实例恢复的原理+PGA +
原文整理自网络:
5.4.2.5 实例恢复的原理
前面我们讲到过,当数据库突然崩溃,而还没有来得及将buffer cache里的脏数据块刷新到数据文件里,同时在实例崩溃时正在运行着的事务被突然中断,则事务为中间状态,也就是既没有提交也没有回滚。这时数据文件里的内容不能体现实例崩溃时的状态。这样关闭的数据库是不一致的。
下次启动实例时,Oracle会由SMON进程自动进行实例恢复。实例启动时,SMON进程会去检查控制文件中所记录的、每个在线的、可读写的数据文件的END SCN号。数据库正常运行过程中,该END SCN号始终为空,而当数据库正常关闭时,会进行完全检查点,并将检查点SCN号更新该字段。而崩溃时,Oracle还来不及更新该字段,则该字段仍然为空。当SMON进程发现该字段为空时,就知道实例在上次没有正常关闭,于是由SMON进程就开始进行实例恢复了。
SMON进程进行实例恢复时,会从控制文件中获得检查点位置。于是,SMON进程到联机日志文件中,找到该检查点位置,然后从该检查点位置开始往下,应用所有的重做条目,从而在buffer cache里又恢复了实例崩溃那个时间点的状态。这个过程叫做前滚,前滚完毕以后,buffer cache里既有崩溃时已经提交还没有写入数据文件的脏数据块,也还有事务被突然终止,而导致的既没有提交又没有回滚的事务所弄脏的数据块。
前滚一旦完毕,SMON进程立即打开数据库。但是,这时的数据库中还含有那些中间状态的、既没有提交又没有回滚的脏块,这种脏块是不能存在于数据库中的,因为它们并没有被提交,必须被回滚。打开数据库以后,SMON进程会在后台进行回滚。
有时,数据库打开以后,SMON进程还没来得及回滚这些中间状态的数据块时,就有用户进程发出读取这些数据块的请求。这时,服务器进程在将这些块返回给用户之前,由服务器进程负责进行回滚,回滚完毕后,将数据块的内容返回给用户。
Oracle提供了初始化参数fast_start_mttr_target让我们指定完成实例恢复所花费的时间(该时间只包括前滚并打开数据库的时间,不包括回滚的时间),该参数以秒为单位。比如我们设置该参数为30,表示如果发生实例崩溃,那么下次重新启动时,数据库最多用30秒的时间完成前滚,并打开数据库。在数据库运行过程中,就会根据该时间,来估算30秒大致对应多少量的重做记录,这实际上就决定了检查点位置,如图5-8所示。
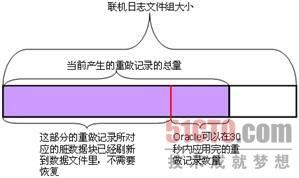 |
| 图5-8 检查点队列3 |
图5-8中的红色竖线就是检查点位置。Oracle应用完检查点位置以后所有的重做记录所花费的时间就是fast_start_mttr_target所指定的时间。也就是说,检查点位置以后的重做记录所对应的脏块会被留在检查点队列上,而不被DBWn写入数据文件。因此,该参数越大,说明要应用的重做记录就越多,那么留在检查点队列上的脏块就越多,也就说明DBWn写脏块越不频繁,占用I/O越少,那么前台用户查询语句的I/O就能够越快地被响应。但是实例恢复的时间也会越长。反之,该参数越小,说明要应用的重做记录就越少,那么留在检查点队列上的脏块就越少,也就说明DBWn写脏块越频繁,因而占用I/O越多,那么前台用户查询语句的I/O就不能较快地被响应。但是实例恢复的时间会更短。
5.6 自动共享内存管理
从Oracle 10g开始,Oracle提供了自动SGA的管理(简称ASMM,即Automatic Shared Memory Management)新特性。所谓ASMM,就是指我们不再需要手工设置shared pool、buffer pool等若干内存池的大小,而是为SGA设置一个总的大小尺寸即可。Oracle 10g数据库会根据系统负载的变化,自动调整各个组件的大小,从而使得内存始终能够流向最需要它的地方。
比如,假设某个系统,白天属于OLTP应用,因此会需要较多的buffer cache。而该系统在晚上属于DSS(OLAP)应用。对于DSS应用,很多的SQL语句由于都是进行全表扫描,因此都会采取并行方式完成。我们知道,并行时需要靠若干的从属进程完成工作,而从属进程会从large pool中进行分配。于是,晚上会需要较多的large pool。如果我们启用了ASMM,则数据库会根据负载的变化而自动的对内存大小进行调整,就不需要DBA进行手工调整了。
Oracle 10g提供了一个新的初始化参数:sga_target来启动ASMM,该参数定义了整个SGA的总容量。同时,初始化参数statistics_level必须设置为typical或all才能启动ASMM,否则如果设置为basic,则关闭ASMM。
ASMM只能自动调整5个内存池的大小,它们是:
shared pool、buffer cache、large pool、java pool和stream pool。
我们不再需要设置shared_pool_size、db_cache_size、large_pool_size、java_pool_size、streams_pool_size这五个初始化参数。而其他的内存池,比如 log buffer、keep buffer cache 等仍然需要DBA手工进行调整。
举例来说,假设我们将sga_target设置为500MB,表示SGA总容量为500MB。但是如果我们需要配置100MB的keep buffer cache,则必须手工设置参数db_keep_cache_size为100MB。同时如果设置参数log_buffer为3MB,那么shared pool、buffer cache等可以调整的5个部分的总容量就是397MB(500-100-3=397)。
Oracle 10g还提供了另一个初始化参数sga_max_size。sga_target的值不能超过sga_max_size的值,修改sga_max_size时,必须重启实例才能生效,而sga_target则可以在线修改,立即生效,无须重启实例。
为了实现ASMM,Oracle新引入了一个名为MMAN(Memory Manager)的后台进程。每隔很短的一段时间,MMAN进程就会启动,然后去询问一下Oracle提供的各个内存组件顾问,比如有buffer cache顾问,也有shared pool顾问,由这些顾问根据当前的负载情况,将这5个可以自动调整的内存池的、建议的大小尺寸,返回给MMAN。于是,MMAN进程就会根据该返回的值,来设置各个内存池。同时,如果我们使用了spfile,还会将这些顾问得出的建议值写入spfile里。这样,下次启动实例时,就可以直接把顾问得出的建议值拿来作为启动内存池的依据了。
如果我们启用了ASMM,同时又手工设置了可以自动调整大小的内存池的尺寸,比如设置了参数shared_pool_size为一个非0值的时候,会怎么样?对于Oracle 10g来说,我们为自动调整大小的内存组件设置了值,则会以我们设置的值作为自动调整的最小值。也就是说,假设sga_target为4GB,而我们将shared_pool_size设置为600MB,则MMAN在进行自动调整时,永远不会将shared pool设置为600MB以下。
实际上,为了使用ASMM,Oracle为这5个可自动调整的组件又提供了5个控制它们大小尺寸的参数,以“__”(两个下画线开头)。我们把当前的spfile导出到pfile里。
SQL> create pfile='/u01/init.ora' from spfile; |
打开该pfile以后,我们会发现文件的前5行,会显示如下的内容(具体值可能不一样):
ora10g.__db_cache_size=134217728 |
可以看到,这5个初始化参数都以“__”开头,后面的部分与我们手工设置内存池大小的参数相同。比如__db_cache_size与db_cache_size对应等。这种以“_”开头的参数我们叫做隐藏参数。所谓隐藏参数,就是没有官方文档对其含义进行说明的参数。这种参数会根据版本的不同而发生改变。这5个隐藏参数(比如__shared_pool_size)由MMAN进程负责修改,而与之相对应的其他参数(比如shared_pool_size)则由DBA进行设定。因此,当我们启动数据库时,数据库内核会在初始化参数__shared_pool_size与shared_pool_size之间进行比较。如果shared_pool_size没有设定,或设定为0,或设定的值比__shared_pool_size小,则以MMAN自动调整的值来设置内存池的尺寸。否则,以DBA设定的值来设置内存池的尺寸。
如果我们在数据库运行过程中,修改了某个可自动调整的内存池的大小,这时会怎么样?如果我们设置的值比MMAN自动调整出来的值要大,则该内存池立即调整为设定的值的大小,同时我们所设定的值作为MMAN新的、自动调整的最小值;反之,如果设置的值比MMAN自动调整出来的值要小,则该内存池的大小不会变化,而我们所设置的值则只作为自动调整的最小值存在。比如,当前MMAN自动调整出来的shared pool大小为150MB,也就是__shared_pool_size为150MB,同时shared_pool_size为60MB。这时,如果我们将参数shared_pool_size从60MB设置为100MB的话,则shared pool的大小仍然为150MB,但是新设置的100MB将作为自动调整时的下限;如果我们将参数shared_pool_size从60MB设置为200MB,则shared pool立即扩张,从150MB扩张到200MB,同时200MB也将作为自动调整的新的下限。
我们来验证一下。视图v$sga_dynamic_components里记录了能够动态调整的各个内存池的大小。
SQL> SELECT component, current_size/1024/1024 size_mb |
当前MMAN自动调整出来的shared pool大小为80MB。
SQL> alter system set shared_pool_size=70M; |
我们将shared_pool_size设定为70MB,小于自动调整出来的值。可以看到,shared pool没有缩小,仍然是80MB。我们再将其从80MB扩大到100MB。
SQL> alter system set shared_pool_size=100M; |
显然,只要我们设定的值比自动调整出来的值大,就会立即生效。
同时,如果当前我们启用了ASMM,同时并没有为这5个可以自动调整的内存池参数指定具体的值。当数据库在ASMM状态下运行一段时间以后,我们再禁用ASMM,会发生什么?我们来看下面的试验。
SQL> select name,value from v$parameter |
可以看到,除了shared pool为DBA指定以外(因为shared_pool_size大于0),其他的内存池都由ASMM指定。
SQL> select component, current_size FROM v$sga_dynamic_ |
我们看到,ASMM根据当前的负载情况,为这5个内存池指定了大小。
SQL> alter system set sga_target=0; |
当我们将sga_target设置为0,从而禁用ASMM时,会发现,Oracle会自动将当前内存池的大小赋给对应的初始化参数(shared_pool_size、db_cache_size等)。同时我们也可以注意到,shared_pool_size的值也不再是DBA当时指定的96468992,而是被ASMM自动调整出来的138412032所覆盖。
5.7 PGA管理
作为一个复杂的Oracle数据库系统来说,每时每刻都要处理不同用户所提交的SQL语句,获取数据并返回数据给用户。前面已经说到,解析SQL语句的工作是在Oracle实例中的shared pool所完成的。那么对于每个session来说,其执行SQL语句时所传入的绑定变量放在哪里?而且,对于那些需要执行比较复杂SQL的session来说,比如需要进行排序(sort)或hash连接(hash-join)时,这时,这些session所需要的内存空间又从哪里来?另外,还有与每个session相关的一些管理控制信息又放在哪里?对于诸如此类与每个session相关的一些内存的分配问题,Oracle通过引入PGA这个内存组件来进行解决。
5.7.1 PGA的概念及其包含的内存结构
PGA按照Oracle官方文档解释,叫做程序全局区(Program Global Area),但也有些资料上说还可以理解为进程全局区(Process Global Area)。这两者没有本质的区别,它首先是一个内存区域,其次,该区域中包含了与某个特定服务器进程相关的数据和控制信息。每个进程都具有自己私有的PGA区,这也就意味着,这块区域只能被其所属的进程进入,而不能被其他进程访问,所以在PGA中不需要latch这样的内存结构来保护其中的信息。
笼统地说,PGA里包含了当前进程所使用的有关操作系统资源的信息(比如打开的文件句柄等)以及一些与当前进程相关的一些私有的状态信息。每个PGA区都包含以下两部分。
固定PGA部分(Fixed PGA):这部分包含一些小的固定尺寸的变量,以及指向变化PGA部分的指针。
变化PGA部分(Variable PGA):这部分是按照堆(Heap)来进行组织的,所以这部分也叫做PGA堆。PGA堆中所包含的内存结构包括:
*有关一些固定表的永久性内存。
*如果session使用的是专用连接方式(dedicated server),则还含有用户全局区(User Global Area,UGA)子堆。如果session使用的是共享连接方式(shared server),则UGA位于SGA中。UGA是PGA中的最重要的部分。
*调用全局区(Call Global Area,CGA)子堆。
UGA是包含与某个特定session相关信息的内存区域,比如session的登录信息以及session私有的SQL区域等。每个UGA也包含以下两个部分。
固定UGA部分(Fixed UGA):这部分包含一些小的固定尺寸的变量,以及指向变化UGA部分的指针。
变化UGA部分(Variable UGA):这部分也是按照堆来进行组织的,可以从X$KSMUP视图中看到有关UGA堆的分布情况。UGA堆的分布与open_cursors、open_links等参数有关系。所谓的游标(cursor)就是放在这里的,游标指向shared pool里的包含SQL文本以及执行计划等的对象。UGA堆中所包含的内存结构介绍如下。
*私有SQL区域(Private SQL Area):这部分区域包含绑定变量信息以及运行时的内存结构等数据。每一个发出SQL语句的session都有自己的私有SQL区域。这部分区域又可分成以下两部分。
+永久内存区域:这里存放了相同SQL语句多次执行时都需要的一些游标信息,比如绑定变量信息、数据类型转换信息等。这部分内存只有在游标被关闭时才会被释放。
+运行时区域:在处理SQL语句时的第一步就是要创建运行时区域,这里存放了当SQL语句运行时所使用的一些信息。对于DML(INSERT、UPDATE、DELETE)语句来说,SQL语句执行完毕就释放该区域;而对于查询语句(SELECT)来说,则是在所有数据行都被获取并传递给用户以后被释放,或者该查询被取消以后也会被释放。
*Session相关的信息。这部分信息包括以下几部分。
+正在使用的包(package)的状态信息。
+使用alter session这样的命令所启用的跟踪信息,或者所修改的session级别的优化器参数(optimizer_mode)、排序参数(sort_area_size等)、修改的NLS参数等。
+所打开的db links。
+可使用的角色(roles)等。
+工作区(Work area):这块区域主要用来存放执行SQL的过程中所产生的中间数据,比如排序时,需要在这里存放排序过程中的中间数据。这部分占据了PGA中的大部分空间。其大小依赖于所要处理的SQL语句的复杂程度而定。如果SQL语句包含诸如group by、hash-join等这样的操作,则会需要很大的SQL工作区域。实际上,我们调整PGA也就是调整这块区域。
而UGA所处的位置完全由session连接的方式决定:
如果session是通过共享服务器(shared server)方式登录到数据库的,则毫无疑问,UGA必须能够被所有进程访问,所以在这种情况下,UGA是从SGA中进行分配的。进一步说,如果SGA中设置了large pool,则UGA从large pool里进行分配;否则,如果没有设置large pool,则UGA只能从shared pool里进行分配。
如果session是通过专用服务器(dedicated server)方式登录到数据库的,则UGA是从进程的PGA中进行分配的。
5.7.2 PGA自动管理
背景:在Oracle 9i之前,我们主要是通过设置sort_area_size、hash_area_size等参数值(通常都叫做*_area_size)来管理PGA的使用,不过严格说来,是对PGA中的UGA进行管理。但是,这里有个问题,就是这些参数都是针对某个session而言的,也就是说设置的参数值对所有登录到数据库的session都生效。在数据库实际运行过程中,总有些session需要的PGA多,而有些session需要的PGA少。如果都设置一个很小的*_area_size,则会使得某些SQL语句运行时由于需要将临时数据交换到磁盘而导致效率低下。而如果都设置一个很大的值,又有可能一方面浪费空间;另一方面,消耗过多内存可能导致操作系统其他组件所需要的内存短缺,而引起数据库整体性能下降。所以如何设置*_area_size的值一直都是DBA很头疼的一个问题。
而从Oracle 9i起(当然也包括Oracle 10g)所引入的一个新的特性可以有效的解决这个问题,这个特性就是自动PGA管理。
首先,设置workarea_size_policy参数。该参数为auto(也是默认值)时,表示启用PGA自动管理;而设置该参数为manual时,则表示禁用PGA自动管理,仍然沿用Oracle 9i之前的方式,也就是使用*_area_size对PGA进行管理。
然后,DBA可以根据数据库的负载情况估计所有session大概需要消耗的PGA的内存总和,然后把该值设置为初始化参数pga_aggregate_target的值即可。Oracle会按照每个session的需要为其分配PGA,同时会尽量维持整个PGA的内存总和不超过该参数所定义的值。这样的话,Oracle就能尽量避免整个PGA的内存容量异常增长而影响整个数据库的性能。从而,就有效的解决了设置*_area_size所带来的问题。
不过遗憾的是,Oracle 9i下的PGA自动管理只对专用连接方式有效,对共享连接方式无效。Oracle 10g以后对两种连接方式都有效。
在PGA中,对性能影响最大的就是SQL工作区了。通常来说,SQL工作区越大则对于SQL语句的执行的效率就高,从而对于用户的响应时间就越少。理想情况下,SQL工作区应该可以容纳SQL执行过程中所涉及的所有输入数据和控制信息。当然,这只是理想情况,现实往往总是不能尽如人意,很多情况下SQL工作区是不能容纳执行SQL所需要的内存空间的,从而不得不交换到临时表空间里。为了衡量执行SQL所需要的内存与实际分配给该SQL的SQL工作区之间的契合程度,Oracle将所分配的SQL工作区大小分成以下三种类型。
optimal尺寸:SQL语句能够完全在所分配的SQL工作区内完成所有的操作。这时的性能最佳。
onepass尺寸:SQL语句需要与磁盘上的临时表空间交互一次才能够在所分配的SQL工作区中完成所有的操作。
multipass尺寸:由于SQL工作区过小,从而导致SQL语句需要与磁盘上的临时表空间交互多次才能完成所有的操作。这个时候的性能将急剧下降。
当系统整体负载不大时,Oracle倾向于为每个session的PGA分配optimal尺寸大小的SQL工作区。
而随着负载上升,比如连接的session逐渐增多导致同时执行的SQL语句越来越多时,Oracle就会倾向于为每个session的PGA分配onepass尺寸大小的SQL工作区,甚至是multipass尺寸的SQL工作区了。
我们一旦设置了pga_aggregate_target以后,所有的*_area_size就将被忽略。那么,我们该如何来设置该参数的值呢?这依赖于数据库的用途,如果数据库为OLTP(联机事务处理)应用的,则其应用一般都是小的短的进程,所需要的PGA也相应较少,所以该值该值通常为总共分配给Oracle实例的20%,另外的80%则给了SGA;如果数据库为OLAP(DSS)(数据仓库或决策分析)应用的,则其应用一般都是很大的,运行时间很长的进程,因此需要的PGA就多。所以通常为PGA分配50%的内存。而如果数据库为混合类型的,则情况比较复杂,一般会先分配40%的初始值,而后随着数据库的应用,而不断对PGA进行监控,并进行相应的调整。
比如,对于8GB物理内存的数据库服务器来说,按照Oracle推荐的,分配给Oracle实例的内存为物理内存的80%。那么对于OLTP应用来说,pga_aggregate_target的值大约就是1310MB((8192MB×80%)×20%)。而对于OLAP来说,则该值大约就是3276MB((8192MB×80%)×50%)。
当然,这里所说的都是对于一个新的数据库来说,初始设置的值。这些值并不一定正确,可能设置过大,也可能设置过小。必须随着系统的不断运行,DBA需要不断监控,从而对其进行调整。
Oracle为了帮助我们确定这个参数的值,引入了一个新的视图v$pga_target_advice。为了使用该视图,需要将初始化参数statistics_level设置为typical(默认值)或all。
SQL> select
Target (M) Est. Cache Hit % Est. ReadWrite (M) Est. Over-Alloc |
该输出告诉我们,按照系统目前的运转情况,我们PGA设置的不同值所带来的不同效果。根据该输出,随着我们增加PGA的尺寸,estd_pga_cache_hit_percentage不断增加,同时estd_extra_bytes_rw(表示onepass、multipass读写的字节数)不断减小。从上面的结果我们可以知道,将pga_aggregate_target设置为60MB是最合理的,因为即便将其设置为480MB,命中率也不会有所提高。