Machine Learning by Andrew Ng --- Anomaly Detection and Recommender systems
In anomaly detection problems,every features corresponding to one formula of Gaussian distribution.
To start anomaly detection,the steps you should do are the fellows:
- Using all the examples of each feature to learn the correspond mu and sigma.
- Then selecting the epsilon with F1 scores.
- Something more important already show in the lecture notes.
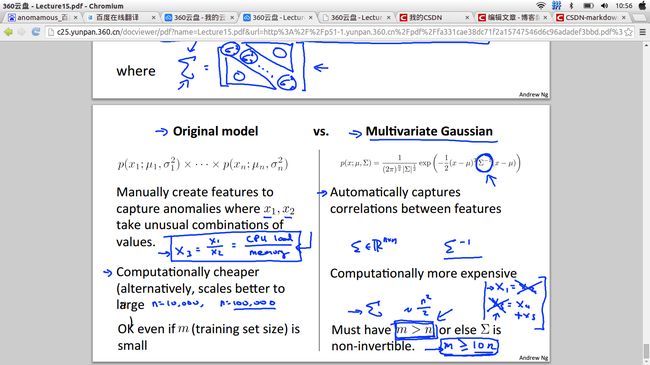
Then Multiplicative every Gaussian distribution’s formula ,Using the final formula to detect the anomalous.But sometimes it does not fit well.So maybe you should change your way to get the final formula of your anomaly detection algorithm.the follow picture shows the formula:

These are the differences between Original model and Multiplicative Gaussian:
Let’s now talk about Recommender Systems:
I think that to deal with Recommender Systems problems,It is important to build a powerful mathmatical model.
for this exercise ,the follow picture shows the model(with unknow features),Which has two matrix represented movies’ and users’ features:
In order to deal with this kind of problem,we may recommended to use an algorithm named Collaborative filtering learning algorithm,the steps:
- Collaborative filtering cost function
- Collaborative filtering gradient
- Regularized cost function
- Regularized gradient
The picture below will help you( To follow the steps show on the exercise’s pdf is better):

Also show you how i finish this ,but do not copy it!:
id = find(R==1);%获取R==1的下标
J = (1/2) * sum(sum( (((X*Theta')-Y).*R ).^2)) + ((lambda/2) * sum(sum(Theta.^2)) )+ ((lambda/2) * sum(sum(X.^2)) );
for index1 = 1:num_users
%弄明白整个算法的过程,向量化就简单了。
idx1 = find(R(:,index1)==1);%获得第index1个用户评价了的电影列向量下标(参考ppt的电影与用户的关系的表格)
XT = X(idx1,:);%获取第index1个用户评价过的每个电影的features
YT = Y(idx1,index1);%获得第index1个用户评价过的每个电影的得分
Theta_grad(index1,:) = ((Theta(index1,:) * XT') - YT' ) * XT + lambda*Theta(index1,:);%向量化求解
end
for index2 = 1:num_movies
idx2 = find(R(index2,:)==1);%获得一个用户列表下标(所有评价过第index2部电影的用户)
ThetaT = Theta(idx2,:);%获得评价过第index2部电影的用户featrues
YT = Y(index2,idx2);%获得第index2部电影被所有评价过该电影的用户给的得分
X_grad(index2,:) = ( X(index2,:) * ThetaT' - YT ) * ThetaT + lambda*X(index2,:); %向量化求解
end