机器学习理论与实战(十四)概率图模型02
02 概率图模型定义
翻开Jordan和Wainwright著作的书,正文开始(第二章)就说概率图模型的核心就是:分解(factorization)。的确是这样的,对于复杂的概率图模型,要在复杂交织的变量中求取某个变量的边缘概率,常规的做法就是套用贝叶斯公式,积分掉其他不相干的变量,假设每个变量的取值状态为N,如果有M个变量,那么一个图模型的配置空间就有N^M,指数增长的哦,就这个配置空间已经让我们吃不消了,不可以在多项式时间内计算完成,求边缘概率就没办法开展下去了。此时分解就派上用场咯,我们想法找到一些条件独立,使得整个概率图模型分解成一个个的团块,然后求取团块的概率,这样就可以把大区域的指数增长降为小区域的指数增长。毕竟100^20这样的计算量比25*(4^20)的计算量大多咯。好了,不说这么抽象了,下面进入正题:
先来看看图的定义,一个图由顶点V和边E组成:G=(V,E)V={1,2,...,m},E⊂V×V,有向边用(s→t)表示,无向边用(t,s)或者(s,t)表示。一个顶点S对应一个随机变量
(图一)
在(图一)中要注意下(b)和(c )的区别,因为(b)是有向无环图(Directed acyclic graph-DAG),也就是没有形成回路的,而(c )是有环的,(图一)的下部分也给出了解释。在有向图中给定一个顶点u,那么的祖先就是所有沿着有向边能到达u的所有顶点,如下面的路径中 ,s就是u的祖先。我们用 表示节点s的祖先,让 表示关于变量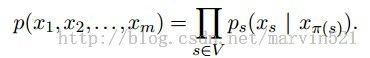
(公式一)
(公式一)得出是用归纳法推导的, 其实就是个条件概率,如果你不向追究原因,只要知道有向图可以按照(公式一)分解就行了,后面也会给出一个直观的解释。下面看看无向图如何分解,无向图如(图二)所示:
(图二)
无向图模型又称马尔科夫随机场(markov random filed)无向图模型的分解就是通过团块(clique)来完成,所谓团块就是 全连接的最大子图,如(图二)所示,(a)图的{1,2,3,4},{4,5,6},{6,7}都是全连接的最大子图,假设团块用C表示,为每个团块分配一个兼容函数(compatibility function)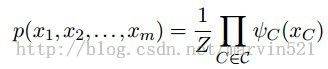
(公式二)
(公式二)中的Z是归一化的常量,学名叫配分函数(partition function),一归一化就成概率了,不归一化不满足概率和为1的性质。为了能在图模型中直观的看到团块,可以用因子图(factor graph)来表示无向图模型,如(图二)(b)所示,和黑块连接的顶点表示全部互相连接(全连接),一个黑块部分表示一个团块,所以上面分解又多了一个名字:因子分解(factorization)。
上面说了很多枯燥的定义,目标只有一个,引出两种图模型的分解公式:(公式一)和(公式二),那为什么可以分解成那个样子?现在通过两个小例子说明一下:
对于有向图模型,如(图三)所示模型,一个人的聪明程度(Intelligence)可以影响他的年级(Grade:痴呆的读高年级的概率低,聪明的一般走的比较远),而且对他的成绩(SAT)也有高低影响。当我们知道一个人的聪明度后,年级和成绩还有关系吗?二本就根本没有关系,在这里不要想多,其实很简单,给定一个物体后,那么这个物体上的两个属性值就决定了,已经存在的事实,所以二者是独立的。朴素贝叶斯就是根据这个条件独立做的分解。
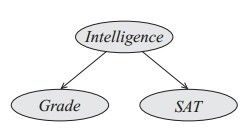
(图三)
另外注意一下,这里给定的是父亲节点,(公式一)中也强调了这点,如果不给父亲节点,条件独立就变的稍微复杂一些,如(图四)中有一个比(图三)稍微复杂一些的有向图模型:

(图四)
在(图四)中Difficulty表示试卷难度,Intelligence表示考生聪明度,如果什么都不给,这二者是独立的,因为试卷难度和考生没有关系,所谓的高考很难,但是这跟我有什么关系?我又不参加高考^.^,但是如果一旦给定空考生的年级(grade),情况就变得不一样了,比如考生考到了博士,如果他不聪明,那说明啥?说明卷子不难,水的很,如果卷子很难,考生一定很聪明,所以这中间有个因果推理关系。这就是Judea peal提出的explain away问题(Even if two hidden causes are independent in the prior, they can become dependent when we observe an effect that they can both influence),在前面的博文《目标检测(ObjectDetection)原理与实现(三)》也解释了这个问题,如果这个例子没有解释清楚,可以看下前面的例子。
对于无向图模型的条件独立就要简单一些,是从图论的可达性(reachability)考虑,也可从图的马尔科夫性入手,如(图五)所示:
(图五)
(图五)是个标准的隐马尔科夫模型(HMM),当给定X2时,就相当于在X2除切了一刀,在X2前后之间的变量都相互独立。独立就可以分解了,比如条件概率独立公式:P(A,B|C)=P(A|C)*P(B|C),团块兼容函数也是如此。如果X1-X5我们都给定,那这个模型分解的团块都是相似的,每个图块都可以用一个通用的标记来表示,因此图模型里又提了一种盘子表示法(plate notation),如(图六)所示:
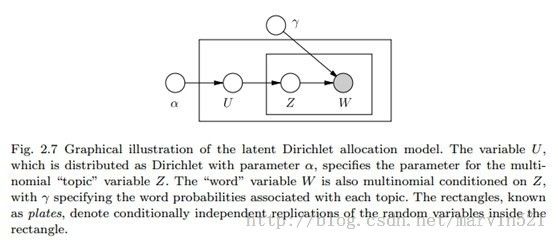
(图六)
(图六)不是表示的HMM的盘子模型,而是LDA模型的盘子模型,只是让大家了解一下通用分解模版的表示方法,其实很多时候这个表示方法反而不是那么清晰,南加州大学有一个做机器学习的博士生就在吐槽这个表示方法,有兴趣的可以去看看(链接)。今天算是了解一下概率图模型的基本定义和两个分解公式,这两个分解公式只是给出了图模型不好求概率的一个解决方法的切入点,下节就来学习一下概率图模型如何通过分解来进行边缘概率推理求解。
参考文献:
[1] Graphical models, exponential families, and variational inference. Martin Wain wright and Michael Jordan
[2] Probabilistic Graphical Models. Daphne Koller
转载请注明来源:http://blog.csdn.net/marvin521/article/details/10692153