片功能介绍
它是一个高精度的24bit采样SAR模数转换芯片 。
它有一个大的输入动态范围。能检测到小的电压变化
它的输出数据可以通过PCI或USB系统获得,读取数据的协议类似于SPI。
(1)引脚
通过示波器观看,可以知道当MSCK为30KHz时,SYNC/PD为高时,就能进行AD转化,有数据时DRDY为低,此时在SCLK的时序下把数据
移位到SDO中。当采用模拟的SPI(即不采用硬件的SPI模块时,请参考: )读取SDO时,SDO的频率为40KHz。而SCLK才900Hz.
从代码上讲SCLK拉高拉低的次数比SDO来得多,应该SCLK比SDO才对。会不会示波器有问题?

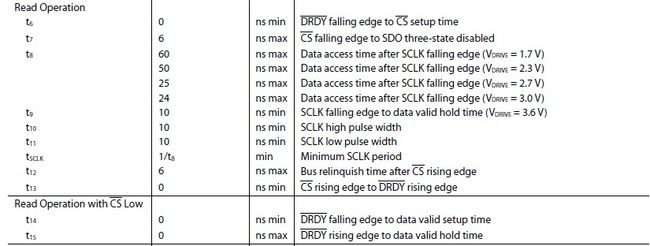
(2)读取时序图
上面讲到读取它的是SPI协议,只是类似,大家看它的时序就知道它不是真正的SPI,因为有DRDY脚.
读取方式有两种:CS为常低和读时CS才为低.

从上图可以看到,24bit数据是高位在前,注意的部分用红色圈起来了.
在编程中关键的是t6、t7、t8、t10、t11及最高位得做异或。
2、读数据程序实现
我采用的是读时再让CS下降.
由于是用GPIO口模拟SPI协议,下面的宏先定义各IO口,及读取它们的接口。
#define CLK_BANK 2 // SCLK脚
#define CLK_BIT 9
#define DAT_BANK 1 // SDO脚
#define DAT_BIT 25
#define CS_BANK 1 // CS脚
#define CS_BIT 23
#define RDY_BANK 0 // DRDY脚
#define RDY_BIT 12
#define SDA_GPIO (DAT_BANK * 32) + DAT_BIT
#define SET_CLK_HIGH() \
{ \
pin_val[CLK_BANK] = (1<<CLK_BIT); \
}
//if(TRUE == g_bAddDelay) \
//OALStallExecution(g_delayUS); \
//}
#define SET_CLK_LOW() \
{ \
pin_valclr[CLK_BANK] = (1<<CLK_BIT); \
}
//if(TRUE == g_bAddDelay) \
// OALStallExecution(g_delayClkLowUs); \
//}
#define SET_CS_HIGH() \
{ \
pin_val[CS_BANK] = (1<<CS_BIT); \
}
//if(TRUE == g_bAddDelay) \
//OALStallExecution(g_delayUS); \
//}
#define SET_CS_LOW() \
{ \
pin_valclr[CS_BANK] = (1<<CS_BIT); \
}
//if(TRUE == g_bAddDelay) \
//OALStallExecution(g_delayUS); \
//}
#define GET_SDA_DATA ((pin_val[DAT_BANK] & (1<<DAT_BIT)) ? 1 : 0)
#define GET_RDY_DATA ((pin_val[RDY_BANK] & (1<<RDY_BIT)) ? 1 : 0)
把CS拉低后有一个t6才能CLK下降,t6是0ns.(其实可以把for(i = 0; i < g_delayCSLow; i++)去掉的
static BOOL PCIPortRead(DEVICE_HANDLE *devHandlePtr, PULONG outBuffPtr)
{
int i = 0;
BOOL retval = TRUE;
// 当RDY为低时才去读数据
if(0 == GET_RDY_DATA)
{
// 0ns
SET_CS_LOW(); // 把CS拉低
for (i = 0; i < g_delayCSLow; i++); // 6ns
*outBuffPtr = PCIGet24Bit();
SET_CS_HIGH(); // 把CS拉高
}
return retval;
}
下面是读24bit数据:
CLK拉低后,有一个60-24ns的时间,大家一看是ns怎么办叱?
按道理说时序图上的时间只要你大于它都是没问题的,但是为了AD转化取样平滑,我们想让读取的点多,
那么就得在读取时间上做最优化,这里我用for循环来控制ns。因为一个for大约是两个机器周期,
我的机器是800M,那么一个周期就是1/800M = 0.8ns.那么就可以换算出要执行几条指令了。
static ULONG PCIGet24Bit(void)
{
BYTE status = 0;
ULONG ulData = 0;
int i = 0, j = 0;
// 接收24个bit
for(i=0; i < 24; i++)
{
ulData <<= 1;
SET_CLK_LOW(); // 时间下降沿有效
for (j = 0; j < g_delayClkLowUs; j++); // 60-24 ns
status = GET_SDA_DATA;
ulData |= status;
SET_CLK_HIGH();
for (j = 0; j < g_delayClkHighUs; j++); // 10ns
}
// 24位补码还原
return ulData^0x800000;
}
大家看PCIGet24Bit函数,最后返回时是
// 24位补码还原
return ulData^0x800000;
为什么要这样呢?
请看: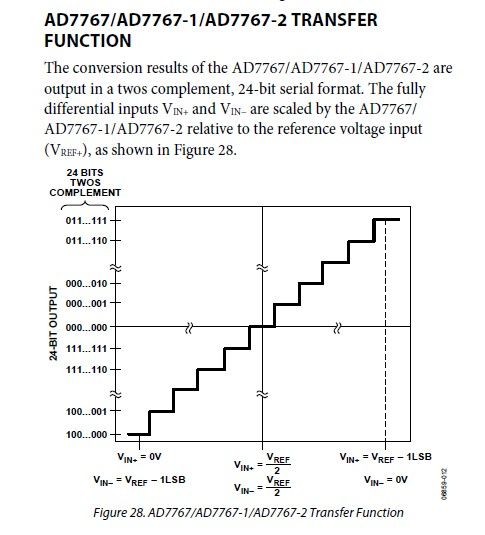
用一个24位AD转换芯片 输出为二进制补码 最小值和最大值分别为:800000 7FFFFF(HEX)
异或0x800000就是把最高位翻转。翻转的结果看成数学二进制的话就是把原先的数加了0x800000,但是最高位的进位被丢掉,
这样原先最小的数,就是0x800000,加完变成0x1000000,最高位爆出去了,又变成0x000000了;原先最大的数,7FFFFF,变成了FFFFFF。
综上,采用补码是为了能扩大表达的数的范围.(一开始我没有把补码还原,这样造成的后果是波峰变成了波谷)
===========================================================================================
3、结果.
把AD结果画出图形。^-^

==============================================================================================
总结:
做AD开发,别一开始就用实际输入源,先用自己的信号发生器出来对于AD芯片来说最大的电压与最小的电压、参考的电压。看是不是能得到正确值。