IBM FileNet P8 高效实现企业海量数据的查询
IBM FileNet P8 是一个产品系列,有若干个组件组成。主要组件有 ContentEngine,简称 CE,主要用于数据的储存和管理;ContentSearchEngine,简称 CSE,主要用于把存储在 CE 的数据做全文检索;ApplicationEngine,简称 AE,是给终端客户使用的,用于展示存储在 CE 里面的数据;ProcessEngine,简称 PE,主要用户业务流程的管理。FileNet P8 有不同的版本,主要版本有 3.5,4.0,4.5 和在 2010 年 11 月份发本的最新版本 5.0。在本文中,FileNet P8 ContentEngine 5.0,我们简称 CE5.0,FileNet P8 ContentSearchEngine 5.0,我们简称 CSE5.0。
CE5.0 和 CSE5.0 在全文检索方面的新特性
CE5.0 增加了对 CSE 的新特性:Multiple Verity Domain Configuration (VDC)。CE5.0 允许在单个 P8 Domain 中配置多个 VDC:
- 不需要对原有的配置进行任何修改和升级
- 一个 VDC 可以使用于多个 ObjectStore
- 现有的索引数据可以在不同的 VDC 间转移
- 在同一个 P8 Domain 中不能混合使用不同的 CSE 版本
回页首
CSE5.0 配置的更改
由于 CE5.0 开始支持多个 Autonomy K2(Verity) 域,可以为每个 ObjectStore 配置 Autonomy K2 域,和先前的版本相比,在 Domain 和 ObjectStore 上面的配置都发生了更改。
在 P8 Domain Level 上配置的更改
在 CE5.0 中,在 Domain 中增加了新的 VerityDomainConfigurations 属性,此属性包含在此 Domain 中创建的 Autonomy K2 配置集合,我们可以为每一个 ObjectStore 创建一个 Autonomy K2 域。而在 CE3.5,CE4.0 和 CE4.5 中,我们只能创建一个 Autonomy K2 域,并且所有的 ObjectStore 共享这个域。
另外一个变化是 CE5.0 中,已经不在使用 VerityServerConfiguration 类的 VerityBrokerNames 属性,在缺省情况下,Content Engine 现在将发现由 Autonomy K2 配置的可用代理,并且将搜索请求发送给这些代理。
图 1. CE5.0 Domain 中的 VerityDomainConfigurations 属性
我们可以在 CE5.0 上创建多个 VerityDomianConfiguration。
图 2. CE5.0 之前版本中 Domain 中的 VerityDomainConfiguration 属性

在 CE4.0.1,CE4.5.0 和 CE4.5.1 上,我们只能创建一个 VerityDomianConfiguration。
图 3. CE5.0 Domain 中的 VerityServerConfiguration 属性
图 4. CE5.0 之前版本 Domain 中的 VerityServerConfiguration 属性
在 ObjectStore Level 上配置的更改
在 CE5.0 中,我们需要为每个 ObjectStore 分配 Autonomy K2 域,而在 CE5.0 之前的版本中,所有的 ObjectStore 只能共享使用指定在 Domain 类中 VerityDomainConfiguration 属性中的一个 Autonomy K2 域。
另外一个变化是,在 CE5.0 中,我们新增加了对 Cascade 的支持,我们将在另外一边文章中作详细介绍。
图 5. CE5.0 中为每个 ObjectStore 分配 Autonomy K2 域

图 6. CE5.0 之前的版本中,不需要为每个 ObjectStore 指定 Autonomy K2 域
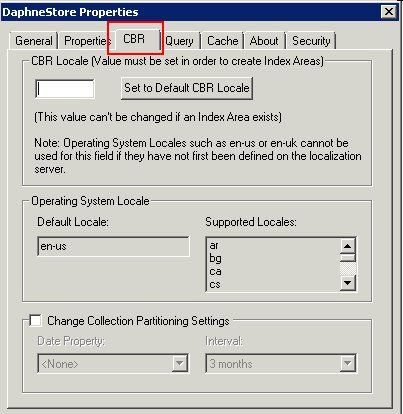
图 7. CE5.0 中支持新的搜索引擎 Cascade
回页首
从企业海量数据里得到最佳的查询结果
FileNet P8 ContentEngine 组件采用 Java 2 Enterprise Edition 架构,部署在中间件上 , 支持的中间件有 WebSphere,WebLogic 和 JBoss,具有很强的可靠性和可扩展性。CE 被设计用来存储和管理企业的海量数据,CE 把数据文件元数据存储在数据库里面,支持的数据库有 DB2,Oracle 和 SqlServer,能够存储的记录数根据数据库而定;CE 把具体的数据文件内容存储在磁盘文件系统或第三方存储里,比如 IBM Image Services,IBM Tivoli Storage Mangager,EMC Centera,NetApp SnapLock 和 Hitachi Content Platform,存储内容大小根据磁盘文件或第三方存储空间而定。
企业需要得到准确的数据来帮助做决策,通过使用合适的查询语句能帮助企业从海量数据里得到准确的查询结果。下面我们讨论在各种不同的查询条件下,如何使用合适的查询语句来快速准确得到企业所需要的数据。
查询语句介绍
ContentEngine 支持的查询分为两类:
第一类是关系查询 [relational queries],这类查询遵循 SQL Server 查询语法,只能对文档的属性 [object properties] 进行查询,不需要安装配置 Content Engine 的搜索引擎。
第二类是全文本搜索查询 [content-based retrieval queries],可以对文档的内容和属性 [object content and properties] 进行查询,需要安装和配置搜索引擎。在 FileNet P8 5.0 中,使用 Autonomy K2 技术进行全文本搜索的 Content Engine 组件称为 IBM Legacy Content Search Engine,使用 Cascade 技术进行全文本搜索的 Content Engine 组件称为 IBM Content Search Engine。
在全文本搜索查询方面,本文重点介绍基于 Autonomy K2 的查询语法。
关于 Autonomy K2 的安装和配置,请参照文章 IBM FileNet P8 基于内容的全文检索的配置和应用实例,第 1 部分。
关系查询
关系查询 [relational queries] 只能查询文档的属性,在查询时 Content Engine 把查询语句转化为数据库能够识别的语句,在 FileNet P8 5.0 中,支持的数据库有 SqlServer, DB2 和 Oracle。
(1)查询语法
SELECT[DISTINCT| ALL] [TOP<integer>] <property_spec> [ [AS] <entity_name> ]
FROM<class_ident> [ [AS] <class_alias> ] [ WITHINCLUDESUBCLASSES|EXCLUDESUBCLASSES)]
[WHERE<search_condition>] [ORADE BY <orderby> { ',' <orderby> } ]
|
根据实际环境调整,例如:SELECT d.[DocumentTitle], d.[From], d.[Id] FROM Document d WHERE d.[Creator] = "jsmith"
(2)不同类型的属性支持的操作
在 ContentEngine,我们可以定义不同类型的属性,在这里,我们简单介绍一下属性,类和文档即类实例之间的关系,在 ContentEngine 中,我们可以定义不同类型的属性,把这些属性添加到类中,然后我们用类创建实例即文档,在文档中给属性赋不同的值。不同的属性,我们支持不同的查询操作,下面表格罗列了不同属性所支持的操作。
- Binary: 不能对 Binary 类型的属性进行查询
- Boolean: '=' | '<>' | IS [NOT] NULL
- DateTime: '=' | '<>' | '<' | '>' | '<=' | '>=' | IS [NOT] NULL
- Float: '=' | '<>' | '<' | '>' | '<=' | '>=' | IS [NOT] NULL
- ID: '=' | '<>' | '<' | '>' | '<=' | '>=' | IS [NOT] NULL
- Integer: '=' | '<>' '<' | '>' | '<=' | '>=' | IS [NOT] NULL
- Object: '=' | '<>' | IS [NOT] NULL
- String: '=' | '<>' '<' | '>' | '<=' | '>=' | LIKE | IS [NOT] NULL
查找 String 类型属性 Creator 等于 keyword1 的文档:
SELECT d.[DocumentTitle], d.[From], d.[Id] FROM Document d WHERE d.[Creator] ="keyword1" |
查找 Integer 类型属性 Age 大于 keyword1 的文档:
SELECT d.[DocumentTitle], d.[From], d.[Id] FROM Document d WHERE d.[Age] >keyword1 |
查找 Float 类型属性 ContentSize 大于 keyword1 的文档,在使用 Float 属性查询时,查询的关键字一定要包含小数点,比如我们不能用 d.[ContentSize] >3 , 而应该用 d.[ContentSize] >3.0 ,如下:
SELECT d.[DocumentTitle], d.[From], d.[Id] FROM Document d WHERE d.[ContentSize] >keyword1 |
(3)对 Folder 的操作
在查询时,我们有时候只需要查询特定 Folder 下面的文档,这时我们可以在查询语句里面指定特定的 Folder,而不是在所有的 Folder 里面查询,这样会极大的提高查询效率。
查找 String 类型属性 Creator 等于 keyword1 并且在 /folder1/subfolder1 的文档:
SELECT d.[DocumentTitle], d.[From], d.[Id] FROM Document d WHERE d.[Creator] ="keyword1" and d.This INSUBFOLDER ‘ /folder/subfolder1 ’ |
(4)对 IsClass 的操作
在查询时,我们有时候只需要查询特定 Class 的实例即文档,这时我们可以在查询语句里面指定特定的 Class,这样能得到更加准确的查询结果,而不是从大量的查询结果里面筛选我们需要的数据。
查找 String 类型属性 Creator 等于 keyword1 并且 Class 是 subClass1 和 subClass2 的文档:
SELECT d.[DocumentTitle], d.[From], d.[Id] FROM Document d WHERE d.[Creator] ="keyword1" and (IsClass(d,subClass1) or IsClass(d,subClass2)) |
(5)对 IsOfClass 的操作
在查询时,我们有时候只需要查询特定 Class 和它下面所有子类的实例即文档,和 IsClass 比较起来,IsOfClass 包含了所有的子类。
查找 String 类型属性 Creator 等于 keyword1 并且 Class 不是 subClass1 和它的子类的文档:
SELECT d.[DocumentTitle], d.[From], d.[Id] FROM Document d WHERE d.[Creator] ="keyword1" and NOT(IsOfClass(d,subClass1)) |
(6)对 Include/Exclude SubClasses 的操作
INCLUDESUBCLASSES 和 EXCLUDESUBCLASSES 一般和 IsClass 一起使用,INCLUDESUBCLASSES 是默认的。
下面的两个查询语句是等效的,查找 String 类型属性 Creator 等于 keyword1 并且 Class 是 Document 或者它的子类的文档:
SELECT d.[DocumentTitle],d.[From],d.[Id] FROM WITH INCLUDESUBCLASSES Document d WHERE d.[Creator] ="keyword1" SELECT d.[DocumentTitle], d.[From], d.[Id] FROM Document d WHERE d.[Creator] ="keyword1" |
查找 String 类型属性 Creator 等于 keyword1 并且 Class 是 Document 但不是它的子类的文档:
SELECT d.[DocumentTitle],d.[From],d.[Id] FROM WITH EXCLUDEDSUBCLASSES Document d WHERE d.[Creator] ="keyword1" |
(7)对 Object 的操作
在查询时,我们有时候需要查询满足特定条件的 Object 类型属性
查找 String 类型属性 Creator 等于 keyword1 并且 Class 不是 subClass1 和它的子类的文档:
SELECT f.this FROM Folder f WHERE Parent=OBJECT( ‘ /subFolder1 ’ ) |
(8)对 In 的操作
在下面三种情况下,我们可以用 In 来做查询:
1. 当属性的值为 ChoiceList 时,我们必须用 In,比如:
我们把一个 ChoiceList 给 String 类型的属性 workerSex,查找 workerSex 值为男性的文档如下:
SELECT d.[DocumentTitle], d.[From], d.[Id] FROM Document d WHERE d.[workerSex] in( ‘ male ’ ) |
2. 当查找的属性可以为多个值时,我们可以用 In,当然,这样的查询语句可以改写为用多个 Or, 但是用 In 更为简洁,比如:
查找 String 类型属性 Creator 为 user1,user2 或者 user3 的文档:
SELECT d.[DocumentTitle], d.[From], d.[Id] FROM Document d WHERE d.[Creator] in ( ‘ user1 ’ , ’ user2 ’ , ’ user3 ’ ) |
如果改用 Or 的话,查询语句如下:
SELECT d.[DocumentTitle], d.[From], d.[Id] FROM Document d WHERE d.[Creator]= ‘ user1 ’ or d.[Creator]= ‘ user2 ’ or d.[Creator]= ‘ user3 ’ |
3. 当查找的属性值在另外一个查询语句里时,我们可以用 In,比如:
我们的查询涉及到两个类,一个是 Document,另外一个是 Worker, 我们要查找 Document 的文档,这些文档的 Creator 属性值为 Worker 文档中 Creator 的值,这些 Worker 文档中 workerAge 的属性值为 30,查询语句如下:
SELECT d.[DocumentTitle], d.[From], d.[Id] FROM Document d WHERE d.[Creator] in (SELECT [Creator] FROM Worker WHERE workerAge=30) |
(9)对 Object 的操作
在查询时,我们有时候需要查询满足特定条件的 Object 类型属性
查找 String 类型属性 Creator 等于 keyword1 并且 Class 不是 subClass1 和它的子类的文档:
SELECT f.this FROM Folder f WHERE Parent=OBJECT( ‘ /subFolder1 ’ ) |
(10)对 Satisfies 的操作
在查询时,有时候需要查询的属性是一个集合,比如属性 ExternalReplicaIdentities, AuditedEvents, Containers 等等,这时我们需要用 Satisfies 来做查询
查找 ExternalReplica 在 ID 为 {C51A1FC9-9905-4CE8-974F-945DF7B104C9} 的 External Repository 的所有文档:
SELECT d.this FROM Document d WHERE ExternalReplicaIdentities SATISFIES
(ExternalRepository=OBJECT({C51A1FC9-9905-4CE8-974F-945DF7B104C9})
|
全文本搜索查询
全文本搜索查询 [content-based retrieval queries] 可以查询文档的内容和属性,在本文中,我们讲解的查询语法适用于 IBM Legacy Content Search Engine[Verity K2]。
全文本搜索查询用 CONTRAINS 或者 FREETEXT 来描述要查找的内容,两者的区别在于:
FREETEXT 只能查询所有的 Content 和 CBR-enabled 的属性,而 CONTRAINS 可以对单独一个属性进行查询。
FREETEXT 的第一个参数只能是 “*” 或者 “Content”,比如 FREETEXT(d.*,”test”),不可以写成 FREETEXT(d.DocumentTitle,”test”),而 CONTRAINS 可以,比如 CONTRAINS(d.DocumentTitle,”test”)。
CONTAINS 操作是通过 Verity Simple Query Processor 来完成的,FREETEXT 操作是通过 Verity Free Text Processor 来完成的。在查询结果当中,ElementSequenceNumber=0,表示查询到的内容是文挡内容,ElementSequenceNumber=-1 表示查询到的内容是文挡属性。
下面以 CONTAINS 为例,列举经常用到的 CBR 查询语句。
查找文挡内容或者字符型属性里包含 keyword1 关键字的所有文挡:
SELECT d.This, d. DocumentTitle,v.* FROM Document d INNER JOIN VerityContentSearch v ON v.QueriedObject = d.This WHERE CONTAINS(v.Content, 'keyword1') |
查找文挡内容或者字符型属性里包含 keyword1 关键字并且在 /FolderName 里面的所有文挡:
SELECT d.This, d. DocumentTitle,v.* FROM Document d INNER JOIN VerityContentSearch v ON v.QueriedObject = d.This WHERE CONTAINS(v.Content, 'keyword1') AND d.This INSUBFOLDER '/FolderName' |
查找文挡内容或者字符型属性里包含 keyword1 并且包含 keyword2 关键字的所有文挡:
SELECT d.This, d. DocumentTitle,v.* FROM Document d INNER JOIN VerityContentSearch v ON v.QueriedObject = d.This WHERE CONTAINS(v.Content,' keyword1 <AND> keyword2') |
查找文挡内容或者字符型属性里包含 keyword1 或者包含 keyword2 关键字的所有文挡:
SELECT d.This, d. DocumentTitle,v.* FROM Document d INNER JOIN VerityContentSearch v ON v.QueriedObject = d.This WHERE CONTAINS(v.Content,' keyword1 <OR> keyword2') |
查找文挡内容或者字符型属性里包含 keyword1 和 keyword2 在一起的所有文挡(可以查找到包含 keyword1 keyword2 或者 keyword2 keyword1 的内容):
SELECT d.This, d. DocumentTitle,v.* FROM Document d INNER JOIN VerityContentSearch v ON v.QueriedObject = d.This WHERE CONTAINS(v.Content, 'keyword1 <NEAR> keyword2 ') |
查找文挡内容或者字符型属性里包含只有 keyword1 没有 keyword2 的所有文挡(可以查找到包含 keyword1 non-keyword2 或者 non-keyword2 keyword1 的内容):
SELECT d.This, d. DocumentTitle, v.* FROM Document d INNER JOIN VerityContentSearch v ON v.QueriedObject = d.This WHERE CONTAINS(v.Content, ' keyword1 <NOT> keyword2') |
如果文挡内容是 XML,可以用下面专门针对 XML 的 CBR 查询语句:
如果 XML 内容如下:
<?xml version="1.0" ?> - <Texts> - <Text Heading=" keyword2 to search for"> <Numerical entry=" keyword1 "> keyword2 </Numerical> <Textual entry="Entry">The entry is blocked</Textual> - <SubHeading> - <entries> <Entry> keyword1 </Entry> <Entry2>12345</Entry2> <Entry3>These keyword1 - 1234 - are sequential</Entry3> </entries> </SubHeading> <Head>Headed</Head> </Text> <Some More="More" More2="Even More Text" /> </Texts> |
查找 Text 元素里包含 keyword1 的所有文挡,keyword1 可以是 Text 元素的子元素名称或者是元素的内容:
SELECT d.This, d. DocumentTitle,v.* FROM Document d INNER JOIN VerityContentSearch v ON v.QueriedObject = d.This WHERE CONTAINS(v.Content, ' keyword1 <IN> Text') |
查找 Entry 元素里包含 keyword1 的所有文挡,由于 Entry 元素没有子元素,所以 keyword1 只能是 Entry 元素的内容:
SELECT d.This, d. DocumentTitle, v.* FROM Document d INNER JOIN VerityContentSearch v ON v.QueriedObject = d.This WHERE CONTAINS(v.Content, ' keyword1 <IN> Entry') |
查找 Text 元素里包含 keyword1(keyword1 可以是 Text 元素的子元素名称或者是元素的内容),并且 Text 元素的属性 Heading 包含 keyword2 的所有文挡:
SELECT d.This, d. DocumentTitle, v.* FROM Document d INNER JOIN VerityContentSearch v ON v.QueriedObject = d.This WHERE CONTAINS(v.Content, ' keyword1 <IN> Text <WHEN> (Heading <CONTAINS> " keyword2")') |
查找 Text 元素的属性 Heading 包含 keyword2 的所有文挡,对 Text 元素的子元素和内容没有要求:
SELECT d.This, d. DocumentTitle,v.* FROM Document d INNER JOIN VerityContentSearch v ON v.QueriedObject = d.This WHERE CONTAINS(v.Content, '* <IN> Text <WHEN> (Heading <CONTAINS> " keyword2")') |
查找 Numerical 元素的内容包含 keyword2,并且 Numerical 元素的属性 entry 的值等于 keyword1 的所有文挡:
SELECT d.This, d. DocumentTitle,v.* FROM Document d INNER JOIN VerityContentSearch v ON v.QueriedObject = d.This WHERE CONTAINS(v.Content, ' keyword2 <IN> Numerical <WHEN> ( entry = " keyword1 ")') |
回页首
海量数据查询 Tuning
P8 参数优化参考
表 1. 根据实际环境调整如下参数能够适当提升内容查询性能
| 参数名称 | 描述 |
|---|---|
| Thread count | 定义处理索引请求的线程数量,对于拥有多个 CPU 或者 CSE 分布式环境,可以适当的增加线程数量来达到提高索引处理性能的目的,通常一个 CPU 可以设置两个线程。 |
| Optimization Interval | 定义文档、批注、文件夹等批量数 |
| Max Batch Size | 定义处理索引的一个批量最大数,系统默认为 8000. IBM 性能测试实验室建议针对小文档并且是英文编码的使用批量数为 4000,而对于大文档且是 unicode 编码的设置为 1000 为佳。 |
| Max Objects per Collection | 定义内容引擎集合数量。实验室建议保持默认设置 |
| Lease Duration | 定义索引处理请求的超时时间,单位为秒,如果索引处理时间超过该设置,系统会放弃执行或重新执行。建议默认。 |
| Dispatcher Wait Interval | 定义分发器等待时间(秒),有效值在 5 秒到 600 秒之间。如果该值设置太小,某些内容可能还没有及时写入内容存储,索引引擎就试图处理下一个请求。 |
CSE 参数优化
在 P8 企业管理器中可以设置关于 CSE 处理并发请求的异步线程处理数量,IBM 实验室建议将此值设置为 CPU 的两倍,当请求超过设置数量的时候,该请求就会被放入队列中等待处理。
优化 Collection
全文检索的数据文件都存储在 Collection 里面,通过下面的命令可以优化 Collection,加快查询的速度。
mkvdk -locale englishv -verbose -optimize squeeze -collection <fullpath and name> mkvdk -locale englishv -verbose -optimize maxmerge -collection <fullpath and name> mkvdk -locale englishv -verbose -optimize spanword -collection <fullpath and name> mkvdk -locale englishv -verbose -optimize maxclean -collection <fullpath and name> |
Stop Words 优化
对于大小写敏感的词语,如果显示的将大部分涉及的词语加入到 stop words 列表里可以提高性能甚至达到 30%。 例如对于“the”可能有三种形式:”THE”,”The”,”the”。