基于lucene的案例开发:Query查询
在Lucene索引的搜索过程中,构建Query对象是一个十分重要的过程。对于Query的理解,可以把它想象成数据库SQL查询语句中的where条件(当然Query的功能要比sql强大很多),在这篇博客中,我们将重点介绍几种常用的Query子类:QueryParser、 MultiFieldQueryParser、TermQuery 、PrefixQuery、 PhraseQuery、 WildcardQuery、
TermRangeQuery、 NumericRangeQuery、 BooleanQuery。
这篇博客稍微和前面的排版不同,先分别对几个类做简单介绍,然后在给出具体的demo程序,如若对其中的某些介绍不理解,可以先阅读后面的demo程序再看前面的介绍。
QueryParser
QueryParser主要用于对单个域搜索时创建查询query,QueryParser的构造方法需指定具体的域名和分词方法,lucene不同版本,创建的Query对象会略有不同,具体不同还请参照博客:关于QueryParser类前后修改。
MultiFieldQueryParser可以想象成QueryParser的升级版,QueryParser主要用于单个域的搜索,而MultiFieldQueryParser则用于多个域的搜索,其构造方法和具体使用和QueryParser类似。
TermQuery重要对一个Term(最小的索引块,包含一个field名和值),TermQuery可以用于对关键字域查询时Query的创建,比如分类、文档唯一ID等。
PrefixQuery前缀查询字符串的构建,其效果和“abc*”这种通配符使用WildcardQuery构建Query类似;PrefixQuery只需要前缀指定的若干个字符相同即可,如PrefixQuery(new Term("", "lu")),将会匹配lucene、luke等。
PhraseQuery短语搜索,它可以指定关键词之间的最大距离,如下面demo程序中,指定了“基于”“案例”这两个词之间最大的距离为2,一旦文档中,这两个词的具体大于2就不满足条件。
WildcardQuery通配符搜索,可以想象是PrefixQuery的升级版,WildcardQuery提供了更细的控制和更大的灵活行,lucene中有* ? 这两个通配符,*表示匹配任意多个字符,?表示匹配一个任意字符。如lu*e可以和lucene、luke匹配;lu?e可以和luke匹配,但和lucene却不匹配。
TermRangeQuery字符串范围搜索,在创建时一般有5个参数分别是 域名、域下限值、域上限值、是否包括下限、是否包括上限,这个和下面的NumericRangeQuery的参数含义相同。
NumericRangeQuery数字范围搜索,它针对不同的数据类型(int、float、double),提供的不同的方法,参数含义参照TermRangeQuery。
上面介绍的Query子类几乎都是针对单个域或多个域单个关键字的,那多个域不同关键字有该如何处理?多个Query对象又如何组成一个Query对象?这些BooleanQuery都可以实现,BooleanQuery可以嵌套非常复杂的查询,其和布尔运算类似,提供与(Occur.MUST)、或(Occur.SHOULD)、非(Occur.MUST_NOT)三种逻辑关系。
当然lucene中提供的Query子类还有很多,这里就只简单的介绍了几种比较常用的,剩下的如在以后的实际项目中遇到再做介绍学习。
Query测试demo
/**
*@Description: Query学习demo
*/
package com.lulei.lucene.study;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryparser.classic.MultiFieldQueryParser;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.BooleanClause.Occur;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.NumericRangeQuery;
import org.apache.lucene.search.PhraseQuery;
import org.apache.lucene.search.PrefixQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TermRangeQuery;
import org.apache.lucene.search.WildcardQuery;
import org.apache.lucene.util.Version;
public class QueryStudy {
public static void main(String[] args) throws Exception {
//Query过程中使用的分词器
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_43);
//搜索词
String keyValue = "基于lucene的案例开发";
// keyValue = "基于lucene的案例开发 更多内容请访问:http://blog.csdn.net/xiaojimanman/article/category/2841877";
//将搜索词进行下转义,如果搜索词中没有lucene中的特殊字符,可以不进行转义
String key = LuceneKey.escapeLuceneKey(keyValue);
//单个搜索域
String field = "content";
//多个搜索域
String []fields = {"name" , "content"};
Query query = null;
//对单个域构建查询语句
QueryParser parse = new QueryParser(Version.LUCENE_43, field, analyzer);
query = parse.parse(key);
System.out.println(QueryParser.class);
System.out.println(query.toString());
System.out.println("--------------------------------");
//对多个域创建查询语句
MultiFieldQueryParser parse1 = new MultiFieldQueryParser(Version.LUCENE_43, fields, analyzer);
query = parse1.parse(key);
System.out.println(MultiFieldQueryParser.class);
System.out.println(query.toString());
System.out.println("--------------------------------");
//词条搜索
query = new TermQuery(new Term(field, key));
System.out.println(query.getClass());
System.out.println(query.toString());
System.out.println("--------------------------------");
//前缀搜索
query = new PrefixQuery(new Term(field, key));
System.out.println(query.getClass());
System.out.println(query.toString());
System.out.println("--------------------------------");
//短语搜索
PhraseQuery query1 = new PhraseQuery();
//设置短语间允许的最大间隔
query1.setSlop(2);
query1.add(new Term("content", "基于"));
query1.add(new Term("content", "案例"));
System.out.println(query1.getClass());
System.out.println(query1.toString());
System.out.println("--------------------------------");
//通配符搜索
query = new WildcardQuery(new Term(field, "基于?"));
System.out.println(query.getClass());
System.out.println(query.toString());
System.out.println("--------------------------------");
//字符串范围搜索
query = TermRangeQuery.newStringRange(field, "abc", "azz", true, false);
System.out.println(query.getClass());
System.out.println(query.toString());
//int范围搜索
query = NumericRangeQuery.newIntRange("star", 0, 3, false, false);
System.out.println(query.getClass() + "\tint");
System.out.println(query.toString());
//float范围搜索
query = NumericRangeQuery.newFloatRange("star", 0.0f, 3.0f, false, false);
System.out.println(query.getClass() + "\tfloat");
System.out.println(query.toString());
//double范围搜索
query = NumericRangeQuery.newDoubleRange("star", 0.0, 3d, false, false);
System.out.println(query.getClass() + "\tdouble");
System.out.println(query.toString());
System.out.println("--------------------------------");
//BooleanQuery
BooleanQuery query2 = new BooleanQuery();
query2.add(new TermQuery(new Term("content", "基于")), Occur.SHOULD);
query2.add(new TermQuery(new Term("name", "lucene")), Occur.MUST);
query2.add(new TermQuery(new Term("star", "3")), Occur.MUST_NOT);
System.out.println(query2.getClass());
System.out.println(query2.toString());
System.out.println("--------------------------------");
}
}
上述demo程序的运行截图如下:
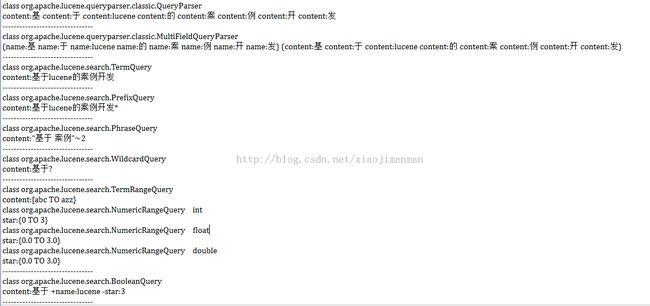
关于上述Query的意思以及查询索引得到的结果,这里就不再做介绍,如对其感兴趣可以自己按照前面的几篇博客,创建对应索引文件以及编写搜索程序。
ps:最近发现其他网站可能会对博客转载,上面并没有源链接,如想查看更多关于 基于lucene的案例开发 请点击这里。或访问网址http://blog.csdn.net/xiaojimanman/article/category/2841877