Hadoop(一)理论体系
随着人民生活水平的提高,随着各种各类数据指数级的增长,“大数据”、“互联网+”、“云时代”等等各种名词已经成为当今社会的潮流,各种数据分析建立在TB,PB,EB,甚至ZB和YB数量级上,以前看似遥不可及,现在已经屡见不鲜。而如何很好的利用好这些数据,使之为我们产生巨大的商业价值,已经是当今IT界的精英们不断突破的方向。而Hadoop则是如今处理这些问题,最基础,最主流,开源并不断改进的一款分布式系统基础架构。好,我也来凑凑热闹,这篇简单讲述Hadoop的理论方面。
一,Hadoop是什么?
Hadoop是一个由Apache基金会所提高的分布式系统基础架构,核心由HDFS(分布式文件系统,HadoopDistributed File System)和MapReduce(Map分组,Reduce合并,分而治之,并而统一)组成。简单称之为 “分布式文件系统+计算框架”。
二,Hadoop历史:
1,思想之源:来自于Google的低成本之道,通过利用普通的PC机的累加,来避免超级计算机的高成本支出,并且极易扩展。再加上Google的网页搜索大量的计算量,大量的数据量,由最初的Page Rankd,到后来的map-reduce分而治之的计算思想,而将大量的计算量分到每台PC机上,Google设计了HDFS的前身版GFS(Google FileSystem)。也就是由Google各种思想,各种设计方案的启发,Hadoop随之而诞生。
2,项目起源:
Hadoop由 Apache Software Foundation公司于2005年秋天作为Lucene的子项目Nutch的一部分正式引入。2006年3月份,Map/Reduce和 Nutch Distributed File System(NDFS) 分别被纳入称为 Hadoop 的项目中。而它的名字来源于Doug Cutting儿子的玩具大象。
3,目前:商业化
目前有很多公司开始提供基于Hadoop的商业软件、支持、服务以及培训。Cloudera是一家美国的企业软件公司,该公司在2008年开始提供基于Hadoop的软件和服务。GoGrid是一家云计算基础设施公司,在2012年,该公司与Cloudera合作加速了企业采纳基于Hadoop应用的步伐。Dataguise公司是一家数据安全公司,同样在2012年该公司推出了一款针对Hadoop的数据保护和风险评估。
三,优点:
1,高可靠性:因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。
2,高扩展性:Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
3,高效性:Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
4,高容错性:Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
5,低成本:与一体机、商用数据仓库等相比,hadoop是开源的,项目的软件成本因此会大大降低,硬件只是需要普通的PC机即可达到,因此总成本大大降低。
此外:Hadoop带有用Java语言编写的框架,因此可以在linux生产平台上非常理想的运行。
四,整体架构:
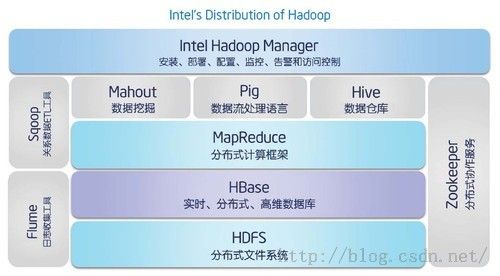
Hadoop知识框架由底层的分布式文件结构做基础,NOSQL数据HBase做数据库,MapReduce做计算框架,还有Pig,Hive,Mahout各种工具。后边回一一进行介绍。
下边是Hadoop的linux集群架构图,可以不断进行扩展数据节点:
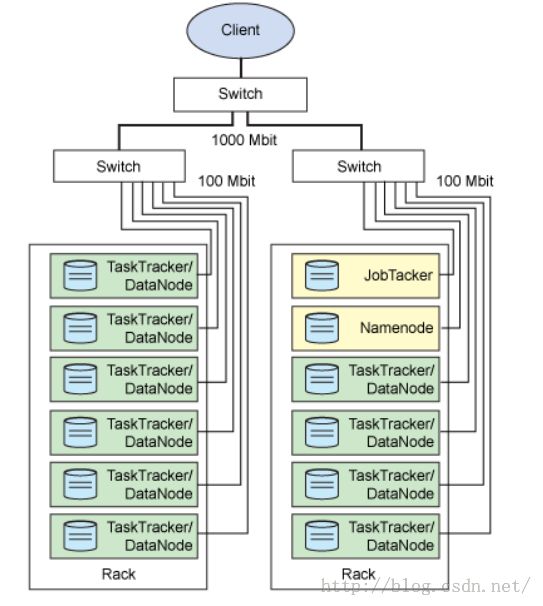
其实,Hadoop的思想就是“团结”。如今一直在强调合作,一个人的力量再大,智慧再高,精力再强,也不如一群人一起的力量大。更形象一点就像管理:对于公司由大领导(Master)进行分配任务,人员调配,每位员工(slave)努力完成自己负责的工作,小目标,整合起来就完成公司的大目标,使公司整体高效的向前前进。可见软件的演进越来越接近人类的思想。从面向过程——》面向对象——》面向服务,再到Hadoop这个具体例子……