SQL查询知识积累
--select COUNT(*) as 职工人数 from 职工;
--select COUNT(*) as 个数 from 职工 where 性别='男' and 工资>1500;
--select COUNT(仓库号) from 仓库;
--select COUNT(distinct(仓库号)) from 仓库;
--sum函数的应用
--select sum(工资) from 职工;
--select SUM(工资) as wh1仓库工资和 from 职工 where 仓库号='wh1';
--select SUM(工资) as 北京地区的工资 from 职工 where 仓库号 in (select 仓库号 from 仓库 where 城市='北京')
--select COUNT(*) as 职工人数, SUM(工资) as wh2仓库工资和 from 职工 where 仓库号='wh1';
--select SUM(工资)/COUNT(*) as 平均工资 from 职工 where 仓库号='wh1' and 工资>1500;
--select SUM(工资) as 工资和, COUNT(*) as 总人数 from 职工 where 工资>(select AVG(工资) from 职工);
--max和min聚合函数的应用
--select MAX(工资) as 最大工资, MIN(工资) as 最小工资 from 职工;
--select MAX(工资) as wh1仓库的最大工资, MIN(工资) as wh1仓库的最小工资, (MAX(工资)-MIN(工资)) as 最大工资和最小工资之差 from
--职工 where 仓库号='wh1'
--select (MAX(工资) - MIN(工资)) as 工资差, 工资评语=
-- case
-- when (MAX(工资) - MIN(工资))>300 then '工资差别大'
-- when (MAX(工资) - MIN(工资))<=300 then '工资差别小'
-- end
--from 职工;
--select * from 职工 where 工资>(select MAX(工资) from 职工 where 仓库号='wh1')
--avg聚合函数的应用
--select COUNT(*) as 仓库个数, MAX(面积) as 最大面积, MIN(面积) as 最小面积, AVG(面积) as 平均面积
--from 仓库;
--select * from 仓库 where 面积>(select AVG(面积) from 仓库);
--select AVG(工资) from 职工 where 工资!=(select MAX(工资) from 职工);
--select AVG(工资) from 职工 where 工资 not in((select MAX(工资) from 职工),(select MIN(工资) from 职工));
--select *, (select avg(工资) from 职工) as 平均工资 from 职工
--select *, 工资-(select avg(工资) from 职工) as 工资与平均工资之差 from 职工
--select * from 仓库 where 面积=(select MAX(面积) from 仓库);
--select * from 职工 where 仓库号 in(select 仓库号 from 仓库 where 面积=(select MAX(面积) from 仓库));
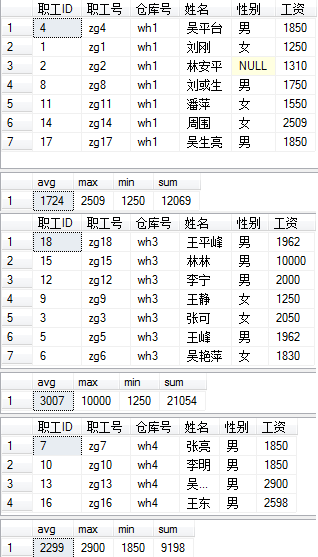
case
when ABS(工资-(select AVG(工资) from 职工)) >300 then '工资差额大'
when ABS(工资-(select AVG(工资) from 职工)) >=100 then '工资差额一般'
when ABS(工资-(select AVG(工资) from 职工)) <100 then '工资差额小'
end
from 职工
效果图:
case
when 仓库号='wh1' then (select AVG(工资) from 职工 where 仓库号='wh1')
when 仓库号='wh2' then (select AVG(工资) from 职工 where 仓库号='wh2')
when 仓库号='wh3' then (select AVG(工资) from 职工 where 仓库号='wh3')
when 仓库号='wh4' then (select AVG(工资) from 职工 where 仓库号='wh4')
end
from 职工
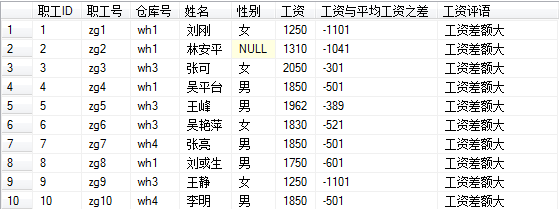
select *, 不同仓库的平均信息=
case
when 仓库号='wh1' then (select AVG(工资) from 职工 where 仓库号='wh1')
when 仓库号='wh2' then (select AVG(工资) from 职工 where 仓库号='wh2')
when 仓库号='wh3' then (select AVG(工资) from 职工 where 仓库号='wh3')
when 仓库号='wh4' then (select AVG(工资) from 职工 where 仓库号='wh4')
end,
工资与其对应的仓库的平均工资之差=
case
when 仓库号='wh1' then 工资-(select AVG(工资) from 职工 where 仓库号='wh1')
when 仓库号='wh2' then 工资-(select AVG(工资) from 职工 where 仓库号='wh2')
when 仓库号='wh3' then 工资-(select AVG(工资) from 职工 where 仓库号='wh3')
when 仓库号='wh4' then 工资-(select AVG(工资) from 职工 where 仓库号='wh4')
end
from 职工
效果图:
select *,不同仓库的最大工资 =
case
when 仓库号='wh1' then (select MAX(工资) from 职工 where 仓库号='wh1')
when 仓库号='wh2' then (select MAX(工资) from 职工 where 仓库号='wh2')
when 仓库号='wh3' then (select MAX(工资) from 职工 where 仓库号='wh3')
when 仓库号='wh4' then (select MAX(工资) from 职工 where 仓库号='wh4')
end
from 职工
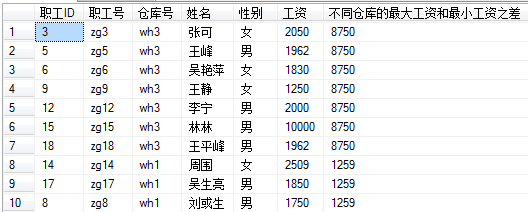
不同仓库的最大工资和最小工资之差,并进行排序
select *,不同仓库的最大工资和最小工资之差 =
case
when 仓库号='wh1' then (select (MAX(工资)-MIN(工资)) from 职工 where 仓库号='wh1')
when 仓库号='wh2' then (select (MAX(工资)-MIN(工资)) from 职工 where 仓库号='wh2')
when 仓库号='wh3' then (select (MAX(工资)-MIN(工资)) from 职工 where 仓库号='wh3')
when 仓库号='wh4' then (select (MAX(工资)-MIN(工资)) from 职工 where 仓库号='wh4')
end
from 职工 order by 不同仓库的最大工资和最小工资之差 desc
效果图:
select *, 实发工资=
case
when 工资>(select AVG(工资) from 职工) then 工资*0.90
when 工资=(select AVG(工资) from 职工) then 工资
when 工资<(select AVG(工资) from 职工) then 工资*1.1
end
from 职工 order by 实发工资 asc;

分组查询:
可以使用group by基于指定列的值将数据集合划分为多个分组,在分组查询中要注意条件的运用,如果是分组之前的条件用where,如果是
分组之后的条件用having
select 仓库号,AVG(工资) as 不同仓库的平均工资 from 职工 where 性别!='女' group by 仓库号
select 仓库号, AVG(工资) as 不同仓库的平均工资 from 职工 group by 仓库号 having AVG(工资)>1700;
select 仓库号, (MAX(工资)-MIN(工资)) as 不同仓库的最大工资和最小工资之差 from 职工
group by 仓库号 having (MAX(工资)-MIN(工资))>2000
select 仓库号, MAX(工资) as 不同仓库的最大工资, MIN(工资) as 不同仓库的最小工资, (MAX(工资)-MIN(工资)) as 不同仓库的最大工资和最小工资之差
from 职工 where 姓名 not like '%刘%'
group by 仓库号 having (MAX(工资)-MIN(工资))>2000
select 仓库号, AVG(工资) as 不同仓库的平均工资 from 职工 group by 仓库号
select 职工号, AVG(金额) as 不同职工的平均销售金额, MAX(金额) as 不同职工的最大销售金额,
MIN(金额) as 不同职工的最小销售金额, SUM(金额) as 不同职工的金额销售和 from 订购单 group by 职工号
select 仓库号, MAX(工资) as 不同仓库的最大工资, MIN(工资) as 不同仓库的最小工资,
(MAX(工资)-MIN(工资)) as 不同仓库的最大工资和最小工资之差 from 职工 group by 仓库号
多列组合分组查询
select 仓库号, 性别, AVG(工资) as 不同仓库的平均工资 from 职工 group by 仓库号,性别
select 仓库号, 性别, AVG(工资) as 不同仓库的平均工资 from 职工 where 性别 is not null and 工资>500
group by 仓库号,性别
select 仓库号, 性别, AVG(工资) as 不同仓库的平均工资 from 职工 where 性别 is not null
group by 仓库号,性别 having AVG(工资) > 1600;
all关键字在分组查询中的应用
在group by中使用all关键字,只有在SQL语句中带有where条件时,all关键字才有意义,使用all关键字后,查询结果将包括由group by 产生的所有数组,即某些组没有符合
查询条件的行也会显示
select 仓库号, MAX(工资) as 不同仓库的最大工资, MIN(工资) as 不同仓库的最小工资,
(MAX(工资)-MIN(工资)) as 不同仓库的最大工资和最小工资之差 from 职工 where 工资>1900
group by all 仓库号
select 仓库号, 性别, AVG(工资) as 职工的平均工资 from 职工 where 性别 is not null
group by all 仓库号,性别
cube关键字在分组查询中的应用
cube关键字的主要作用是自动对group by中列出的字段进行分组汇总计算,其结果为多维数据集,在group by中应用cube关键字,需要指定维度列和关键字with cube,
结果集将包含维度列中各值的所有可能组合以及这些维度值组合相匹配的基础行中的聚合值。
使用cube关键字显示不同仓库的仓库号、最大工资、最小工资、最大工资与最小工资之差信息。
select 仓库号, MAX(工资) as 不同仓库的最大工资, MIN(工资) as 不同仓库的最小工资,
(MAX(工资) - MIN(工资)) as 不同仓库的最大工资与最小工资之差
from 职工 group by 仓库号 with cube;
效果图:
如果不使用cube关键字,则在查询结果中不会出现第4条记录
rollup关键字在分组查询中的应用
如果要生成包含小计和合计的报表,则要使用rollup关键字,rollup关键字生成的结果类似于cube关键字生成的结果集,它们之间的区别在于:
cube生成的结果集显示了所选列中值的所有组合的聚合
rollup生成的结果集显示了所选列中值的某一层次结构的聚合,rollup关键字只对group by 列出的第一个分组字段进行汇总计算,如果group by含有两个字段,那么字段位置
不同,则返回的结果也不同。
select 仓库号,性别,AVG(工资) as 不同仓库的平均工资 from 职工 where 性别 is not null group by 仓库号,性别; select 仓库号,性别,AVG(工资) as 不同仓库的平均工资 from 职工 where 性别 is not null group by 仓库号,性别 with rollup;
效果图:

select 仓库号,MAX(工资) as 不同仓库的最大工资, MIN(工资) as 不同仓库的最小工资, (MAX(工资)-MIN(工资)) as 不同仓库的最大工资和最小工资之差 from 职工 group by 仓库号 order by (MAX(工资)-MIN(工资)) asc;
compute by查询的应用
select * from 职工 where 姓名 like '%平%' compute avg(工资), max(工资), min(工资), sum(工资), count(工资)

select * from 职工 order by 仓库号 compute avg(工资), max(工资), min(工资), sum(工资) by 仓库号