Tachyon在Spark中的作用(Tachyon: Reliable, Memory Speed Storage for Cluster Computing Frameworks 论文阅读翻译)
摘要:
![]()
![]()
![]()
![]()
![]()

![]()
![]()
异步检查点的设置:
![]()
![]()
![]()
![]()
Tachyon是一种分布式文件系统,可以借助集群计算框架使得数据以内存的速度进行共享。当今的缓存技术优化了read过程,但是,write过程因为需要
容错机制,
就需要通过网络或者是磁盘进行复制操作。
Tachyon通过将“血统”技术引入到存储层进而消除了这个瓶颈。创建一个长期的以“血统机制”为基础的存储系统的关键挑战是失败情况发生的时候及时地进行数据恢复。
Tachyon通过引入一种检查点的算法来解决这个问题,这种方法保证了恢复过程的有限开销以及通过资源调度器下进行计算所需要的资源获取策略。我们的评审展示了
Tachyon的write性能超过HDFS达到100X,也将
现实
工作流的端到端的负载提升了4X。
(补充):
Tachyon是Spark生态系统内快速崛起的一个新项目。 本质上,
Tachyon是个分布式的内存文件系统, 它在减轻Spark内存压力的同时,也赋予了Spark内存快速大量数据读写的能力。Tachyon把内存存储的功能从Spark中分离出来, 使Spark可以更专注计算的本身, 以求通过更细的分工达到更高的执行效率。
Spark平台具体问题主要有以下几个:
- 当两个Spark作业需要共享数据时,必须通过写磁盘操作。比如:作业1要先把生成的数据写入HDFS,然后作业2再从HDFS把数据读出来。在此,磁盘的读写可能造成性能瓶颈。
- 由于Spark会利用自身的JVM对数据进行缓存,当Spark程序崩溃时,JVM进程退出,所缓存数据也随之丢失,因此在工作重启时又需要从HDFS把数据再次读出。
- 当两个Spark作业需操作相同的数据时,每个作业的JVM都需要缓存一份数据,不但造成资源浪费,也极易引发频繁的垃圾收集,造成性能的降低。
介绍:
虽然现在有很多程序框架和存储系统用来改善大规模数据的并行处理性能,但是,这些系统的瓶颈都是I/O操作过程,目前的解决方法是通过cache进行数据缓存。但是随之而来的问题就出现了,cache可以显著改善read性能,但是因为容错的需要,必须通过节点之间的数据传递对“写的数据”进行复制备份,但是,由于节点之间数据复制的过程中网络的延迟以及吞吐率性能的低下,导致即使数据被复制存储在内存中,write过程的性能也很差。
write性能低下会严重影响到job工作流的性能,因为job之间会彼此影响。为了改善写性能,我们提出了
Tachyon(一个基于内存的存储系统)来实现write和read的高吞吐率,同时没有牺牲容错机制。
Tachyon通过利用“血统“绕开了重复复制带来的吞吐率的局限性。采用的方法是通过再次对task之上的操作进行计算来
恢复
出错或者丢失的数据(跟Saprk的容错机制是一样的,只是在
Tachyon进行存储的阶段也是采用“血统”机制
)而无需进行数据备份。
然而,将“血统机制”引入连续不断的分布式存储系统中也是有一定挑战的。
(1)第一个挑战是,如何限制一个长期执行的存储系统的重复计算(容错操作)的开销。该挑战对于一个单一的计算job是不存在的,比如一个Mapreduce job或者是一个Spark job,因为在这种情况下重复计算的时间被job的执行时间所限制。相反,
Tachyon的执行过程是不确定的,这意味着重复计算的时间可能无法被限制。有一些框架比如Spark Streaming通过周期性(可以自己设置时间间隔)地设置检查点(checkpoint操作,设置checkpoint目录进行数据备份以及执行位置的标记)可以避开这个问题,但不幸的是,
Tachyon中基本不能照做,因为存储层不能感知到job当前的执行语义,job的计算特性的分类也十分广泛复杂。尤其是,当
可用的带宽无法满足
数据的写速度,固定时间间隔的检查点操作可能会导致无限制的数据恢复操作(因为job的执行情况是透明的,所以checkpoint设置的合理性至关重要)。相反,基于“血统图”进行数据检查点设置的
选择反而可以对重复计算过程进行限制。
(2)第二个挑战是如何为重复计算过程获取资源。比如,如果job之间有优先级的话,
Tachyon在一方面必须确保重复计算获取到足够的资源,在另一方面,重复计算不能影响到当前具有高优先级的正在执行的job的性能。
解决上述挑战的方法:
(1)第一个挑战:
Tachyon在后台通过异步执行某种算法不断的对相应文件设置检查点(文件信息备份)来解决第一个挑战。我们也提出了一个新奇的算法来决定何时以及选择哪一个文件来检查,这个算法叫做边沿算法(Edge algorithm
),这种算法对重复计算的开销进行了较好的限制。
(2)对于第二个挑战,
Tachyon提供了一种资源申请方案,该方案可以做到:准守严格的job优先级并按照权重进行资源分配。
论文最终得到的结论是:
Tachyon的write性能超过HDFS达到100X,也将现实工作流的端到端的负载提升了4X(相对基于内存的
HDFS
)。另外,
Tachyon可以将复制备份引起的网络传输减少高达50%。最后,基于对Facebook和Bing的跟踪,可以发现
Tachyon的重复计算开销占用的集群资源不超过1.6%。
更为重要的是,由于复制备份操作的固有带宽限制,未来,一个基于“血统”的容错模型可能是让集群存储系统能够匹配内存计算的唯一方法。
背景:
- (待改善的)目标的工作负载属性
- 数据的不变性。数据一旦进行write就不可变了,存储系统只是提供数据之上的扩展操作。
- 确定性的工作任务。MapReduce和Spark等框架都要求用户代码确定的情况下执行“血统”机制。对于工作任务不具有确定性的框架,就采用复制备份进行容错处理。
- 基于位置的调度。MapReduce和Spark等框架都是基于位置进行调度的,这样可以尽可能地减少网络传输的开销。
- 应用的工作区必须在内存,数据可以在磁盘。
- 尽量进行程序操作的复制,而尽量避免数据的复制。因为操作的复制开销要更小。(比如:相同的操作在大量数据之上反复被执行,代码书写的过程中,要选择让操作程序进行多次复制,而不是让数据进行复制)
- 避免复制操作(避免memory与其他媒介进行数据交换)的情景
一些基于内存的计算框架例如Spark确实加速了一些特定job的执行速度,但是,不同种类的job之间可靠的数据共享却成为瓶颈。
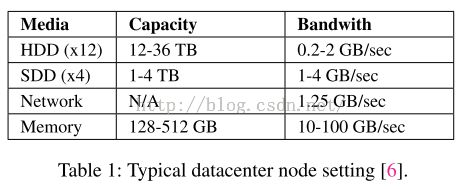
从上图可以看出,现在主流系统使用的媒介,HDD、SDD以及网络传输所支持的带宽都远远小于内存支持的带宽。
大数据处理过程中的数据共享开销往往会主导流水线端到端的时延。
现实中的数据表明有34%的job,
其
输出的
数据量
至少等于输入的数据量,在集群计算的过程中,这些job就会限制write的吞吐率。
硬件的改进无法解决上述问题。一个节点之上,内存的带宽比disk总体带宽要高出1~3个数量级。SDD的出现也没有太大作用,毕竟它相对磁盘的主要优势是随机访问的性能提升,而不是连续的I/O带宽的提升(表中可见),后者才是关键。
设计综述:
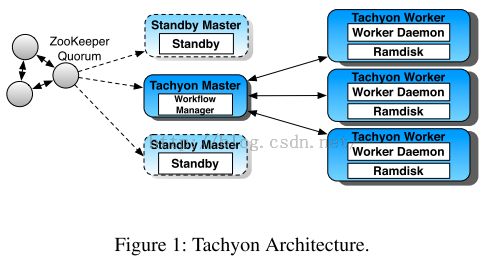
- 系统架构
Tachyon由两层组成:“血统”和持久化存储。“血统”层级提供很高的I/O吞吐率并且会追踪job执行的连续过程。持久化层主要被用于异步检查,持久化层可以是任何以数据备份为基础的存储系统,HDFS,S3等。
Tachyon采用了标准的master/slave架构:为了管理元数据,master必须包含一个workflow manager,该管理器的作用就是跟踪“血统”信息,计算检查点操作的顺序(对应第一个挑战)以及与集群资源管理器进行交互来为重新计算申请资源(第二个挑战)。
每一个worker上都跑着一个守护进程用来管理本地资源并且定期将worker状态报告给master节点。另外,每一个worker节点都会用RAMdisk来存储内存映像文件,用户的应用可以绕过守护进程直接和
RAMdisk进行交互,这样,一个具有数据本地性的应用可以避免不必要的数据拷贝,以内存速度进行数据交互。【内存文件管理系统】
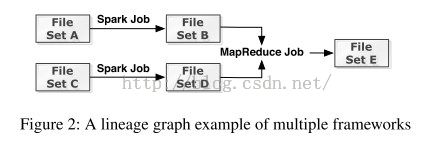
- 举例
需要注意的是,“血统”信息是存储在
Tachyon的持久化层的。
我们都知道,
Tachyon会通过避免复制备份来改善write性能,然而,复制备份对于很多job同时read读取相同的数据的情况有明显的优化作用。虽然,
Tachyon使用“血统”机制避免了数据的复制备份,但是
Tachyon并不是完全没有数据备份的。
Tachyon也使用客户端cache技术来对频繁读取操作的情况进行优化:当一个文件不在当前机器时,该文件会被从远程机器上读取过来并且缓存在
Tachyon本地的cache里面,这是
Tachyon中的数据备份现象
。
- API总结
需要特别说明的是,
Tachyon本身就是一个标准的文件管理系统,支持所有标准的文件管理操作,除此之外还提供了获取job操作过程的“血统”信息的API接口。并且,使用者如果仅仅将
Tachyon作为传统的文件管理系统来用,而不使用
Tachyon的“血统”的API接口,这种情况下,write性能将不会得到改善,读写性能与其他文件系统比如HDFS差不多。
- Lineage Overhead(“血统”开销)
从存储的方面来说,“血统”信息被累积存储在二进制文件当中,但是,根据微软的数据统计:一个典型的数据中心平均每天执行1000个job,并且花费1TB大小的容量来存储一年下来所有job执行生成的未压缩的二进制文件,这样的数据量对于一个很小的数据中心来说都是微不足道的。
此外,
Tachyon会对“血统”信息进行回收。
Tachyon在检查完输出文件之后会删除“血统”记录,这样会明显减少“血统”信息的大小。另外,在执行的过程中,那些定期执行的job任务通常会变换参数多次执行,在这种情况下,只有一份程序的拷贝会被存储。
- Data Eviction(数据回收)
当数据量不超过内存大小的时候,
Tachyon的执行性能很好,所以,问题就出现了:当内存占满的时候,数据如何回收呢?(有些数据使用率太低,需要移除内存,或者说从内存中删除)对于那些数据密集型的应用,我们在数据回收的时候考虑以下两个因素:
(1)访问频率
(2)访问的临时本地性(75%的二次访问都发生在6个小时之内)
在上述特性的影响下,我们使用LRU(近期最少使用算法)
作为默认的数据回收策略,当然LRU不一定适用于所有场景,所以
Tachyon同时也支持其他的数据回收策略。在下一个张章节中,我们会给出这样的描述:
Tachyon会将最大的文件除外的所有文件存储在内存中,大的文件直接存储在持久层。(就是spill过程)
- Master Fault-Tolerance
Tachyon通过master的备用节点进行master的容错处理。主master将自身每一步
的操作
以日志的形式都持久化存储在持久层之中,当主master节点出错的时候,备用节点通过读取日志(日志的大小微不足道)将自身改变成为与之前的master一样的状态。
- Handling Environment Changes
还有一类问题
Tachyon会遇到,就是如果框架的版本变了或者是系统版本变了我们如何通过“血统”信息
的二进制文件来支持重计算进而恢复文件数据。
(1)我们发现,系统变化之后,可以通过之前设置的检查点进行计算恢复操作。因此,在计算环境改变之前,我们需要做一些工作:
a)所有当前未复制的文件都被设置检查点(备份);
b)所有的新数据都被同步保存
当然,除了上述操作,我们可以直接简单地将所有数据进行复制即可。
(2)还有一种方法来更加高效地处理这种情况,用虚拟机映像单独保存所需的计算环境(不做介绍)。
- Why Storage Layer(为什么选择存储层)
选择将“血统”机制引入存储层的原因:
(1)多个job在流水线中会形成复杂的“血统”关系;并且,在一个生产环境中,数据的生产者和消费者可能会在不同的框架下面(一个job过程可以会涉及到多个框架之间的交互)。而且,仅仅在job级别或者是框架级别理解“血统”关系并没有什么卵用,我们应该深入到存储层对“血统”信息进行统计。
(2)一些信息只有存储层知道,比如什么时候文件重命名了或者什么时候文件被删除了,在存储层构建的“血统”才是最准确的。
检查点:
该部分其实是对Tachyon第一个挑战的解决说明。
Tachyon利用
checkpoint算法来限制因为出错导致的文件恢复的时间开销。不像MapReduce或Spark的job那样,生命周期很短,
Tachyon的job的生命周期很长
,也正因为“血统”信息的复杂,如果没有检查点的设置,那么会需要很长的时间来执行重计算(血统过于复杂)。还有就是持续执行的像Spark Streaming这样的数据流系统,
会获取到当前执行的job的动作语义来决定在那些文件上以及何时进行检查点操作。
Tachyon无法获取到job具体的语义动作,但是也要进行检查点的设置。
Tachyon的检查点设置的关键是”血统“允许后台以内存的速度异步执行检查点操作而不用停止写操作,且
Tachyon后台的检查点操作具有很低的优先级,目的是避免影响当前存在的job任务。
理想的checkpoint算法需要满足一下几点:
(1)限制重计算的时间。像
Tachyon这样长时间执行的系统,形成的”血统“链也很长,所以对于失败情况下的重计算操作的耗时要加以限制,需要注意的是,一旦我们限制了重计算的时间就意味着我们需要限制重计算所需的资源。
(2)为”热“文件进行检查点操作
(3)尽量避免为临时文件进行检查点操作
- Edge Algorithm
基于上述特性,我们设计了
Edge算法:
首先,
Edge将要检查的文件选择的是”血统“图的叶子(边沿)文件;
其次,
Edge会结合文件的优先级进行检查点操作,即优先为优先级高的文件设置检查点。
最后,
Edge会将可以放入内存的数据集进行内存缓存,那些太大的文件会直接存储在持久层,如果很大的文件也存储在内存,需要进行checkpoint的时候,就会出现内存与磁盘的数据交换。目的就是避免同步设置检查点将write的速度降低到磁盘的速度。接下来依次进行分析。
Checkpointing Leaves
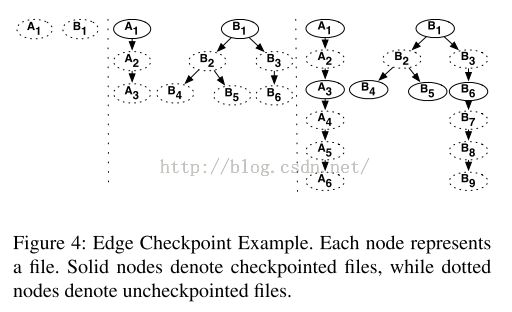
Edge算法用DAG表示文件之间的关系,其中,文件是节点,文件之间的关系(B是某job read A之后生成的)形成DAG图的边(A-B)。这种算法对DAG图的叶子(边沿)节点进行检查点操作。如下图:
上图表示了
Edge算法的工作过程。一开始,集群中只有两个job在运行,并生成了A1,B1。
Edge算法对A1,B1进行了检查点操作(备份),之后的阶段,A3,B4,B5,B6成为了叶子,并依次被进行检查点操作,之后阶段,A6,B9成为叶子。如果在A6进行检查点操作的时候出现了错误,
Tachyon只需要对A4~A6的过程进行
重新计算。
Checkpointing Hot Files
Tachyon分配优先级的策略是基于的是文件被读取的次数,与cache回收的LFU(最近最不常用页面置换算法)类似,保证了最频繁被获取的数据最先被进行checkpoint操作,这样显然可以加快数据恢复速度(容错处理)。
Edge算法必须平衡叶子节点和优先级高的节点的checkpoint的操作。我们通过下表进行分析。
该表展示了来自雅虎的3000个节点的mapreduce集群的文件使用次数统计。基于这个表,我们认为只要文件的访问次数查过2次,该文件就属于高优先级的文件。且基于该数据统计,发现86%的checkpointed文件都是叶子节点,因此,我们可以得到这样的结论:优先级高的文件最先被执行checkpoint操作(优先级高的文件本身就少,大概只有14%,但是仍然在checkpointed文件中占据14%的比例)。
一个以复制备份为基础的文件系统必须复制每一个文件,即使是job直接使用到的临时文件(也需要进行备份)。但是
Tachyon很对会对临时文件进行checkpoint(备份)操作,因为checkpoint操作针对的数据都比较靠后(叶子文件、优先级较高的文件),这样就使得临时文件在被执行checkpoint操作之前就会被删除掉(nice啊!)。
Dealing with Large Data Sets(大型数据集的处理)
job过程中除了很大的文件之外的几乎所有文件都被存储在内存中。
因为
96%的活跃jobs可以同时将自己的整个数据集保存在集群的内存中去,同时
Tachyon的master节点配置为可以同步地将上述数据集一次性写入磁盘。
需要注意的是,
系统框架可能会遇到高丛发性(爆发性)的数据请求,在请求爆发期间,
Edge算法会将内存中几乎所有的叶子节点以及非叶子节点都进行checkpoint处理(爆发性的数据请求会提升非叶子节点优先级,最终导致几乎所有的文件都checkpoint)。
如果内存中的文件都是没有被执行checkpoint的(特殊情况),那么
Tachyon会同时对这些文件进行checkpoint操作来避免产生较长的”血统“链。
Bounded Recovery Time
我们将对DAG图上特定
叶子文件
i上执行checkpoint操作所花费的时间用Wi表示;将通过祖先转换成叶子文件i的操作过程所花费的时间表示成Gi,可以得到:
定理一:
Edge算法可以保证任何文件(发生错误)在3*M的时间被恢复,其中,M=maxi{Ti},Ti=max(Wi, Gi).
上述定理表明,重复计算与DAG图的深度是无关的(
当数据集在内存中的时候,
cache的表现在重复计算的过程中是一样的)。
上述对重复计算限制的
定理
无法应用到checkpoint算法对优先级的考虑因素中去。但是我们可以很容易地得到优先级下checkpoint操作对
重复计算的限制:如果对叶子文件进行checkpoint的时间花费是c(在总的重复计算的时间中占用的比例),那么,优先级的checkpoint操作占用的时间就是1-c。
推论二:已知,
对叶子文件进行checkpoint的时间花费是c(在总的重复计算的时间中占用的比例)。Edge算法可以保证任何文件(发生错误)在(3*M)/c的时间被恢复,其中,M=maxi{Ti},Ti=max(Wi, Gi).
Resource Allocation资源申请
该部分其实是对Tachyon第二个挑战的解决说明。
虽然Edge算法已经对重计算进行了限制,
Tachyon还需要一种资源分配策略用于调度job的重计算。此外,
Tachyon还必须遵守集群汇总现有的资源分配策略,比如均分或者是按照优先级分配。
在很多情况下会有空闲的资源可以用于重计算,因为大部分计算中心计算资源的利用率只有30%~50%。当集群资源用完的时候,就需要考虑到相关的资源的分配问题。举一个例子,假如一个集群资源被三个job J1,J2,J3占据,同时有两个
丢失的文件F1,F2,需要执行 R1,R2两个job进行再计算才可以恢复。J2仅仅需要F2。
Tachyon怎么在考虑优先级的情况下安排重计算过程?
Tachyon的
一个解决方案是进行集群资源的静态分配,比如将集群资源的25%分配给重计算过程。很显然,如果没有重计算任务这种方法限制了集群的利用率。另外,采用静态资源分配的策略,就会出现很多因素的影响,比如,上述情况,如果更高优先级的jobJ3需要文件F2,
Tachyon应该如何调整R2的优先级呢?因此,我们需要明确三个目标:
(1)优先级的配合度。如果一个低优先级的job需要文件,针对该过程的重计算过程应该尽可能小地影响更高优先级的job。但是,如果该文件后来被一个更高优先级的job所需要,用于执行数据恢复工作的job的优先级应该提升。(也就是说文件的恢复job的优先级会随着获取文件的job的优先级来决定)
(2)资源共享。没有重计算任务,集群就执行正常任务(不是静态资源分配)。
(3)避免重计算的串联操作。出错情况发生的时候,同时可能不只是一个文件会发生丢失,如果不考虑数据的依赖关系就对这些文件进行重计算可能会引起递归的重计算job的产生。
我们现提出可以满足前两个目标的策略,再来讨论如何实现最后一个目标。
- Resource Allocation Strategy
资源申请策略依赖于Tachyon所使用的调度方法。
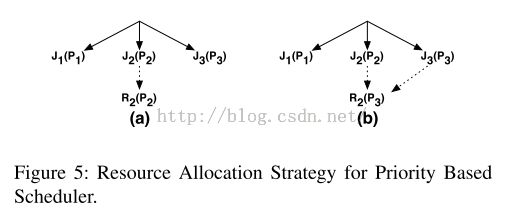
Priority Based Scheduler
在优先级的调度器中,举一个类似的例子。
假如一个集群资源被三个job J1,J2,J3占据,三个job各自的优先级是P1,P2,P3。
方法是,默认情况下所有的重计算job都只有最低的优先级,所以他们对其他的job有最低限度的影响。然而,这样会导致
“优先级反转”
:例如,文件F2的重计算job R2比J2有更低的优先级,此时当J2占用集群中所有的优先级的时候对F2文件进行获取,R2是得不到执行资源的,J2因为得不到F2也会因此被阻塞
。
我们通过优先级的继承关系来解决。当J2获取F2的时候,
Tachyon增加R2的优先级到P2。当J3获取F2的时候,再将R2的优先级升至P3,如下图所示:
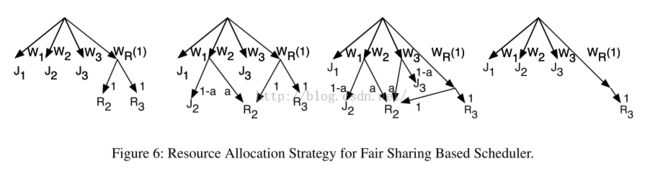
Fair Sharing Based Scheduler
在共享调度中,J1,J2,J3各自分享W1,W1,W3的资源(最小的分享单位是1)。
在我们的解决方法中,重计算的jobs一起共享分配的资源,被
Tachyon分配好的的默认的资源Wr。当错误发生的时候,所有丢失文件的重计算job可以共享到Wr中的“1个资源”。
此时,当一个job需要上述丢失的文件的时候,请求数据的job的一部分资源会被转移到那些针对这些文件的重计算job上去。比如,当J2需要F2的时候,J2会分到(1-a)*W1的资源,而R2会分到a*W1的资源。如下图所示;
上述的方法满足了我们的目标。因为重计算的job的
资源来自需要该缺失文件的job,所以,该过程不会对其他正常的job产生影响。
Recomputation Order
如果执行重计算的过程中没有对重计算的操作限定顺序,那么程序递归地对丢失的文件调用重计算操作就会有很低的性能。比如,如果job的优先级很低的话,该job很一直等待资源。如果改job的优先级很高,那么针对一个将来注定丢失的文件的前期计算就显得徒劳无功了。所以工作流管理器提前决定好文件重计算的顺序进而可以对他们进行调度。
为了决定哪些文件需要进行重计算,
工作流管理器维护了一个DAG图。DAG图中的每一个节点代表一个需要进行恢复的文件。在这个DAG图中,存在窄依赖和宽依赖(概念和Spark的一致)。这些依赖关系形成的DAG图是总的DAG图的子图。
为了构建这样的DAG图,工作管理器会对目标文件进行DFS,如果当前文件节点在存储层可用的时候,
DFS过程会停止。DFS访问到的节点必须是需要被重计算的。DAG图中的节点的计算顺序是逆序的,就是说,只有孩子节点都变为可用的时候当前节点才可以开始计算。上述计算过程是资源管理器执行的。
Implementation(实现)
Tachyon使用已经存在的存储系统来作为自己的持久化层,且
Tachyon还使用 Apache
ZooKeeper来主导master的错误容忍。
- Lineage Metadata
(1)Ordered input files list
因为文件名可能会发生变化,但是每个文件在顺序表中都有一个独特的不可变的文件ID,这样就可以保证应用在将来可能会出现重计算的情况,如果发生的话,重计算的时候就能按照程序第一次执行时候的顺序来读取相同的文件进行后续操作。
(2)Ordered output files list
该列表与
input files list原理一样。
(3)Binary program for recomputation
很多种方法实现一个重计算程序。一种天真的方法是为每一个应用写一个有针对性的程序,一个稍微有点素养的程序员都不会这样做的。另一种方法是写一个类似于“装饰器”的程序,该程序既能“读懂”Tachyon的
“血统”信息,又能理解
应用的逻辑关系。虽然这样的程序貌似非常灵活,但是也只能在一些特殊的框架(兼容这样的“装饰器”)下实现。
(4)
Program configuration
关于所需的配置文件,Tachyon使用“装饰器”程序读取配置文件:在“血统”提交的时候使用
”装饰器“对配置文件进行序列化,之后在重计算阶段解序列化。
(5)Dependency type
宽依赖和窄依赖。
- Framework Integration(框架整合)
程序运行的过程中,在它写文件之前会将一些信息提交给
Tachyon,然后,当程序写文件的时候,
Tachyon会判断该文件是否在”血统“之中,如果在,该文件就可以被写入内存(说明要采用”血统“机制进行容错处理)。如果文件需要进行重计算,
Tachyon会使用之前的”装饰器“程序将文件的”血统“信息以及丢失的文件列表提交给重计算程序来重新生成相关的数据。
- Recomputation Granularity(粒度)
关于重计算的粒度选择问题。首先,我们可以选择的粒度是job,比如,一个map job产生了10个文件,但是有一个文件丢失了,对于job级别的恢复,
Tachyon会恢复10个文件。其次,如果我们选择的粒度是task,这样,执行过程会变得复杂,但是效率会提升很多。MapReduce和Spark的层级是task级别的。
Evaluation
基础平台:
Ama
zon EC2 cluster with 10 Gbps Ethernet. Each node had 32
cores, 244GB RAM, and 240GB of SSD. We used Hadoop
(2.3.0) and Spark (0.9).
(1)Tachyon
(2)
in-memory installation of
Hadoop’s HDFS (over RAMFS), which we dub MemHDFS.
MemHDFS的writes操作的重计算数据的恢复仍旧会借助network,但是没有了disk的性能限制。
比较结果如下:
性能:
- Tachyon的write速度比MemHDFS快100X;
- 对于 multi-job workflow而言Tachyon的处理速度是MemHDFS的4X;在出错的情况下,大约花费了1分钟的时间进行数据库的恢复。Tachyon要比快3.8X;
- Tachyon帮助基于内存的框架,通过将虚拟机存储转移至堆外内存(直接受操作系统管理)来改善的延迟;
- Tachyon恢复master的失败仅仅需要不到1秒。
Edge算法超过任何固定间隔的检查点设置方法,分析表明
Tachyon可以将数据复制备份引起的网络交互降至50%。
重计算的影响:
重计算对其他的job几乎没有影响;另外,通过对Facebook和Bing的跟踪,重计算对集群资源的消耗不会超过1.6%。
接下来是具体的性能比较过程。
- 性能
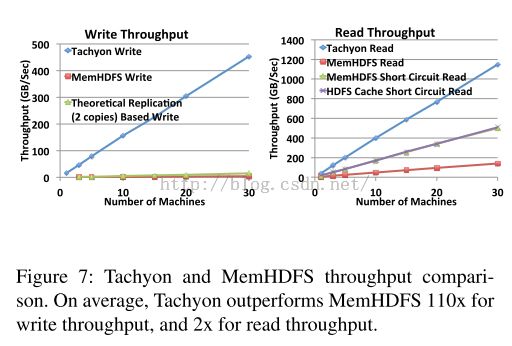
Raw Performance
实验中,集群中的每一个节点会开启32个进程,每一个进程读/写1GB的数据。结果如下图:
对于写而言,Tachyon实现了15GB/sec/node的吞吐率。然而,尽管使用的是10Gbps的带宽,MemHDFS的写吞吐率只有0.14GB/sec/node,原因就是由于需要数据备份带来的网络瓶颈。我们同时可以看出,理论上在硬件之上采用一次备份的最大的性能也只有 0.5GB/sec/node。平均来看,
Tachyon的write速度比
MemHDFS快100X,而理论上以复制为基础的write速度极限是
MemHDFS
的
30X。
对于读而言,Tachyon实现了38GB/sec/node。我们通过加入cache缓存以及 short-circuit reads(数据的本地性)的方法优化了HDFS读性能,但是MemHDFS也仅仅实现了17 GB/sec/node的速度。像这样速度上2倍的差距的原因就是,HDFS API因为调用了java I/O streams 仍然需要额外的内存数据备份。
另外,Tachyon读的性能要好于写的性能,因为硬件的设计为read留了更多带宽。
Realistic Workflow
实验中我们测试Tachyon的工作流是基于一个媒体信息分析公司在一小时内执行较多job来进行的。包含周期性的提取、转换、加载(
ETL过程:用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。
)过程以及针对job进行测量的相关报告。
实验运行的环境是拥有30个节点的EC2(
亚马逊弹性计算云
)集群上面。整个工作流分为20批次的作业,共包含240个job(其中每个批次有8个Spark job以及4个MapReduce job)。每批作业读1TB的数据并产生500GB的数据。我们使用Spark的Grep job来仿真ETL应用,用MapReduce的WordCount来仿真测试分析的应用。且每批次的作业,我们运行两个Grep应用来提前处理数据,之后我们运行WordCount作业来读取处理之后的数据并计算最终的结果,得到最终结果之后,数据就会被删掉。
我们测量了Tachyon以及MemHDFS上面运行的工作流的端到端的延迟。为了模仿真实的场景,元数据一旦写入系统我们就开始进行测量。对
Tachyon而言,我们还测量了一个node失败的时间消耗。
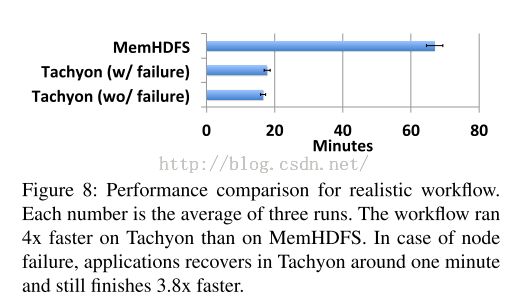
上图展示了相关性能:
可以看出
Tachyon上的执行时间大约为16.6min,而MemHDFS则用时67min。加速比大约为4倍关系。当
Tachyon上发生失败情况的时候,时间也仅仅多耗费了1min,加速比仍旧有3.8倍。
对
Tachyon而言,主要的负载是序列化和反序列化(空间开销和时间开销)
,这个实验使用的是
Hadoop TextInputFormat(
主要用于描述输入数据的格式,功能:
数据切分和
为Mapper提供输入数据
),如果使用更加高效的序列化模式,性能会有所提升。
Overhead in Single Job(单个job的负载)
当我们运行一个单独的job的时候,可以发现Tachyon能带来更小的负载并且可以通过减少没用的负载来改善内存框架的性能。我们使用Spark的一个worker节点(不要Tachyon)来运行Word Count job,通过两种方式进行缓存,一种是解序列化的java对象,一种是序列化的字节数组。相比较使用Tachyon进行缓存,当数据量小的时候,两者是类似的。当数据量变大的时候,
Tachyon
更快,因为Tachyon避免了使用java的内存管理机制。Spark1.0.0已经将Tachyon作为默认的堆外存储方法。
Master Fault Tolerance
Tachyon使用
热门线路备份(之前的等待master节点)来实现更快的master节点恢复。时延发现热门线路备份可以在0.5s之内取代当前出错的master节点,且在标准误差0.1s之内。上述实现的性能是可能的,因为取代的过程是备用master不断
通过当前master的日志文件数据来
获取更新自己的数据信息。
- Asynchronous Checkpointing(异步检查点的设置)
Edge Checkpointing Algorithm
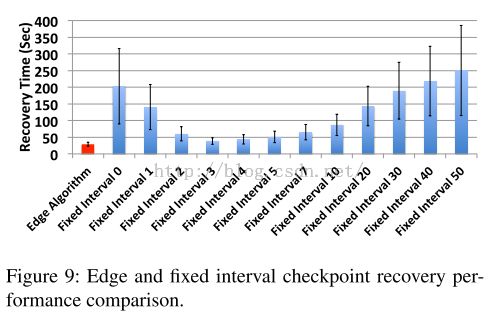
我们通过比较Edge算法和固定时间间隔的检查点设置的算法来最终对Edge算法进行评估。
我们用100个jobs模拟一个迭代的工作流,整个过程的执行时间遵从高斯分布
(正态分布
),
平均来看
每个job用时为10s。
每个job的数据输出过程(write)都需要固定的15s的总时间来进行检查点的设置。操作过程中,任意时刻node都可能出错。
从上图可以看出,Edge算法优于固定时间间隔的算法。对固定时间间隔的策略而言,如果时间间隔设置的太小,检查点的设置就跟不上程序执行速度。如果时间间隔设置太大,检查点的设置间隔时间就会很长,数据恢复时间就会受到影响。并且,即使采用最优的固定时间间隔方法,性能也比不上
Edge算法,因为
Edge算法可以根据程序执行的过程以及状态进行检查点设置的时间间隔的调整。
Network Traffic Reduction
那些采用数据复制进行容错的文件系统在数据密集型的集群中几乎占用了一半的网络通信。Tachyon可以减少通信的消耗,原因是Tachyon在异步的检查点设置的过程中可以避免对那些会被删除的临时文件进行检查点的设置。带宽节省下来了,性能自然会提升。
分析如下:
(1
)T表示
job执行的时间
与
对job输出的数据进行检查点设置的时间
(网络带宽)
的比例。比如,测试一个Spark Grep程序,得到T=4.5,说明job运行的速度是网络带宽的4.5倍。其实,T值的大小主要取决于网络带宽或者说是I/O。
(2)X表示生成数据的job的百分比。
(3)Y表示读取前面job的输出数据(组建“血统”)的job的百分比,如果Y=100,则会形成一个“血统”链,如果Y是0,则“血统”的深度就是1。
因此,我们尝试着将X置为60,将Y置为84,并使用Edge算法
来模拟1000个jobs的执行过程。取决于T,通过复制备份操作之后保存下来的网络通信的百分比的情况:当T=4是40%,当T>=10的时候是50%。(也就是说,X和Y固定的情况下,检查点设置操作的带框越小,T越大,表示网络通信越快 ----Tachyon)
- Recomputation Impact
Recomputation Resource Consumption(消耗)
我们会通过计算模型以及对FaceBook和Bing的追踪来计算重计算过程所需的资源。
我们的分析建立在下面的假设之上:
(1)每个机器的平均失效时间是3年。且如果一个集群包含1000个节点,平均每天会有一个节点出现失败的情况。
(2)可以负担的检查点设置的吞吐率是200MB/s/node。
(3)资源消耗用机器时间(machine-hours
)来测量。
(4)分析的过程中,认为Tachyon仅仅在job级别,使用粗粒度的重计算在最差的情况下进行测试(不用支持细粒度的task级别的重计算)
Worst-case analysis
最坏的情况下,一个节点出错,且其内存中的数据都是没有设置检查点的,需要task用超过200MB/sec的速度进行数据的再生。如果一个机器拥有128GB的内存,那么需要655秒的时间重计算丢失的数据。即使数据是连续存放的,其他的机器在这个过程都是阻塞的,因为这些机器都是需要依据这些数据进行并行计算的。在上述情况下,重计算过程占用了集群运行时间的0.7%。
上述的开销是与集群的大小和内存的大下呈线性关系的,如果集群有5000个节点,每个节点有1TB的内存,重计算的开销可以达到集群资源的30%。
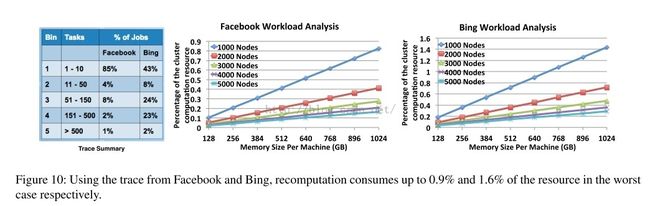
Real traces
现实的工作流程中,Tachyon的重计算的开销要远远小于上述最差的情况,因为job之间是独立的,几乎不会影响整个集群,因此一个节点失败不会阻塞其他的节点。
上图根据对FaceBook和Bing的追踪来比较不同内存和不同节点数的集群资源占用情况,可以看出正常情况下Tachyon的性能
。
Related Work
- Distributed Storage Systems
在大数据分析中,分布式文件系统以及key/value存储系统都是通过将数据复制到不同的节点进行容错处理的。这些系统write的吞吐率是受到网络带宽的限制的。不管这些系统如何优化,他们的吞吐率与内存的吞吐率相比都查的很远。Tachyon在存储层使用“血统”的概念来避开复制备份的操作,且利用内存进行单一的存储来提升性能。 Apache HDFS社区考虑将“血统”引入系统中,此灵感也是来自于Tachyon。
【补充】
Batch-Aware Distributed File System(BAD-FS),该类型的系统有两部分组成:
(1)
storage层expose了诸如caching、consistency、replication等通常固定的控制策略;
(2)scheduler层使用这些控制来适应不同的工作流,这样能够针对特定的工作流来处理例如cache consistency、fault tolerance、space management等问题,使存储和计算协调一致。
BAD-FS将传统文件系统的各种控制从File system转到了scheduler。这样的好处是:提高性能;优化错误处理;简化实现。
[
BAD-FS]为存储过程单独提供了一个调度器,提供额外的控制作用。用户通过说明式的语言将jobs提交给调度器,系统也因此知道了jobs之间的“血统”关系。然而,为了让上述过程在并行大数据引擎上面成为现实,有两个基本的问题:
(1)确保调度器和存储层之间的交互是正确的,比如避免死锁或者是优先级反转情况的出现。
(2)限制重计算的时间
对于第一个问题(对应论文开始的资源申请的挑战),我们会提供避免死锁或者是优先级反转的机制,同时也会考虑到调度器的策略。对于第二个问题(对应论文开始的限制重计算时间的挑战),我们会提供异步的检查点设置算法,该算法利用“血统图”在后台不停地执行检查点设置来确保优先的恢复时间。
- Cluster Computation Frameworks
Spark在一个单独job的执行过程中使用“血统”信息,且运行在一个单独的JVM里面。Spark中不同的不同种类的查询无法用一个稳定且高吞吐率的方法来共享数据集(RDD),因为Spark是一个计算框架,而不是一个存储系统。我们通过将Tachyon与Spark进行集成,通过
进行稳定的数据集共享
充分改善了Spark jobs的工作流程处理性能
。并且,Spark在Tachyon的异步检查点设置的过程中也会受益,因为它实现了高吞吐率的write过程。
其他的系统比如MapReduce和Dryad(微软的分布式运算框架)也会在一个job的执行过程中跟踪task的“血统”信息。但是这些系统不像Spark可以整合Tachyon,他们无法跟踪文件之间的关系,也因此无法在不同的job之间提供高吞吐率的数据共享。
- Caching Systems
【补充】DryadLINQ
是一个把LINQ
程序(
LINQ即Language Integrated Query(语言集成查询),LINQ是集成到C#和Visual Basic.NET这些语言中用于提供查询数据能力的一个新特性
)转化成分布式计算指令,以便运行于PC集群的编译器。
[
Nectar]
类似Tachyon,
Nectar也会使用“血统”的概念,但是,
Nectar仅仅服务于特定的程序框架
DryadLINQ,并且整合于传统的,复制的文件系统中。
Nectar是一个数据复用系统,服务于
DryadLINQ查询操作,目标是节省空间且避免多余计算。
(1)
节省空间:删除大量无用文件,如果需要再次使用,就会重新运行产生这些文件的job。但是数据的恢复过程是没有时间限制的。
(2)
避免多余计算:标示不同程序里面比较普遍的代码块进而找到那些经过相同计算得到的文件,加以重复利用。作为对比,
Tachyon的目标是通过不同的基于内存的以及有限的数据恢复时间的框架来提供数据共享。
[
PACMan]是一个基于内存的缓存系统,适用于数据密集型的并行工作。该系统探索了不同的策略,目的是让数据仓库的缓存效率更加高效。然而,PACMan没有改善write的性能,也没有改善第一次read的性能。
- Lineage
除了上述领域,“血统”已经被应用在很多其他的领域当中了,比如科学计算、数据库、分布式计算等等,也被应用在提供历史数据的应用中。Tachyon在不同的环境下使用“血统”来实现内存速度的读写吞吐率。
- Checkpoint Research
检查点的设置已经成为了一个很值得的研究领域。大多数的研究是在当失败情况发生的时候如何将重新计算的开销最小化。但是,不像之前
使用同步的检查点设置
的那些work操作,
Tachyon会在后台进行异步的检查点设置,这样的话就算一个检查点设置操作没有完成,也可以通过“血统”来进行丢失数据的重计算。
Limitations and Future Work
Tachyon致力于改善其目标工作多负载的性能,且评估也展示出了令人欣喜的结果。但是我们也从中意识到了
Tachyon的局限性,比如CPU密集型或者是网络密集型的jobs的处理。另外,还有一些将来要面临的挑战:
(1)Random Access Abstractions(随机访问抽象)
运行jobs的数据密集型的应用会向
像
Tachyon这样的
存储系统输出文件。通常,这些文件会被DBMS进行再加工来让面向用户的应用使用这些数据。因此,Tachyon提供高层次的只读随机访问抽象,比如在已有的文件之上提供key/value接口,可以缩短数据管道并且让数据密集型的jobs输出的数据立即变为可用的数据。
(2)Mutable data(可变的数据)
“血统”一般无法进行高效率的细粒度的随机访问更新也是挑战之一。但是针对这个问题有很多的方向,比如定向更新一集批量更新。
(3)Multi-tenancy(多重租赁
)
对于Tachyon而言,内存公平共享是重要的研究方向。像LRU/LFU这些策略可以提供好的整体性能,但是要以对每一个用户进行隔离操作为代价。另外,安全也是处理过程的另外一个有趣的问题。
(4)Hierarchical(分等级) storage
虽然内存的容量每年都是以置数形式增长的,但是相对于内存的替代品而言还是很昂贵的。一个早期的Tachyon研究者表示,除了要使用内存这一层级,
Tachyon也应该使用NVRAM(
非易失随机存取存储器
)和SSDs。将来,我们将会研究如何在
Tachyon中支持层级存储。
(5)Checkpoint Algorithm Optimizations
我们已经提出了Edge算法来提供一个受限的重计算时间。然而,也会有其他的技术考虑到不同的度量标准,比如检查点设置开销,单个文件恢复开销,多有文件恢复开销等。我们将这些改进留给社区来进一步探索。
Conclusion
随着以数据为中心的工作负载开始存在于内存,write的吞吐率就成为了应用的主要瓶颈。因此,我们认为以“血统”为基础的数据恢复的方法或许是唯一实现集群储存系统
加速
内存吞吐率的方法。我们提出了
Tachyon,一个基于内存的存储系统,该系统引进了“血统”来加速由决定性的批量jobs组成的工作负载的关键部分的处理。在让Tachyon有实际用途的过程中,我们定位并解决了一些关键的挑战。我们的评估展示了Tachyon在目前的存储方案上提供了可靠的加速。相似的方法也被HDFS社区采纳以便在集群中高效地利用内存。Tachyon目前已经开源。