memcached简介
背景
memcached是一个高性能、分布式的内存对象缓存系统。memcached广泛应用在大负载高并发的网站上,是一种非常成熟的产品(称为一项技术也未尝不可)。像facebook,youtube,yahoo,sina,sohu,netease,豆瓣等网站均或多或少使用了该项产品。memcached在以用户为中心的网站上,表现尤其突出,例如sns,blog等web2.0应用的站点。这些站点一般来讲,特别注重用户体验,用户对服务器的响应速度要求很高,用户数据相对比较复杂、关连度比较高,需要经常对数据库进行更新和检索。
memcache是danga.com几个开源项目中的一个,最初是专门为livejournal.com站点而开发的,当时这个站点日pv达到了千万级,在使用过程中出现了很多的与负载和响应速度相关的问题,于是开发了这个项目,旨在改善网站当时的困境。memcache可以应对任意多个连接,使用非阻塞的网络IO。它的使用非常简单和方便,最常用的功能不超过5个方法。
memcache官方网站:
[url]http://www.danga.com/memcached[/url]。
特点
1、高性能无论哪一种数据库dbms(mysql,oracle,mssql,db2,Postgres等等),再怎么优化,最终也避不开与慢速的存储介质(硬盘、磁带)进行数据交换,但往往一旦涉及到了存储介质的io操作,存取性能就会急剧下降。memcached,顾名思义,它的全部操作自始至终都是在内存中进行的,所以存取数据的效率非常高。
当然,通常情况下,大型网站对于数据库的操作都会做优化。通常的手段有两种:
a、读写数据分离,采用主/辅库的方式,来分散数据库的压力,提高查询速度。
b、按照业务特点横向或者纵向分割数据库。简单来讲,就是大库变小库,大表变小表,来提高数据库访问的效率。一般来讲,一个数据库具有很多表或者一张表有N多的记录,都会明显的降低数据库的服务能力,比如mysql数据库单表记录达到2000万条左右(笔者以前的工作经验),性能会下降到几乎无法忍受。关于数据库的设计和优化,我们以后可以单独做一个专题,这里不做太多的研究。
数据库会在以下情况下会出现访问瓶颈:
a、事务操作
企业级的数据库(比如mysql的innodb模式)都支持事务操作。由于事务具有原子性,事务中涉及的数据表在运行过程中将会加锁。在这种情况下,访问这些表的数据会出现延迟。
b、数据更新
数据库中任何的表在数据更新过程中,同样会被加锁。在这种情况下,也会出现上面同样的结果。
memcached的操作基本上就不会存在以上情况(实际上也有加锁的情况,在后面再详细探讨),所以它的性能非常高。官方网站上对它的正式评价是very fast。事实上也是如此,相关的实验室测试对比结果,大家可以到网上搜索一下,比比皆是。
2、分布式
所谓分布式系统比较专业的解释是:
一种计算机硬件的配置方式和相应的功能配置方式。它是一种多处理器的计算机系统,各处理器通过互连网络构成统一的系统。系统采用分布式计算结构,即把原来系统内中央处理器处理的任务分散给相应的处理器,实现不同功能的各个处理器相互协调,共享系统的外设与软件。这样就加快了系统的处理速度,简化了主机的逻辑结构。
一种计算机硬件的配置方式和相应的功能配置方式。它是一种多处理器的计算机系统,各处理器通过互连网络构成统一的系统。系统采用分布式计算结构,即把原来系统内中央处理器处理的任务分散给相应的处理器,实现不同功能的各个处理器相互协调,共享系统的外设与软件。这样就加快了系统的处理速度,简化了主机的逻辑结构。
memcache的分布式特性主要表现在两个方面:
a.memcache客户端mc和服务器端ms可以单独安装在任何独立server上。
当然部署在同一台server上也没问题,甚至于一台机器上可以部署n个memcached。
b.memcache服务器端ms可以安装在任意数量的server上,提供并行存储和计算的能力。
这是分布式特性的本质体现。ms可以形成任意多台server组成的集群,为mc提供服务。
当然部署在同一台server上也没问题,甚至于一台机器上可以部署n个memcached。
b.memcache服务器端ms可以安装在任意数量的server上,提供并行存储和计算的能力。
这是分布式特性的本质体现。ms可以形成任意多台server组成的集群,为mc提供服务。
用途
1、提高系统的并发能力2、减轻数据库的负担
这两种用途其实非常容易理解。由于memcached高性能,所以可以同时服务于更多的连接,大大提高了系统的并发处理的能力。另外,memcached通常部署在业务逻辑层(前台应用)和存储层(主指数据库)之间,作为数据库和前台应用的数据缓冲,因此可以快速的响应前端的请求,减少对数据库的访问。
以下是一个memcached部署的逻辑示意图,其中mc是指memcached client,ms是指memcached server:
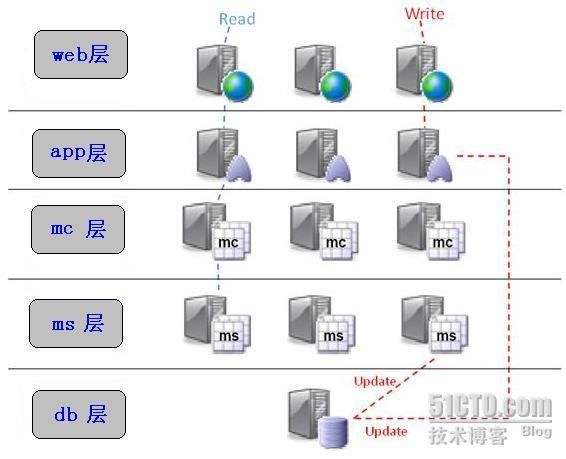
工作机制
Memcached 是以守护程序方式运行于一个或多个服务器中,随时接受客户端的连接操作,客户端可以由各种语言编写,目前已知的客户端 API 包括 Perl/PHP/Python/Ruby/Java/C#/C 等等。客户端首先与 Memcached 服务建立连接,然后存取对象。每个被存取的对象都有一个唯一的标识符 key,存取操作均通过这个 key 进行,保存的时候还可以设置有效期。保存在 Memcached 中的对象实际上是放置在内存中的,而不是在硬盘上。Memcached 进程运行之后,会预申请一块较大的内存空间,自己进行管理,用完之后再申请一块,而不是每次需要的时候去向操作系统申请。Memcached将对象保存在一个巨大的Hash表中,它还使用NewHash算法来管理Hash表,从而获得进一步的性能提升。所以当分配给Memcached的内存足够大的时候, Memcached的时间消耗基本上只是网络Socket连接了。
Memcached按照LRU方式调度数据。LRU是Least Recently Used的缩写,即最近最少使用页面置换算法,是为虚拟页式存储管理服务的。LRU算法在实际的工作环境中会与操作系统相关,比如32位的操作系统,最大的寻址空间是4G,如果当前内存的使用超过了这个限度,将被调出内存,内存中总维持最新最常用的数据。64位操作系统大大扩展了内存的寻址能力,所以现在很memcached服务都是运行在64位系统上。
Memcached按照LRU方式调度数据。LRU是Least Recently Used的缩写,即最近最少使用页面置换算法,是为虚拟页式存储管理服务的。LRU算法在实际的工作环境中会与操作系统相关,比如32位的操作系统,最大的寻址空间是4G,如果当前内存的使用超过了这个限度,将被调出内存,内存中总维持最新最常用的数据。64位操作系统大大扩展了内存的寻址能力,所以现在很memcached服务都是运行在64位系统上。